📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Offline Reinforcement Learning
Uni-RLHF is a comprehensive open-source system providing annotation tools, large-scale crowdsourced datasets, and modular baselines to standardize research on RLHF with diverse real-world human feedback.
Core Problem
Current RLHF research relies on synthetic feedback from scripted teachers rather than real humans, and lacks standardized tools for diverse feedback types (like visual or attribute-based guidance).
Why it matters:
- Synthetic labels from scripted teachers fail to capture human irrationality, bias, and cognitive inconsistency found in real-world applications
- Existing benchmarks assume infinite, unbiased expert feedback, ignoring the practical challenges of noisy crowdsourced data
- Lack of unified platforms forces researchers to build custom annotation tools for every new feedback type, slowing down progress
Concrete Example:
In autonomous driving (SMARTS), a hand-designed reward function might incentivize speed but neglect comfort. A scripted teacher simply optimizes this flawed function. In contrast, real humans notice unsafe merging behavior that the reward function misses, but collecting this feedback requires complex custom tools which Uni-RLHF provides.
Key Novelty
Universal RLHF Ecosystem (Platform + Data + Baselines)
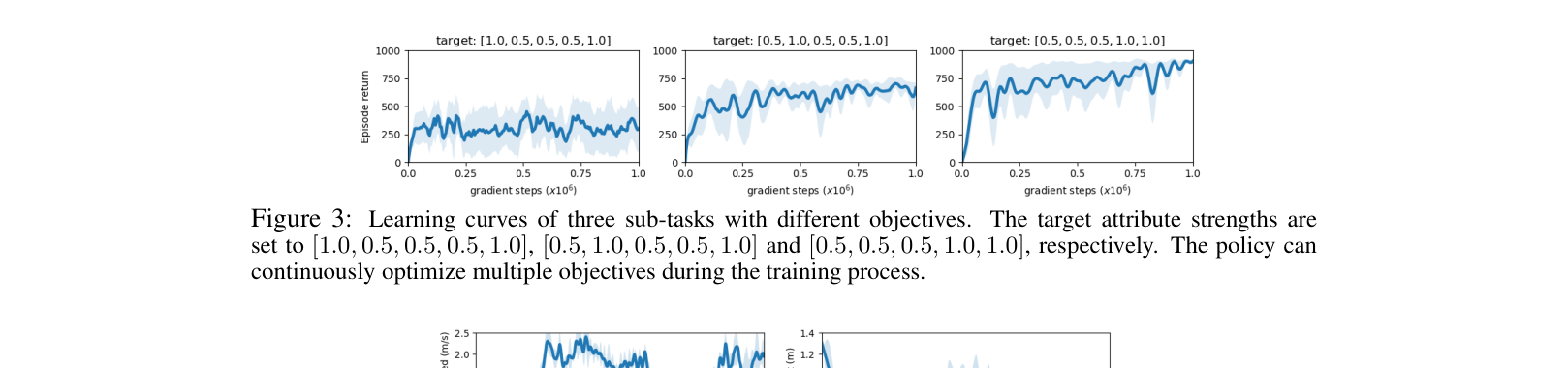
- Unified annotation interface supporting five distinct feedback types (comparative, attribute, evaluative, visual, keypoint) compatible with standard RL environments like Gym and DMControl
- Systematic crowdsourcing pipeline with 'ex-ante' filters (expert validation sets) to ensure label quality from non-expert workers
- Release of 30 reusable datasets (15 million steps) with real human labels, enabling offline RLHF benchmarking without collecting new data
Architecture
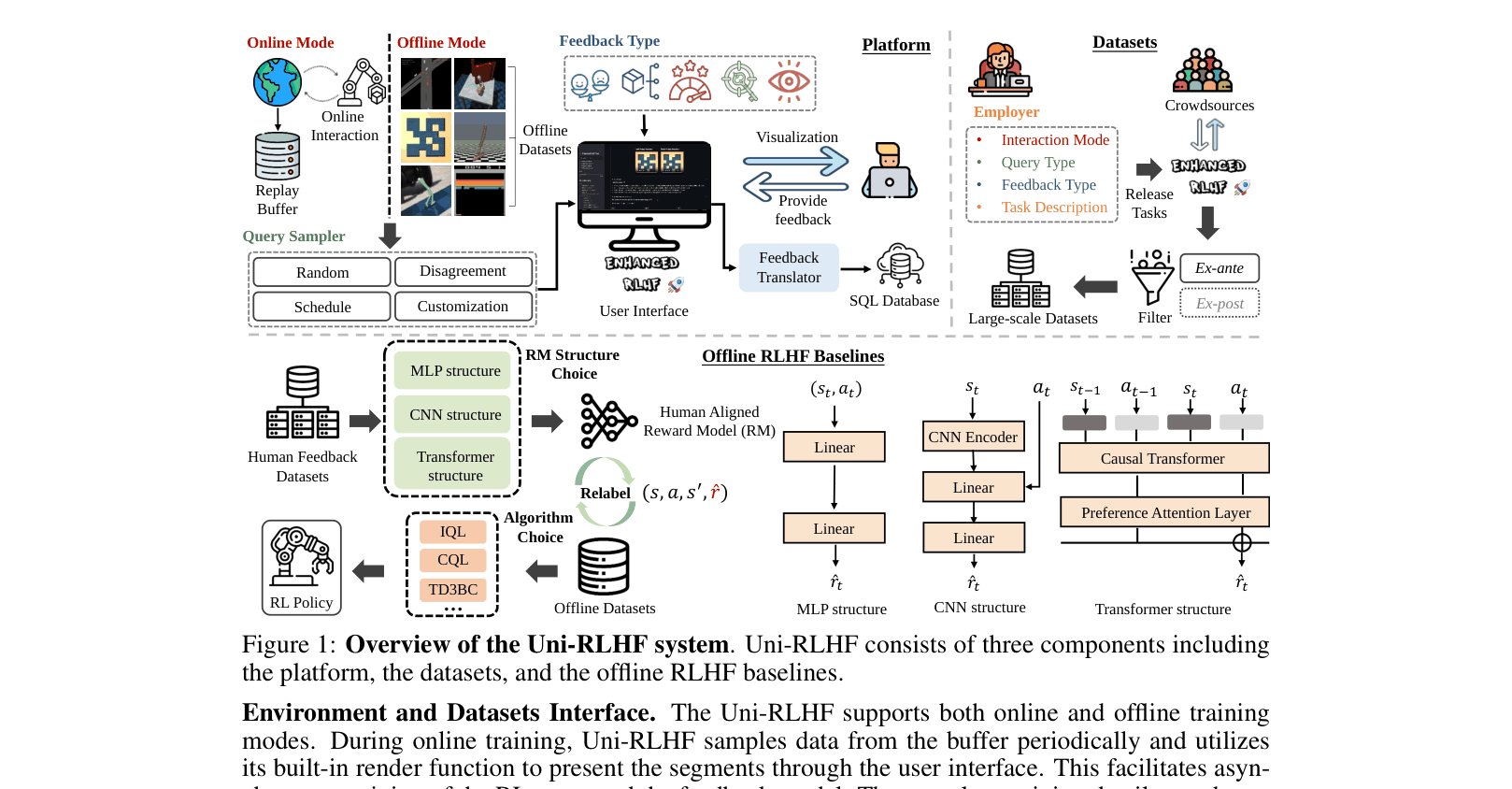
The complete Uni-RLHF system workflow, separated into three components: Platform, Datasets, and Offline RLHF Baselines.
Evaluation Highlights
- Offline RL policies trained on crowdsourced data (CS) achieve parity with or outperform oracle rewards on 5 Atari games (e.g., +3000 points on Qbert vs ST)
- IQL trained on human preferences (IQL-CS) matches oracle performance on complex D4RL locomotion tasks (e.g., Hopper-medium-replay: 95.11 CS vs 97.43 Oracle)
- Annotation pipeline with filters achieves 98% agreement with expert labels, validating the crowdsourcing methodology
Breakthrough Assessment
9/10
A foundational infrastructure contribution. By open-sourcing a versatile platform and 15M steps of real human data, it significantly lowers the barrier to entry for realistic RLHF research, moving the field away from synthetic proxies.