📝 Paper Summary
RLHF System Optimization
Distributed Training Infrastructure
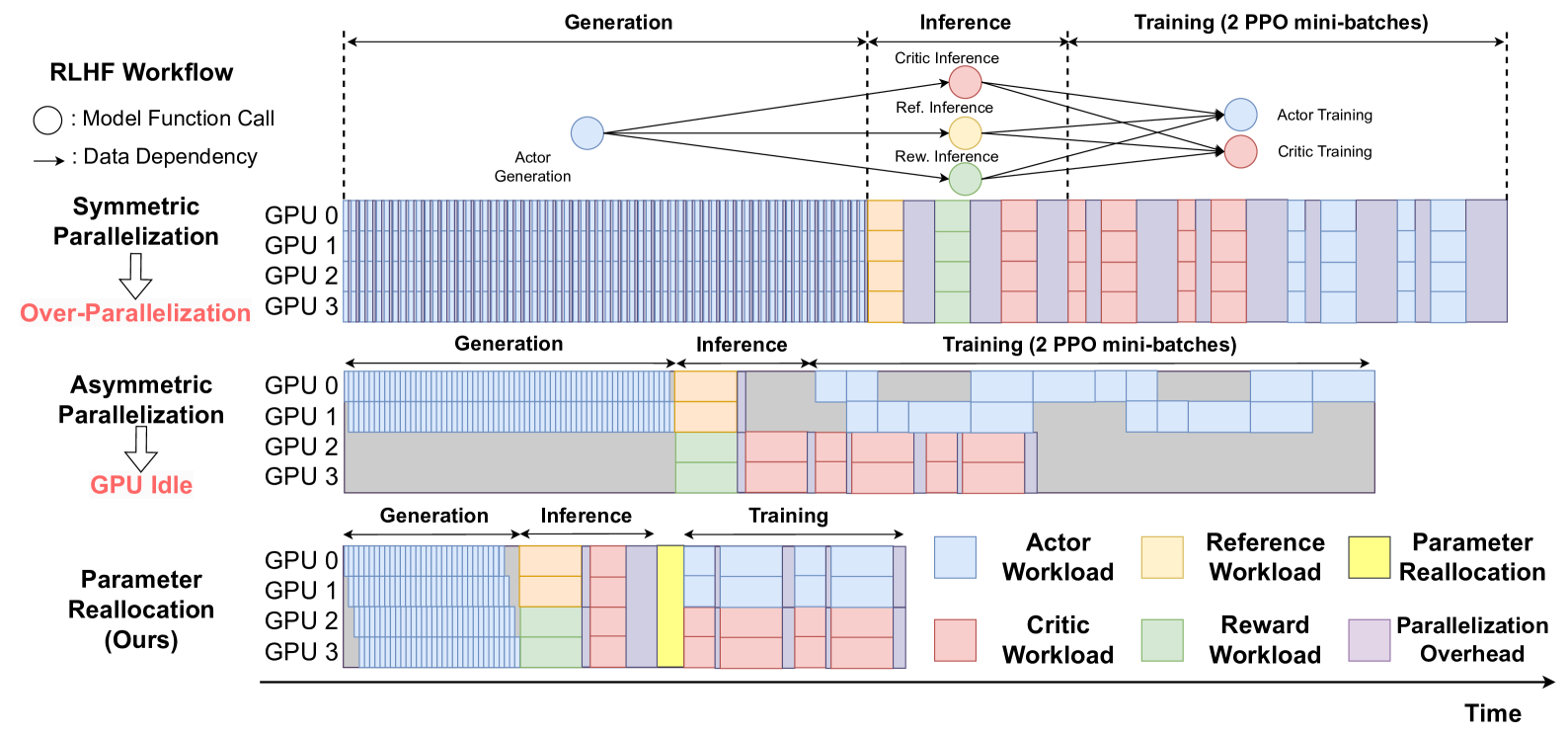
ReaL accelerates RLHF training by dynamically redistributing model parameters and assigning tailored parallelization strategies to each computation phase (generation, inference, training) rather than using a fixed static layout.
Core Problem
Standard RLHF training uses fixed parallelization strategies for all models (Actor, Critic, Reward), leading to either high communication overhead (over-parallelization) or low GPU utilization (due to task dependencies and idle hardware).
Why it matters:
- RLHF involves diverse computational workloads (generation vs. training) with complex dependencies that static strategies cannot optimize simultaneously
- Inefficient resource allocation in large-scale training (up to 70B parameters) results in significant waste of expensive GPU compute time
- Current systems often force a single global strategy, failing to exploit the unique parallelization needs of different model function calls
Concrete Example:
In a typical setup, distributing the Actor model across all GPUs causes massive synchronization overhead during generation. Conversely, splitting GPUs statically between Actor and Critic leaves the Critic's GPUs idle while the Actor generates text, wasting resources.
Key Novelty
Dynamic Parameter Reallocation
- Treats model weights as movable resources that can be redistributed across GPUs between different phases of the RLHF loop (e.g., from generation to training)
- Decomposes the RLHF workflow into granular 'model function calls' and assigns a specific parallelization strategy (Data/Tensor/Pipeline Parallelism) to each call individually
- Uses a Markov Chain Monte Carlo (MCMC) search algorithm with a lightweight runtime estimator to automatically find the fastest execution schedule
Architecture
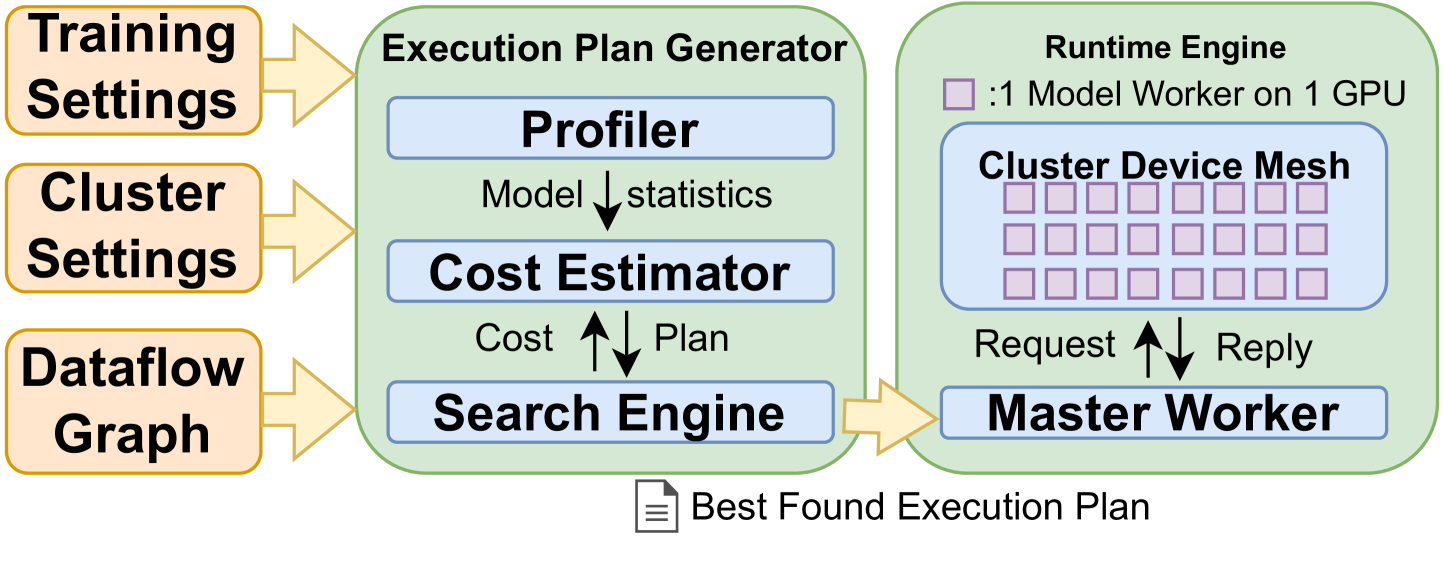
The system architecture of ReaL, showing the separation between the Execution Plan Generator and the Runtime Engine.
Evaluation Highlights
- Achieves up to 3.58x speedup in training throughput compared to baseline methods on LLaMA models (up to 70B parameters) using 128 H100 GPUs
- Generated execution plans outperform heuristic strategies based on Megatron-LM by an average of 54%
- Performance improvement reaches 81% over Megatron-LM heuristics in long-context training scenarios
Breakthrough Assessment
8/10
Significant systems-level optimization for RLHF. The concept of dynamic parameter reallocation addresses a fundamental inefficiency in static distributed training layouts, yielding substantial throughput gains.