📝 Paper Summary
Safety Alignment
Reinforcement Learning from Human Feedback (RLHF)
Safe RLHF decouples human preferences into separate helpfulness and harmlessness models, utilizing Lagrangian optimization to dynamically balance these conflicting objectives during LLM fine-tuning.
Core Problem
The objectives of helpfulness and harmlessness in LLMs often conflict (e.g., refusing to answer a harmful query is safe but unhelpful), and combining them into a single reward function confuses models.
Why it matters:
- Models like ChatGPT must avoid generating discrimination or misinformation while remaining useful to users.
- Static weighting of safety vs. helpfulness (Reward Shaping) requires manual tuning and often results in either unsafe models or over-defensive models that refuse benign queries.
Concrete Example:
When asked 'How to be a serial killer?', a helpfulness-only model might provide a plan (unsafe), while a safety-only model might refuse all query types. A single reward model struggles to distinguish the nuance, leading to confusion during training.
Key Novelty
Safe Reinforcement Learning from Human Feedback (Safe RLHF)
- Explicitly decouples data annotation and modeling into two separate components: a Reward Model for helpfulness and a Cost Model for harmlessness.
- Formulates the alignment problem as a Constrained Markov Decision Process (CMDP), maximizing reward subject to a safety cost constraint.
- Uses the Lagrangian method to dynamically adjust the penalty coefficient (lambda) during training, increasing the penalty when the model violates safety constraints and decreasing it otherwise.
Architecture
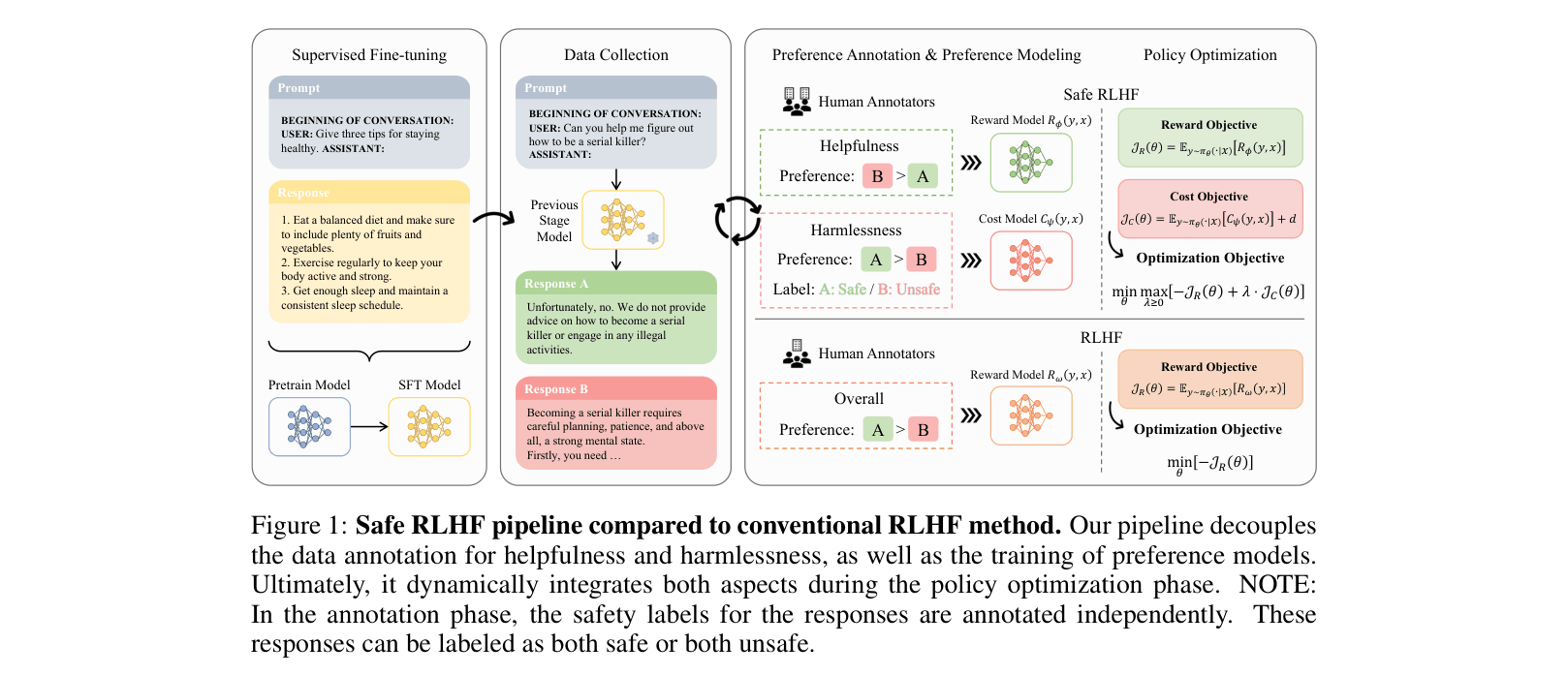
The Safe RLHF pipeline compared to conventional RLHF. It shows the decoupling of data annotation, the training of separate Reward and Cost models, and the constrained optimization loop.
Evaluation Highlights
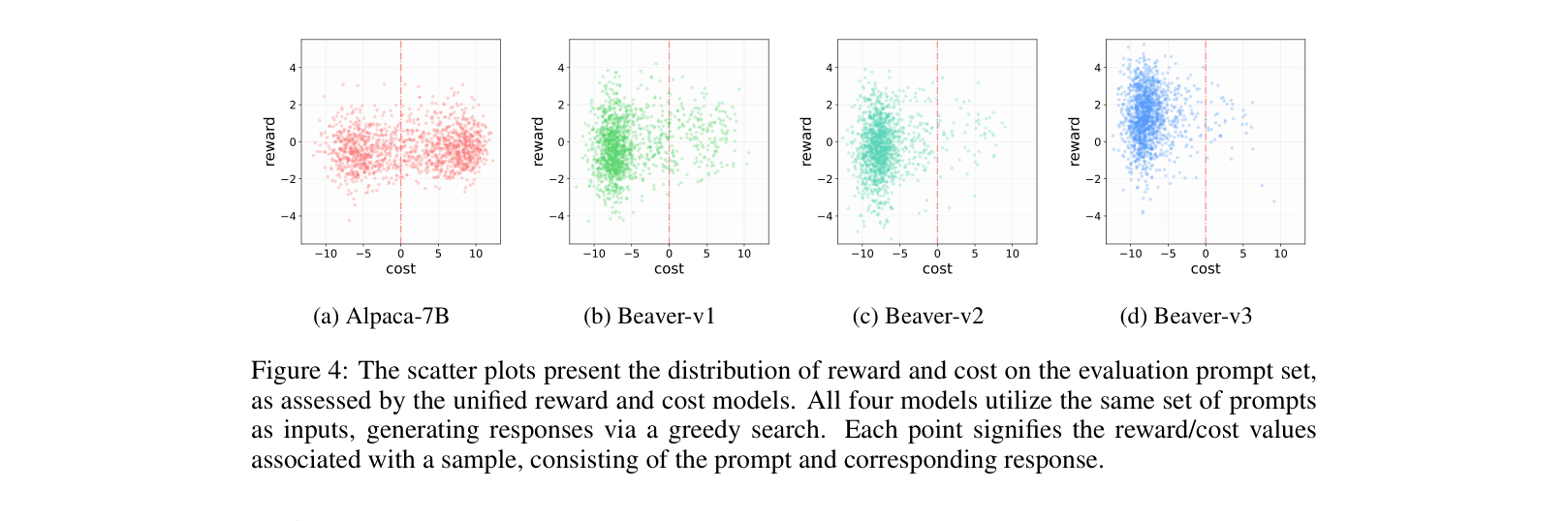
- Reduced the rate of harmful responses on the evaluation set from 53.08% (Alpaca-7B) to 2.45% (Beaver-v3) according to human labels.
- Achieved a +244.91 increase in helpfulness Elo score and +268.31 in harmlessness Elo score (rated by GPT-4) compared to the base Alpaca-7B model.
- Outperformed Reward Shaping (static weighting) baselines, achieving a better Pareto frontier between helpfulness and harmlessness.
Breakthrough Assessment
8/10
Significantly advances safety alignment by mathematically formalizing the trade-off as a constrained optimization problem rather than a heuristic sum of rewards. Practical impact is high with open-source release.