📝 Paper Summary
Large Multimodal Models (LMMs)
Vision-Language Alignment
Reinforcement Learning from Human Feedback (RLHF)
LLaVA-RLHF adapts reinforcement learning to multimodal models by augmenting the reward model with image captions and ground-truth answers to prevent it from being fooled by hallucinations.
Core Problem
Large Multimodal Models (LMMs) frequently hallucinate because they are trained on limited or lower-quality multimodal data compared to text-only models, causing misalignment between visual and textual modalities.
Why it matters:
- Hallucinated outputs in multimodal systems (e.g., describing objects not present in an image) severely undermine user trust and practical utility in real-world applications.
- Standard RLHF approaches suffer from 'reward hacking,' where the model optimizes for a high reward score without actually improving factual alignment, often due to weak reward models.
- Collecting high-quality human preference data for multimodal tasks is expensive and scarce compared to text-only domains.
Concrete Example:
When asking an LMM to describe an image, it might confidently describe 'a red car' when the image actually contains a blue truck. A standard reward model might accept the confident text if it flows well, failing to penalize the visual mismatch. LLaVA-RLHF's reward model sees the ground truth caption 'blue truck' and penalizes the 'red car' response.
Key Novelty
Factually Augmented RLHF (Fact-RLHF)
- Augments the Reward Model with 'cheat sheets' (image captions, ground-truth options) during training, allowing it to detect hallucinations that a standard model might miss.
- Enhances the Supervised Fine-Tuning (SFT) stage by converting high-quality human annotations (VQA, Flickr30k) into conversation formats, rather than relying solely on synthetic GPT-4 data.
- Introduces MMHal-Bench, a new evaluation benchmark specifically designed to penalize hallucinations across 8 task types and 12 object categories.
Architecture
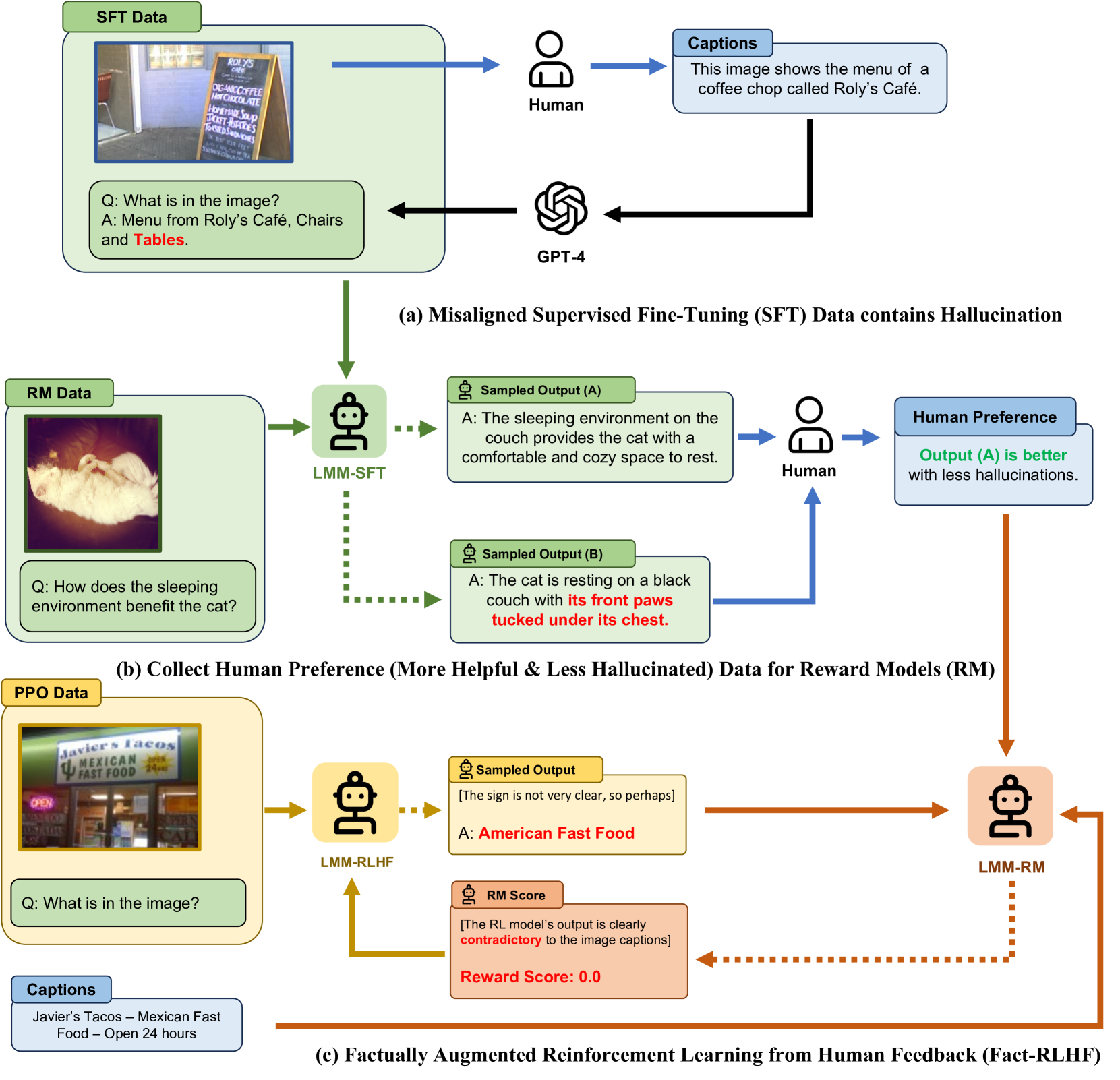
Illustration of the Factually Augmented RLHF (Fact-RLHF) framework compared to standard RLHF.
Evaluation Highlights
- Achieves 94% of text-only GPT-4's performance level on LLaVA-Bench, surpassing the previous best methods which reached only 87%.
- Achieves a 60% relative improvement on the new MMHal-Bench compared to baselines by specifically reducing hallucinations.
- Establishes new performance benchmarks for LLaVA with 52.4% accuracy on MMBench and 82.7% F1 score on POPE.
Breakthrough Assessment
8/10
First successful application of RLHF to Large Multimodal Models for hallucination reduction. The method of augmenting the reward model with factual data addresses the key 'reward hacking' bottleneck in multimodal RL.