📝 Paper Summary
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
Language Model Evaluation
PPE is a benchmark that evaluates reward models on proxy tasks—specifically crowdsourced human preferences and verifiable correctness—demonstrating that these metrics strongly correlate with the actual downstream performance of LLMs trained via RLHF.
Core Problem
Evaluating reward models is currently prohibitively expensive because the gold standard requires running a full RLHF training pipeline and evaluating the resulting LLM for every reward model candidate.
Why it matters:
- The long development-feedback cycle limits the iteration speed and quality of reward models, which are critical for effective RLHF.
- Existing benchmarks like RewardBench rely on static datasets that may not correlate well with actual post-RLHF outcomes as models improve.
- Without a predictive proxy, researchers waste significant compute training LLMs with suboptimal reward models.
Concrete Example:
A researcher might train a reward model that achieves high accuracy on a static test set like RewardBench but fails to produce a better Chatbot Arena model when used for PPO training. The paper shows a negative correlation between RewardBench scores on top models and actual downstream RLHF performance, highlighting the need for a better proxy.
Key Novelty
Preference Proxy Evaluations (PPE)
- Establishes the first reward model benchmark explicitly validated by training actual RLHF models and measuring their downstream performance to prove correlation.
- Uses 'Best-of-K' sampling on verifiable benchmarks (e.g., MATH, MMLU-Pro) to mimic the exploration dynamics of RLHF, testing if the reward model can distinguish correct answers among many sampled variations.
- Sounces ground truth preferences from diverse crowdsourced data (Chatbot Arena) rather than relying solely on LLM judges or small expert annotations.
Architecture
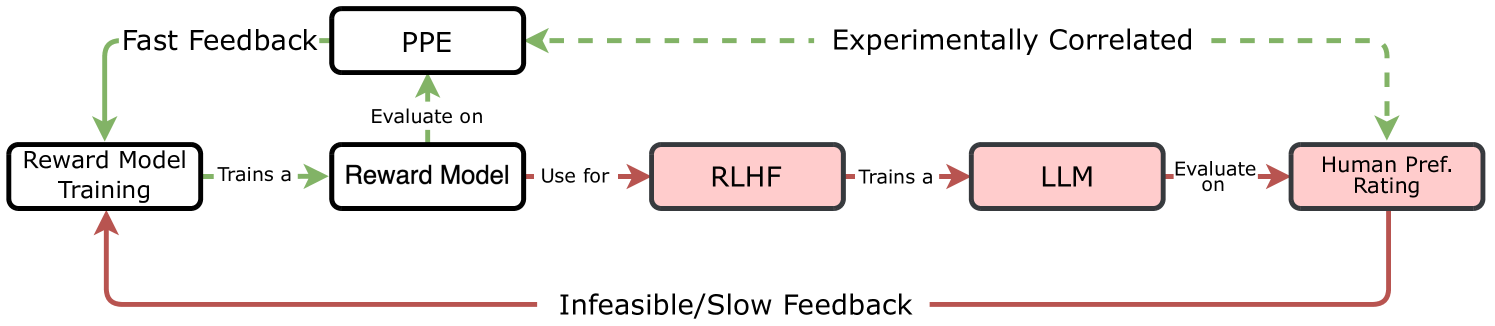
Conceptual comparison between the 'Gold Standard' evaluation (slow, expensive RLHF loop) and the proposed PPE workflow (fast, proxy-based).
Evaluation Highlights
- Identifies strong correlations between specific reward model metrics (like Best-of-K correctness accuracy) and the win-rate of the final RLHF-tuned LLM in Chatbot Arena.
- Releases PPE, a dataset of 16,038 labeled human preference pairs and 81,760 verifiable responses across 4 models for robust evaluation.
- Demonstrates that previous benchmarks (RewardBench) can show negative correlation with downstream performance for top-tier models, whereas PPE metrics maintain predictive power.
Breakthrough Assessment
9/10
Significantly advances the field by closing the loop between reward model evaluation and actual RLHF outcome, replacing heuristics with empirically validated proxies. Essential for efficient RLHF research.