📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF) systems
Distributed Large Language Model (LLM) training
HybridFlow combines single-controller flexibility for inter-node data dependencies with multi-controller efficiency for intra-node distributed computation, significantly boosting RLHF training throughput.
Core Problem
Existing RLHF systems use a rigid multi-controller paradigm that tightly couples computation and communication, making it hard to implement diverse algorithms and inefficient to reshard models between training and generation.
Why it matters:
- RLHF involves complex dataflows with heterogeneous models (actor, critic, reward) requiring different parallel strategies
- Resharding large model weights (e.g., 70B parameters) between training and generation stages incurs massive communication overhead (up to 36% of iteration time)
- Rigid frameworks hinder the exploration of new RLHF algorithms like Safe-RLHF or ReMax by requiring deep code modifications for data dependencies
Concrete Example:
Aligning a 70B actor model requires transferring 140GB of weights from training to generation per iteration. In existing systems like OpenRLHF, this leads to redundant memory usage or significant idle time while waiting for transfers.
Key Novelty
Hierarchical Hybrid Programming Model with 3D-HybridEngine
- Decouples intra-node distributed computation (handled by efficient multi-controller workers) from inter-node dataflow coordination (handled by a flexible single controller)
- Introduces a 3D-HybridEngine that seamlessly reshards the actor model between training and generation phases without memory redundancy, optimizing communication
- Uses an automated mapping algorithm to optimize the placement of heterogeneous models onto GPU devices based on their workloads
Architecture
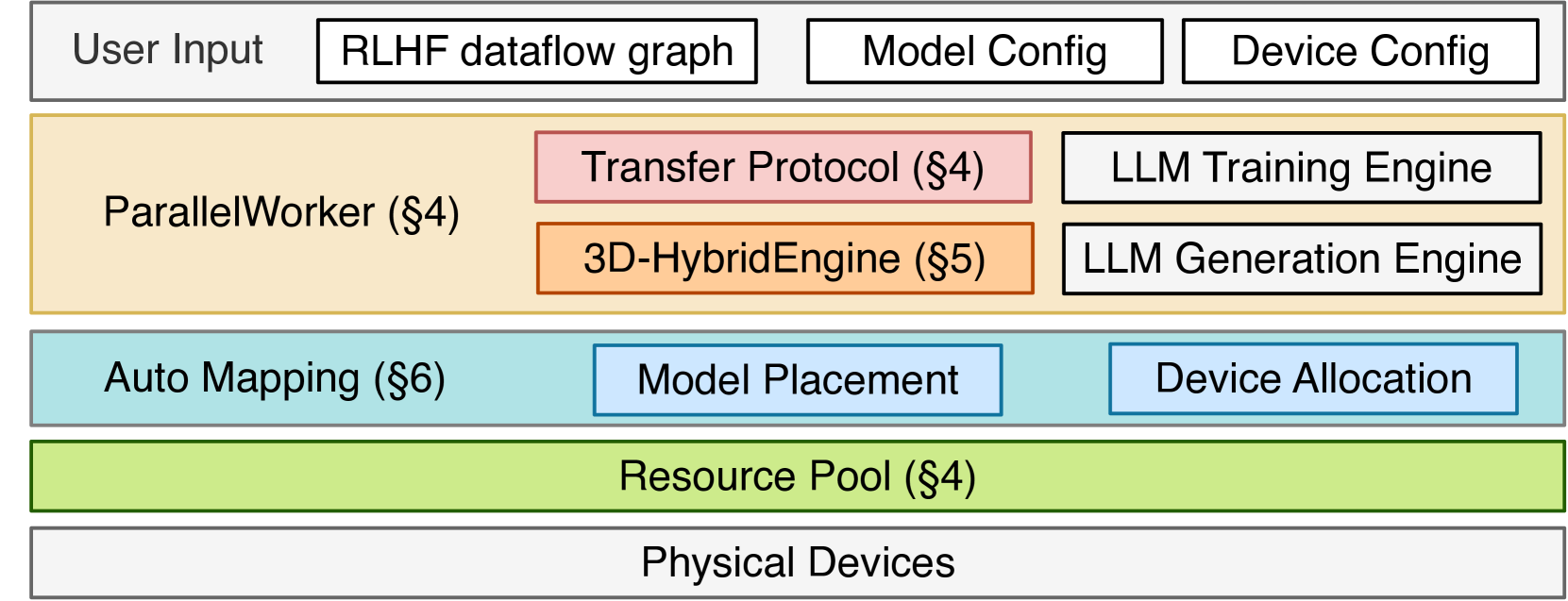
Overview of HybridFlow architecture showing the interaction between the Single Controller, Worker Groups, and the 3D-HybridEngine.
Evaluation Highlights
- Achieves 1.53× to 20.57× throughput improvement over state-of-the-art systems (DeepSpeed-Chat, OpenRLHF) across various model sizes (7B to 70B)
- Reduces data transfer overhead for actor resharding significantly; for 70B models, HybridFlow is ~1.9× faster than DeepSpeed-Chat
- Scales efficiently to large clusters (up to 64 GPUs), maintaining high GPU utilization where baselines suffer from idle time or OOM errors
Breakthrough Assessment
9/10
Addresses the critical system-level bottlenecks of RLHF (flexibility and efficient resharding) with a novel hybrid architecture. The performance gains are massive (up to 20x), and the open-source release makes it highly impactful.