📝 Paper Summary
Code Generation
Code Efficiency Optimization
Afterburner employs a closed-loop iterative framework where an LLM optimizes code efficiency using reinforcement learning updates driven by real-time execution feedback from a sandbox.
Core Problem
Large Language Models generate functionally correct code that is often computationally inefficient (slow or memory-intensive), creating bottlenecks for real-world deployment.
Why it matters:
- Inefficient code inflates computing costs and system-wide latencies in mission-critical tasks
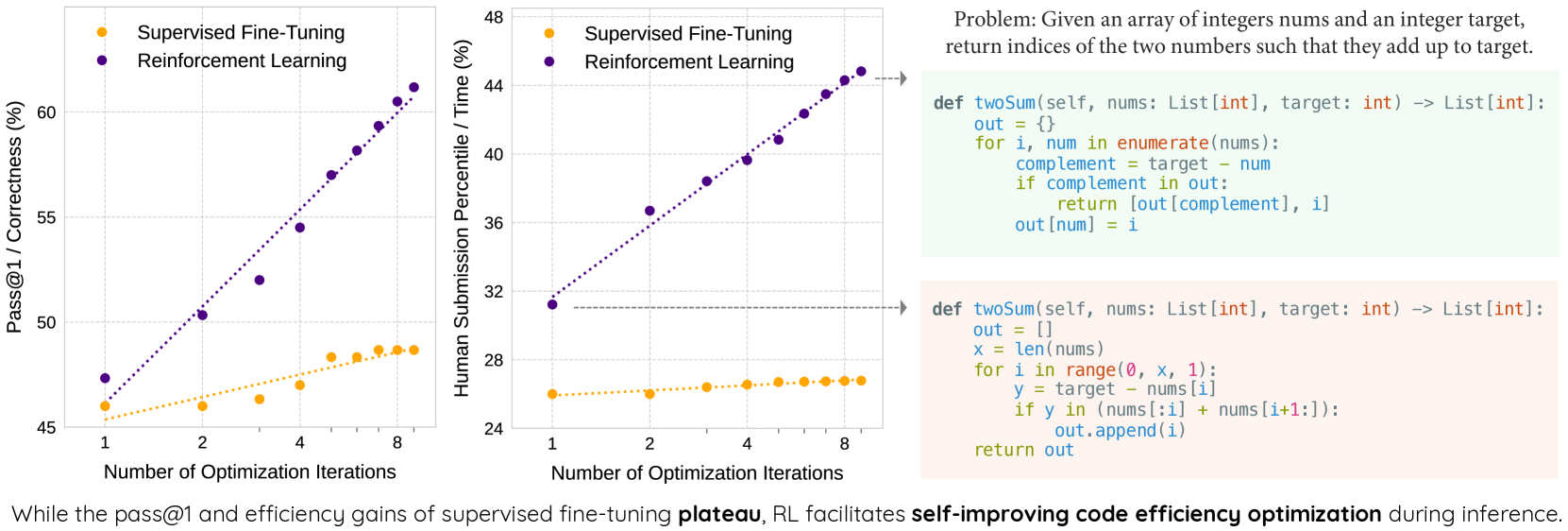
- Existing optimization methods (SFT, DPO) rely on static data patterns and saturate quickly, failing to generalize to new efficiency problems
- Prior benchmarks focus on correctness, often overlooking the latency and memory budgets paramount in production systems
Concrete Example:
A model might generate a correct O(n^2) sorting algorithm when an O(n log n) solution is required. While SFT might teach it to mimic a specific faster sort, it struggles to adaptively optimize a novel complex algorithm without execution feedback.
Key Novelty
Iterative Optimization Framework (IOF) with Online GRPO
- Replaces static imitation learning with a dynamic loop: the model generates code, a sandbox (Monolith) measures actual time/memory, and the model updates based on this empirical feedback
- Uses Group Relative Policy Optimization (GRPO) to rank multiple generated solutions against each other based on execution metrics, teaching the model 'how' to optimize rather than just 'what' to write
Architecture
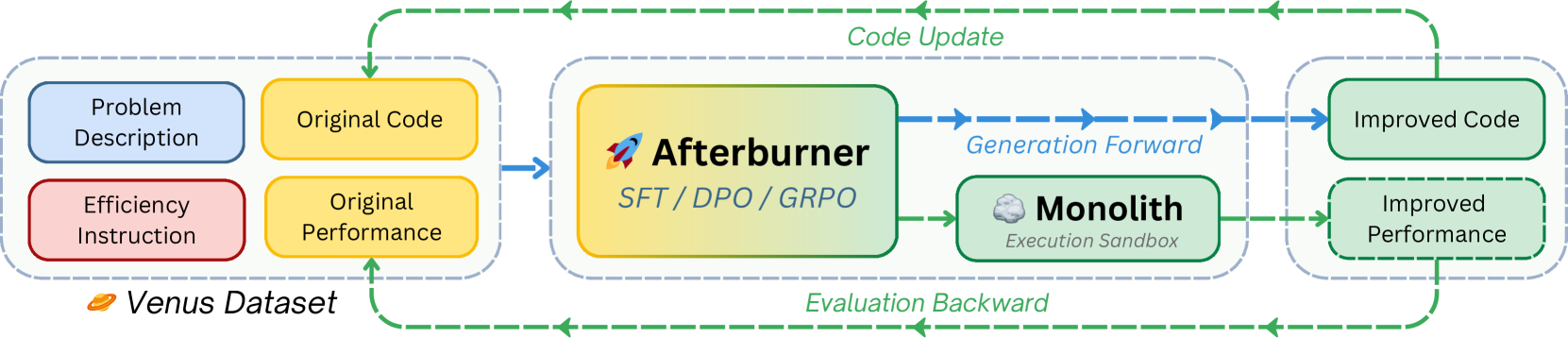
The Iterative Optimization Framework (IOF) workflow involving Afterburner and Monolith.
Evaluation Highlights
- Boosts Pass@1 from 47% to 62% on the Venus benchmark using GRPO (relative to base performance)
- Increases the likelihood of outperforming human submissions in efficiency (Beyond-I metric) from 31% to 45%
- Demonstrates that SFT and DPO strategies saturate early, while GRPO continuously refines performance through iterative feedback
Breakthrough Assessment
8/10
Addresses a critical, under-explored gap (efficiency vs. correctness) with a robust closed-loop RL system. The shift from imitation to execution-driven reinforcement for non-functional code properties is a significant methodological advance.