📝 Paper Summary
LLM Mathematical Reasoning
Reinforcement Learning (RL) Analysis
Reasoning Decomposition
RL training (specifically GRPO) improves math performance primarily by making models more robust at executing known solution paths (temperature distillation) rather than teaching them to plan solutions for fundamentally new problems.
Core Problem
Standard metrics like Pass@1 are too coarse to reveal which specific reasoning skills RL improves, failing to distinguish between genuine planning capabilities and simple execution robustness.
Why it matters:
- Pass@1 evaluates greedy decoding, but real-world deployments use stochastic sampling where robustness matters
- It is unclear if RL actually teaches new reasoning capabilities (planning/logic) or just reinforces existing knowledge
- Understanding these limits is crucial for overcoming the 'coverage wall' where RL stops improving performance on novel problems
Concrete Example:
A model might solve a math problem correctly only if specific keywords like 'block' are used instead of 'unit' (spurious correlation). RL fixes this by making the model robust to such phrasing (execution), but it doesn't help the model solve a problem where it lacks the initial idea of how to start (planning).
Key Novelty
Reasoning Decomposition Framework & Synthetic Tree Navigation Task
- Decomposes math problem solving into three distinct skills: Plan (mapping questions to steps), Execute (performing steps), and Verify (checking results), rather than a single accuracy score
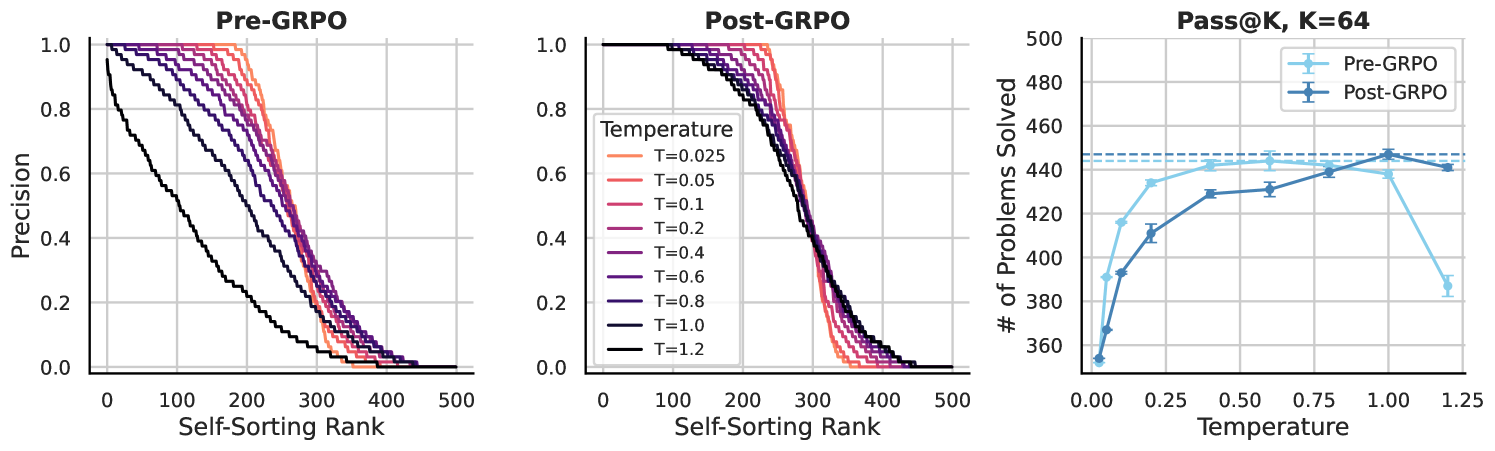
- Identifies 'Temperature Distillation': RL flattens the precision curve across sampling temperatures, making correct answers likely even at high temperatures, but without expanding the set of solvable problems
- Constructs a minimal synthetic solution-tree task to isolate planning from execution, proving that standard RL struggles to explore new solution paths without specific data conditions
Architecture
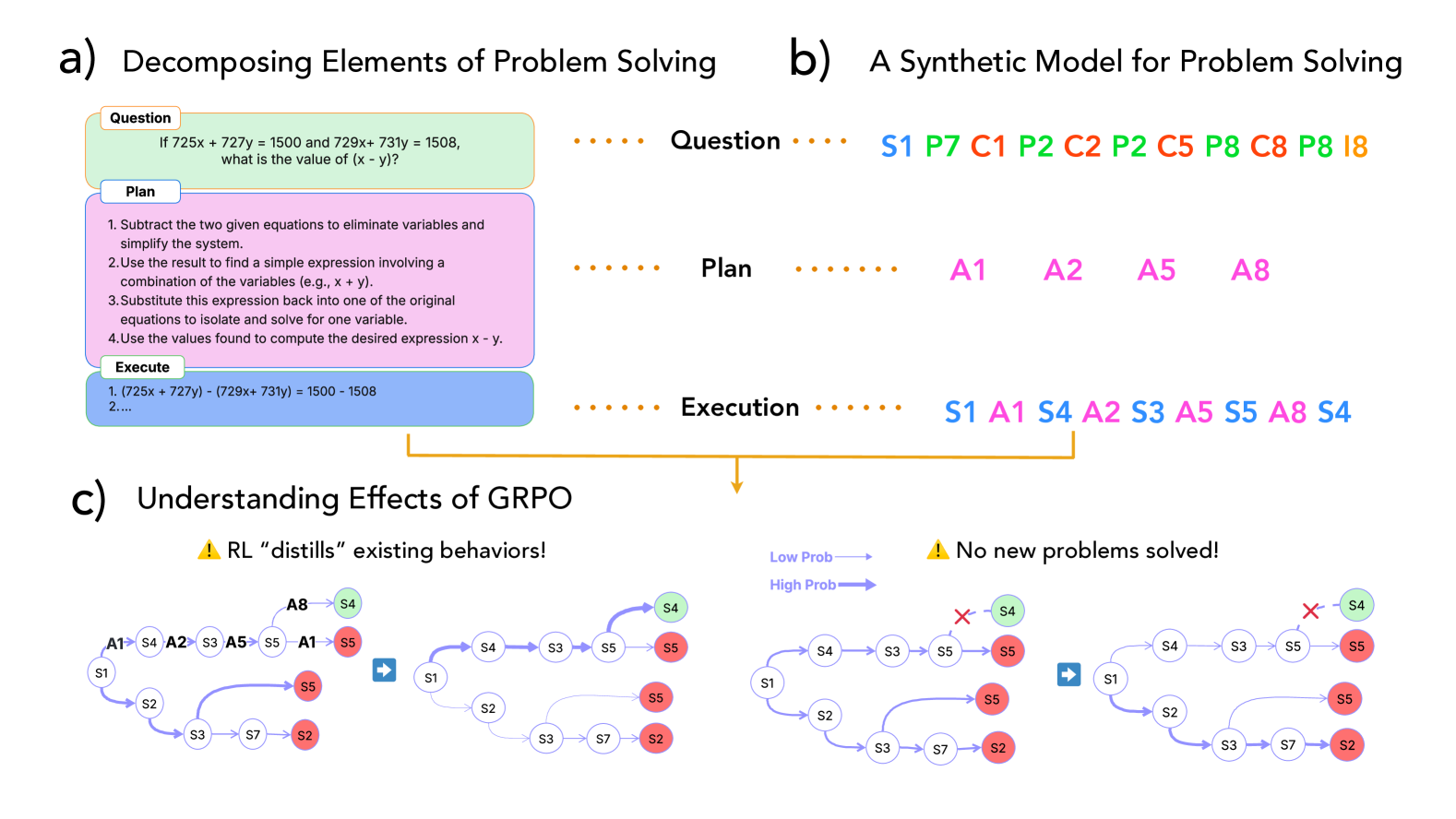
Conceptual framework decomposing problem solving into a tree search with Plan, Execute, and Verify steps
Evaluation Highlights
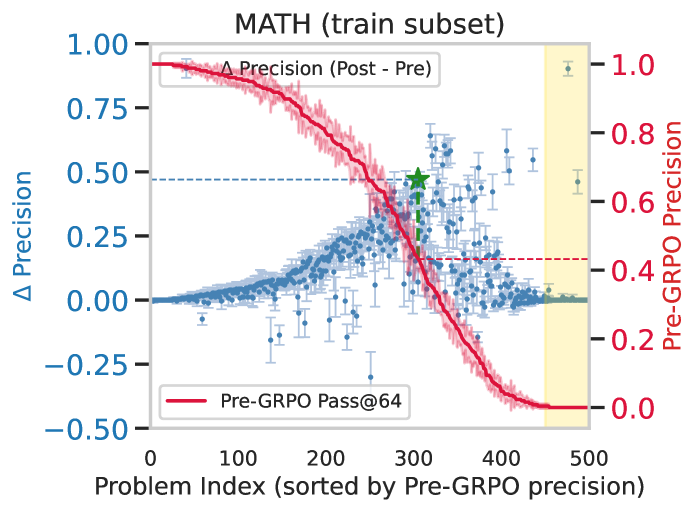
- GRPO improves precision on training set problems (up to +45% on medium-difficulty problems) but fails to generalize to new test problems, hitting a 'coverage wall'
- On the test set, peak improvement shifts to problems the model could already solve with majority voting (approx. 60% pre-GRPO precision), with zero new problems solved outside this range
- RL significantly reduces elementary-level math and logic errors (execution failures) but does not meaningfully reduce high-school level factual errors
Breakthrough Assessment
8/10
Strong diagnostic work. It challenges the prevailing narrative that RL 'teaches' reasoning, rigorously showing it largely refines execution of known paths. The decomposition framework and synthetic task are valuable tools for future research.