📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
DARO improves mathematical reasoning in LLMs by dynamically learning loss weights for different problem difficulties during training, preventing the model from disproportionately focusing on specific difficulty levels.
Core Problem
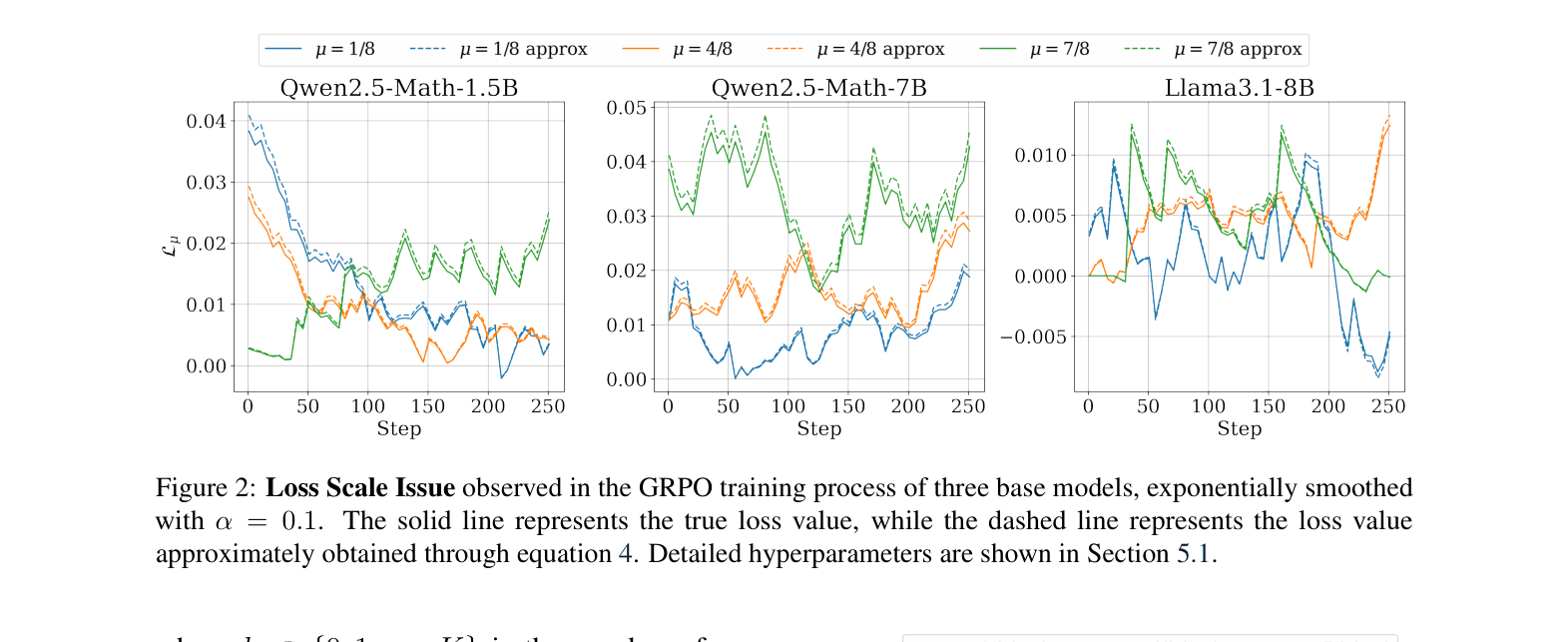
Current RLVR methods (like GRPO and LIPO) use static weighting schemes based on empirical pass rates, causing a 'loss scale issue' where the training objective disproportionately focuses on certain difficulty levels.
Why it matters:
- Static weights (e.g., variance-based) often downweight very easy or very hard samples to zero, potentially causing catastrophic forgetting of basic knowledge
- Over-focusing on specific difficulty bands prevents the model from adapting as its capabilities evolve during the training process
- The imbalance disrupts the exploration-exploitation trade-off, slowing down convergence and limiting final reasoning performance
Concrete Example:
In GRPO, samples with a pass rate near 0 or 1 often have very low gradients. If a model finds most problems too hard (pass rate ≈ 0) or too easy (pass rate ≈ 1), the gradients vanish or become unbalanced, causing the model to ignore those samples rather than learning from the edge cases.
Key Novelty
Difficulty-Aware Reweighting Policy Optimization (DARO)
- Treats groups of samples with different pass rates (difficulties) as distinct tasks in a multi-task learning framework
- Introduces learnable weight parameters for each difficulty group that are optimized jointly with the model to balance the total loss contribution
- Dynamically increases weights for difficulty levels where the model currently struggles (high loss) to ensure balanced training focus
Architecture
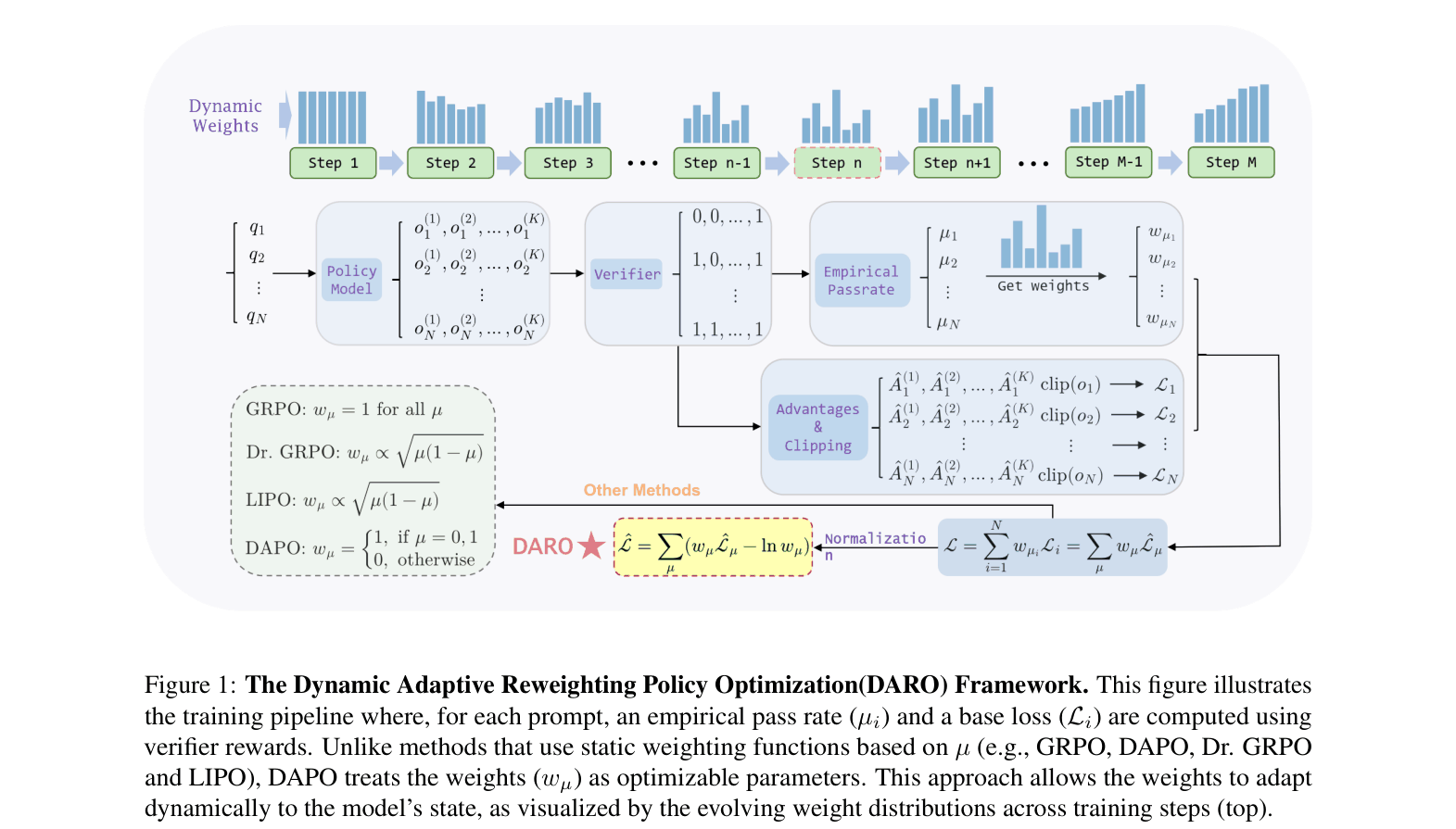
The DARO training pipeline where empirical pass rates determine base losses, which are then modulated by dynamically learnable weights.
Evaluation Highlights
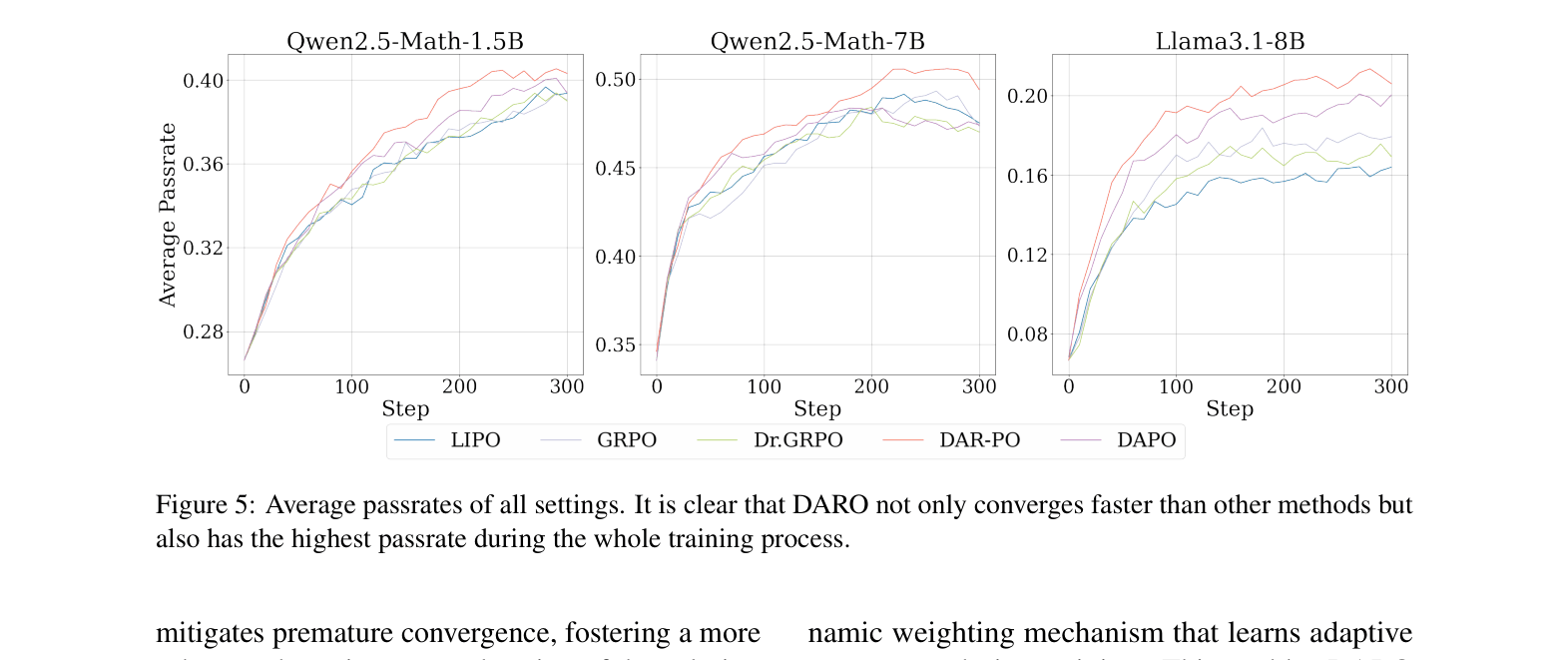
- Achieves highest average accuracy across 6 math benchmarks on Qwen2.5-Math-7B (50.8%), outperforming GRPO (+1.4%) and DAPO (+2.4%)
- Demonstrates significantly faster convergence: Llama-3.1-8B reaches 20% pass rate in half the training steps required by DAPO
- Consistent improvements on Llama-3.1-8B (+2.7% avg vs GRPO) and Qwen2.5-Math-1.5B (+1.0% avg vs GRPO) across diverse datasets like MATH500 and AIME
Breakthrough Assessment
8/10
Identifies a fundamental mathematical flaw (loss scale issue) in the widely used GRPO framework and provides a theoretically grounded, adaptive solution that yields consistent empirical gains.