📝 Paper Summary
Multimodal Large Language Models (MLLMs)
Mathematical Reasoning
Reinforcement Learning
URSA is a framework that improves multimodal math reasoning by synthesizing large-scale process supervision data and using a novel Process-Supervised Group Relative Policy Optimization (PS-GRPO) to mitigate reward hacking and length bias.
Core Problem
Multimodal LLMs struggle with complex math due to data scarcity and the difficulty of applying Process Reward Models (PRMs) without causing reward hacking or length bias during Reinforcement Learning.
Why it matters:
- Existing Test-Time Scaling and RL methods rely on strong foundation models and high-quality process labels, which are scarce for multimodal tasks
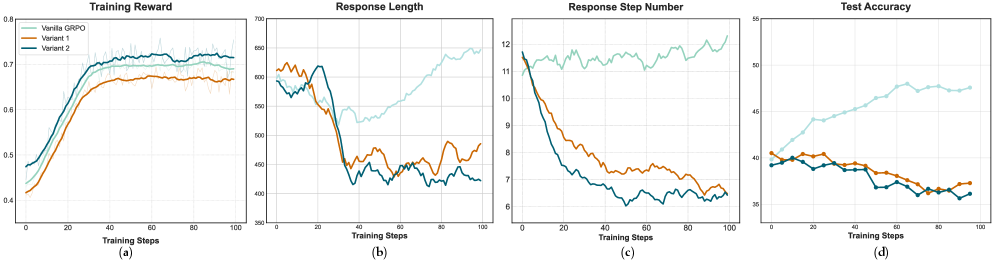
- Naive application of scalar process rewards in RL leads to 'reward hacking' (optimizing for rewards rather than correctness) and 'length bias' (models becoming lazy/short to avoid risk)
- Automated process labeling for vision-language tasks is unexplored compared to text-only math
Concrete Example:
When using standard scalar process rewards in RL, the model learns that later steps in a reasoning chain are often penalized by the PRM (due to conservative labeling). Consequently, the model collapses to generating extremely short, heuristic-based answers to minimize the risk of negative rewards, harming reasoning depth.
Key Novelty
Unfolding multimodal pRocess-Supervision Aided (URSA) framework
- Constructs MMathCoT-1M (reasoning data) and DualMath-1.1M (process data) using automated expansion, rewriting, and error injection strategies
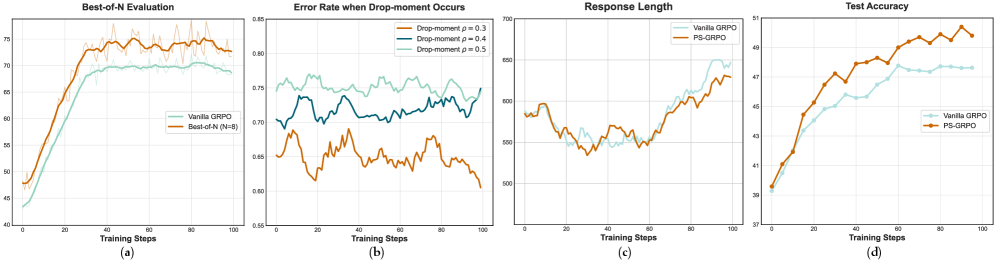
- Introduces PS-GRPO, an RL algorithm that discards unreliable scalar process rewards and instead uses 'drop-moments' (sudden drops in process quality) to penalize correct-outcome rollouts that contain reasoning flaws
- Utilizes a dual-view data synthesis engine: Binary Error Locating for logical errors and Misinterpretation Insertion Engine for visual hallucinations
Architecture
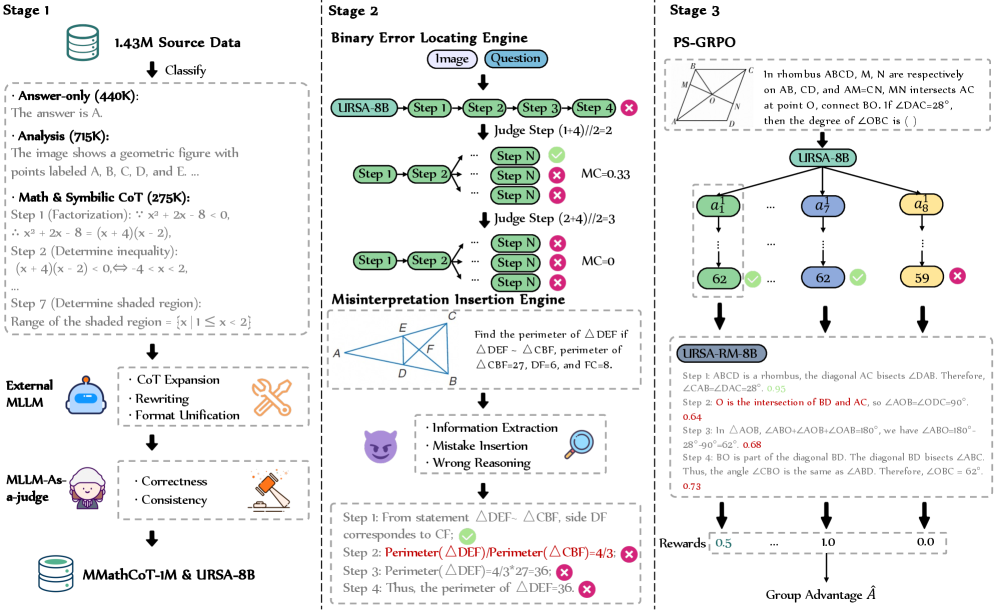
The three-stage URSA framework pipeline: (I) Data Curation & SFT, (II) Dual-View Process Data Synthesis & PRM Training, and (III) Process-Supervised GRPO (PS-GRPO).
Evaluation Highlights
- URSA-8B-PS-GRPO outperforms GPT-4o by 2.7% on average across 6 multimodal math benchmarks (e.g., +20.6% on MathVista-GPS)
- Surpasses open-source baseline Gemma3-12B by 8.4% on average despite being smaller (8B parameters)
- URSA-8B-RM (Process Reward Model) improves Test-Time Scaling, achieving 16.6% relative improvement on MathVerse with just Best-of-4 sampling
Breakthrough Assessment
8/10
Significant contribution in applying PRMs to multimodal settings. The release of 1M+ multimodal CoT/process datasets and a robust RL method (PS-GRPO) addressing length bias makes this highly impactful for the open-source community.