📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
TemplateRL improves LLM reasoning by extracting structured solution templates via MCTS and using them to guide exploration during reinforcement learning, significantly boosting sample efficiency and performance.
Core Problem
Existing RL methods like GRPO rely on unstructured self-sampling, leading to inefficient exploration, training instability on weak models, and failure to learn transferable high-level strategies.
Why it matters:
- Inefficient trajectory sampling results in low hit rates for correct solutions, wasting compute during training
- Models tend to learn surface-level steps rather than generalizable problem-solving patterns (e.g., divide-and-conquer), hindering cross-domain transfer
- Unstructured reasoning traces lack interpretability, making error diagnosis and expert intervention difficult
Concrete Example:
When solving a complex math problem, a standard RL model might randomly sample irrelevant steps and fail to find the correct path. TemplateRL forces the model to follow a proven structure (e.g., 'Step 1: List conditions -> Step 2: Set up equation'), increasing the chance of a correct rollout.
Key Novelty
Structured Template-Guided Reinforcement Learning
- Constructs a library of 'reasoning templates' (sequences of prompt-based actions) by running MCTS on a small seed dataset and abstracting successful paths
- During RL training, retrieves relevant templates based on problem complexity and forces the policy to follow these high-level structures during rollout generation
- Decomposes the RL objective into template-guided sub-objectives, stabilizing gradients and steering the policy toward proven strategic patterns
Architecture
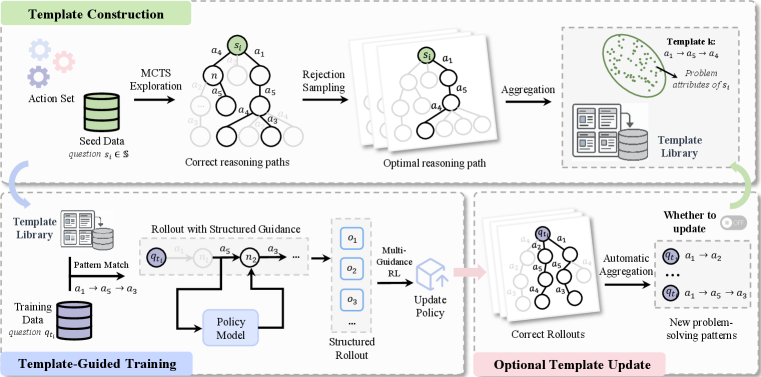
The overall TemplateRL framework, illustrating the pipeline from template construction to guided training.
Evaluation Highlights
- Achieves 33.3% accuracy on AIME 2024, outperforming standard GRPO (16.7%) by 99.4% relative using a Qwen2.5-Math-7B backbone
- Outperforms the best baseline (Oat-Zero) by 7.1 points on average across 5 reasoning benchmarks (MATH500, AIME, AMC, etc.)
- Demonstrates stability on smaller models (Llama-3.2-3B) where standard GRPO collapses and fails to learn
Breakthrough Assessment
9/10
Significant performance jumps on hard benchmarks (AIME/AMC) and addresses the critical stability/exploration issues in RL for reasoning. The idea of explicit template guidance is a strong structural prior.