📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Code Generation / Code Editing
GAPO improves reinforcement learning for code editing by calculating advantages using the median of the highest-density reward interval rather than the group mean, making training robust to noisy outliers.
Core Problem
In real-world code editing, reward distributions are often skewed by unpredictable outliers, causing standard group-relative methods (like GRPO) to compute distorted advantage values that destabilize training.
Why it matters:
- Existing methods treat all rewards uniformly (using the mean), but real-world prompts produce noisy rollouts where outliers skew the baseline, hurting generalization.
- Noise often contains useful information about model corner cases ('blurry ability edge') that standard methods discard or mishandle, missing opportunities to improve on hard tasks.
Concrete Example:
If a model generates 10 code edits where 9 are incorrect (reward ~0.1) and 1 is correct (reward 1.0), the mean is low (~0.19). A standard method might overestimate the 'badness' of the 0.1 rewards relative to this mean. GAPO identifies the dense cluster at 0.1, uses its median as the baseline, and correctly identifies the 1.0 reward as a significant positive outlier to learn from.
Key Novelty
Group Adaptive Policy Optimization (GAPO)
- Adaptively identifies the 'Highest-Density Interval' (HDI) of rewards for each prompt—the narrowest range containing the majority of samples—to isolate the signal from noise.
- Replaces the standard group mean with the median of this dense interval for advantage calculation, making the baseline robust to skew while still amplifying the signal of high-quality outliers.
Architecture
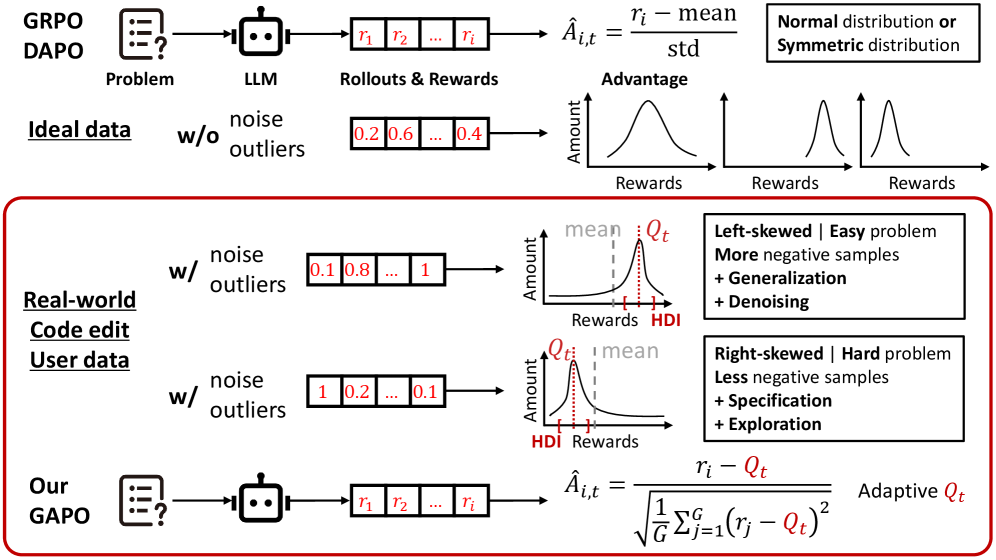
Comparison of advantage calculation between GRPO (Mean) and GAPO (Adaptive Q).
Evaluation Highlights
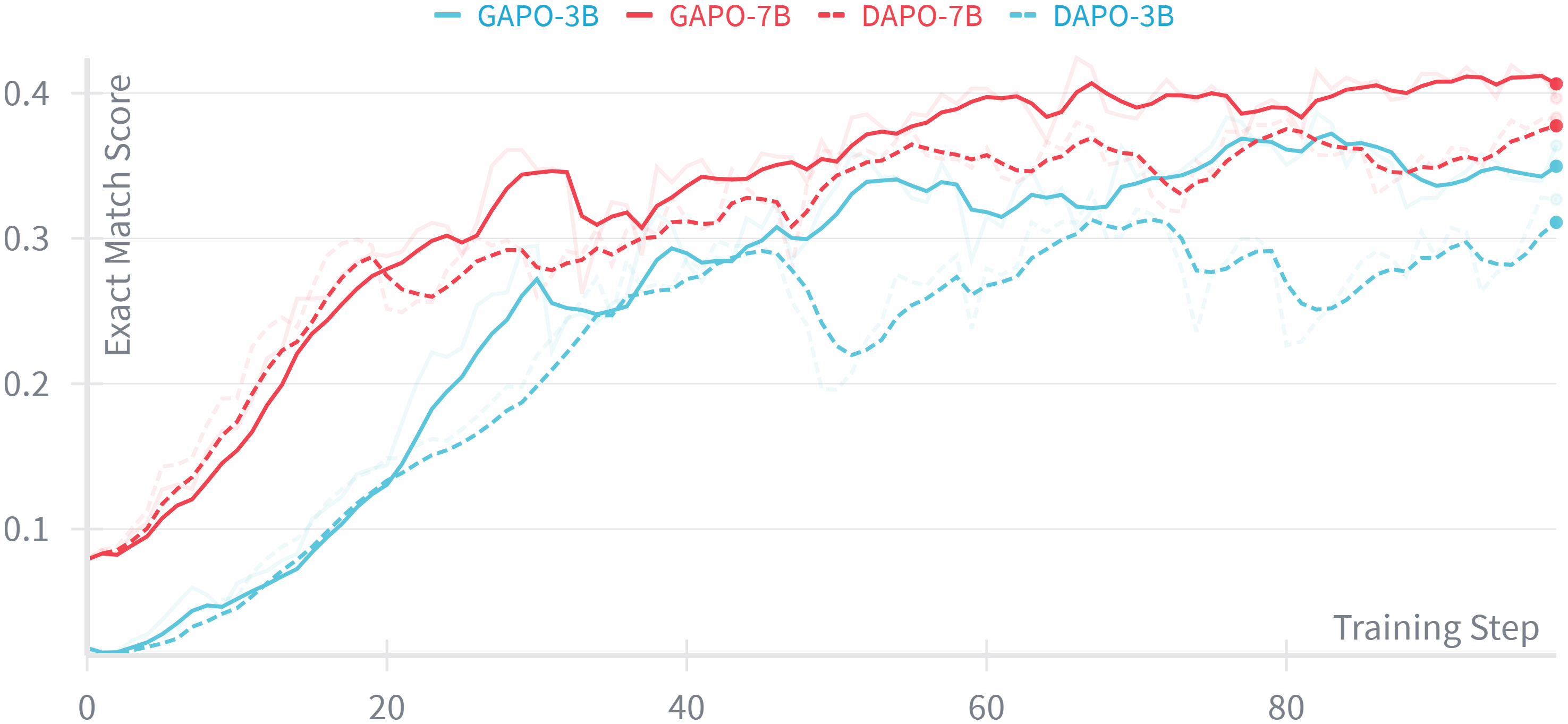
- +4.35% Exact Match improvement on in-domain real-world code editing tasks with Qwen2.5-Coder-7B compared to GRPO/DAPO baselines.
- +5.30% Exact Match improvement on the out-of-domain Zeta benchmark, demonstrating superior generalization.
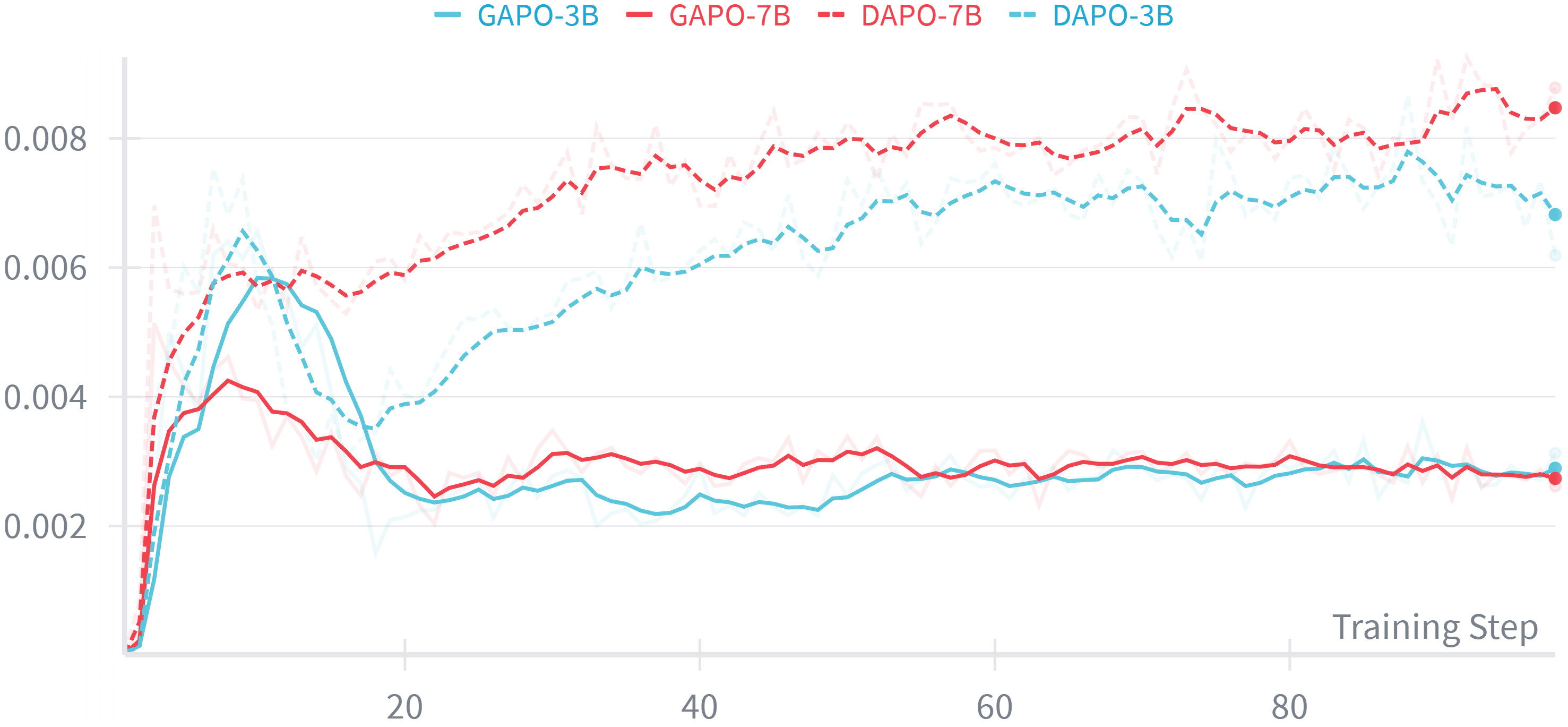
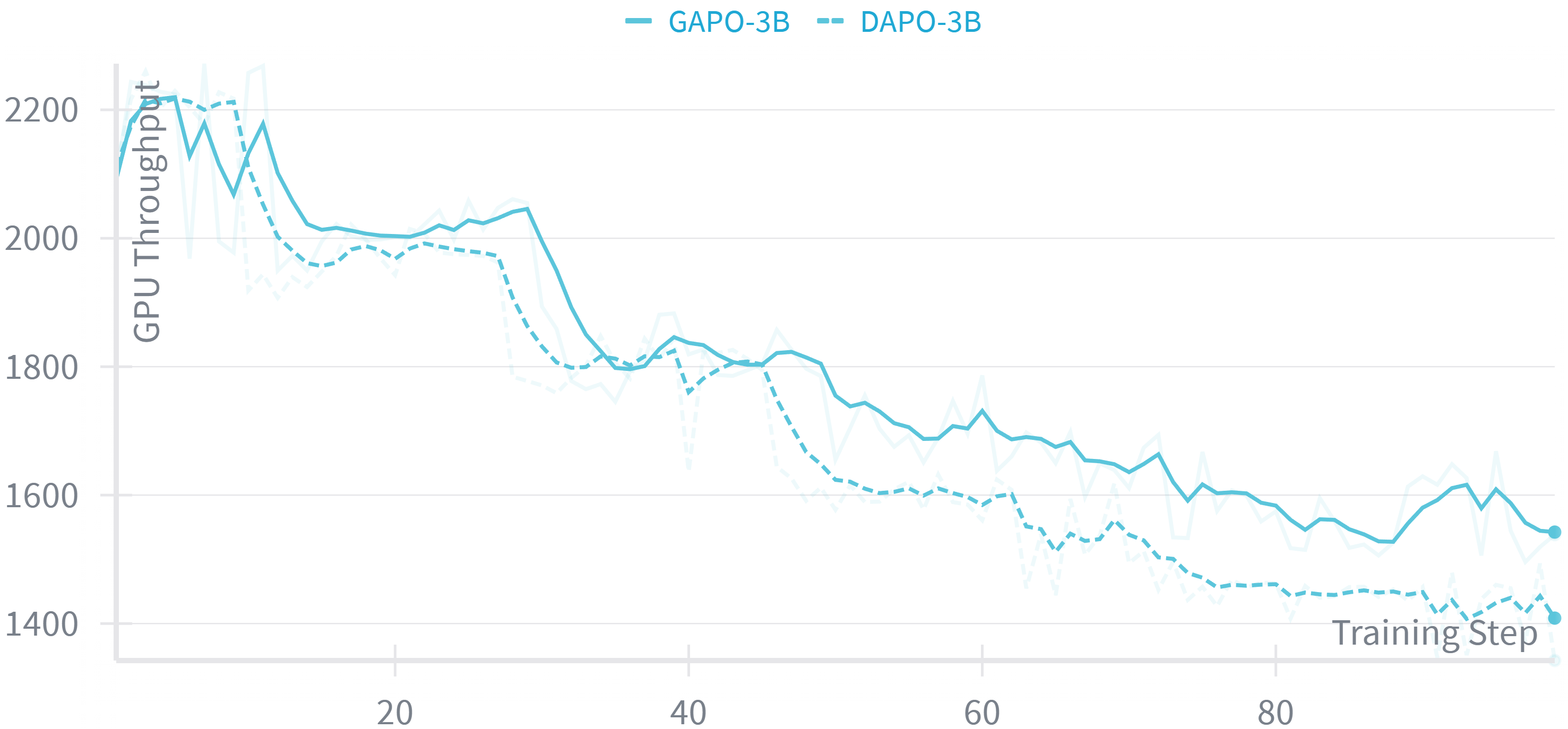
- Achieves higher GPU throughput (+4.96%) and lower clipping ratios than DAPO, indicating more stable and efficient training.
Breakthrough Assessment
7/10
Simple, plug-and-play modification to existing RL algorithms that yields consistent gains in noise-heavy real-world scenarios. While not a fundamental architectural shift, it solves a critical practical issue in RLHF.