📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
Training Dynamics Analysis
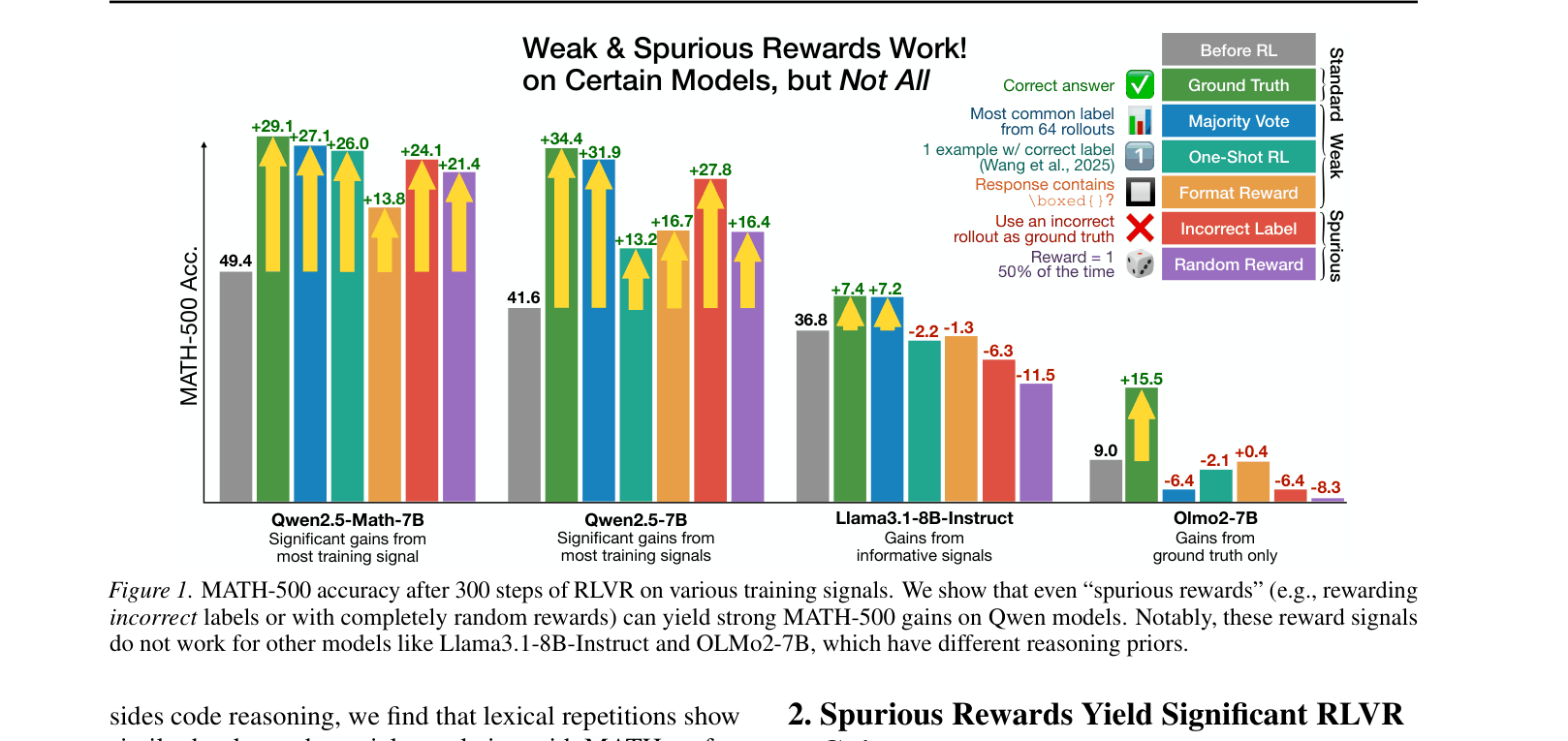
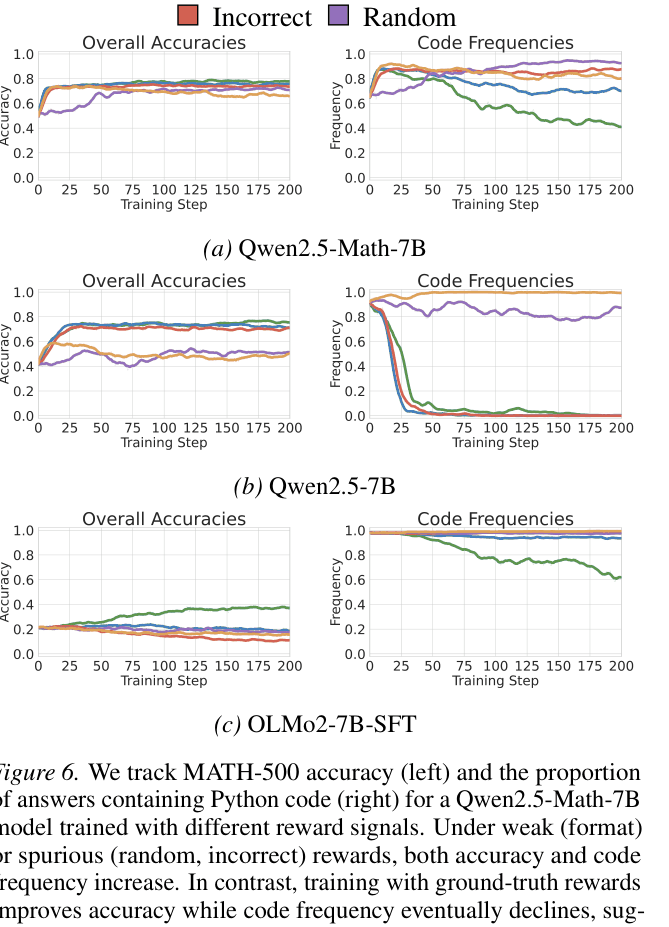
RLVR can significantly improve math reasoning on Qwen models even with random or incorrect rewards by amplifying pre-existing high-quality behaviors (like code reasoning) via GRPO's clipping bias.
Core Problem
The community assumes RLVR improves reasoning through verifiable feedback, but the underlying mechanism is poorly understood, as evidenced by gains from noisy or limited supervision.
Why it matters:
- Current RLVR research relies heavily on Qwen models, which may exhibit unique behaviors that do not generalize to other model families like Llama or OLMo
- Understanding whether RL teaches new skills or merely amplifies existing ones is crucial for designing robust post-training pipelines
- Blindly applying RLVR methods validated on Qwen to other models may result in failure or performance degradation
Concrete Example:
When trained with completely random rewards (noise), Qwen2.5-Math-7B improves its MATH-500 accuracy by 21.4%, nearly matching the 29.1% gain from ground truth rewards. In contrast, Llama3.1-8B-Instruct degrades by 6.4% under the same random reward conditions.
Key Novelty
Spurious Reward Elicitation & Clipping Bias Analysis
- Demonstrates that 'spurious rewards' (random, incorrect, or format-only) can elicit strong performance gains in specific models (Qwen), challenging the assumption that accurate feedback is necessary for RLVR
- Identifies 'clipping bias' in the GRPO objective as the mechanism: the clipping term asymmetrically favors high-probability tokens from the base model, reinforcing them even without informative rewards
- Pinpoints 'code reasoning' (using Python to solve math) as the specific latent high-quality behavior in Qwen models that gets amplified by this bias
Architecture
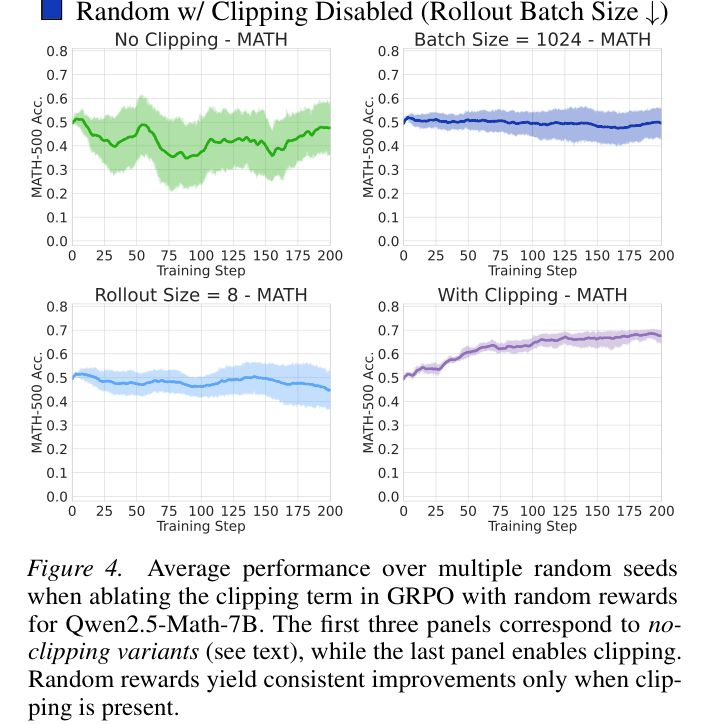
Ablation of the clipping term in GRPO, demonstrating that clipping is the cause of learning from random rewards.
Evaluation Highlights
- +21.4% absolute accuracy gain on MATH-500 for Qwen2.5-Math-7B using purely random rewards
- +24.1% gain on MATH-500 for Qwen2.5-Math-7B using rewards based on incorrect labels
- Code reasoning frequency in Qwen2.5-Math-7B increases from 65.0% to ~90% under spurious rewards, strongly correlating with accuracy improvements
Breakthrough Assessment
9/10
A highly counterintuitive and critical finding that challenges the foundations of RLVR. By showing that random rewards work on popular benchmarks, it forces a re-evaluation of prior success stories in reasoning alignment.