📊 Experiments & Results
Evaluation Setup
Multi-step deductive reasoning tasks where the model must answer correctly or abstain ('Unknown').
Benchmarks:
- GraphLA (Linear Algebra Reasoning (Natural Language)) [New]
- GraphLI (Logical Inference (Natural Language)) [New]
Metrics:
- Accuracy (Answerable)
- Accuracy (Unanswerable/Abstention)
- Binary Classification Accuracy (Answerable vs. Unanswerable)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
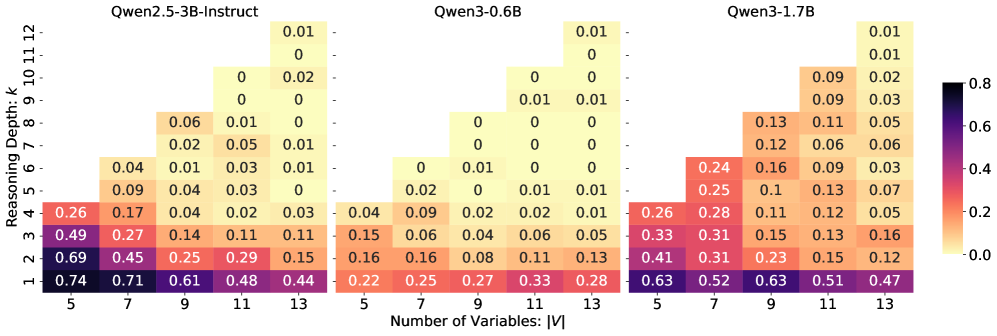
Accuracy of untrained Qwen models on GraphLA/GraphLI as a function of reasoning depth (k) and graph size (|V|).
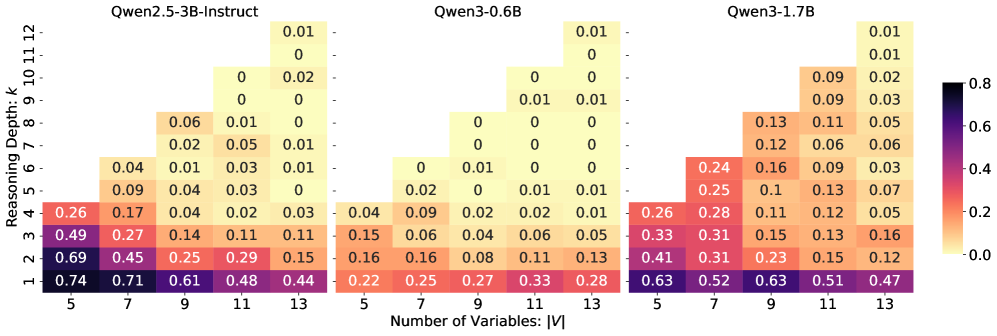
Binary classification accuracy (Answerable vs. Unanswerable) across varying depths.
Main Takeaways
- Current LLMs (Qwen series) lack honest reasoning capabilities: performance on answerable questions drops to near zero as reasoning depth increases beyond 6 steps.
- Models fail to reliably identify unanswerable queries: they either guess randomly or attempt to solve unsolvable problems, showing a lack of awareness of knowledge boundaries.
- Standard GRPO fails on this task because when a problem is hard, all rollouts are incorrect, leading to zero relative advantage and training collapse.
- Anchor is proposed to fix this by guaranteeing a positive learning signal, though specific performance numbers for the Anchor method are not included in the provided text snippet.