📝 Paper Summary
Reinforcement Learning Fine-tuning (RFT)
Data Selection / Curriculum Learning
Efficient LLM Training
GAIN-RL accelerates reinforcement learning fine-tuning by dynamically selecting training data based on 'angle concentration,' a model-internal signal that predicts learning potential and gradient magnitude.
Core Problem
Current Reinforcement Fine-tuning (RFT) is sample-inefficient and computationally expensive because it repeatedly exposes models to identical queries without accounting for the model's intrinsic ability to learn from them.
Why it matters:
- Training reasoning models (like Deepseek-R1) requires massive compute (e.g., GRPO on Qwen 2.5-7B takes ~240 GPU hours for just 100 steps)
- Existing data selection methods (LIMO, S1) rely on expensive decoding or model-agnostic heuristics that ignore how a specific model perceives data difficulty
- Fixed difficulty metrics fail because different models yield diverging accuracy distributions on the same dataset
Concrete Example:
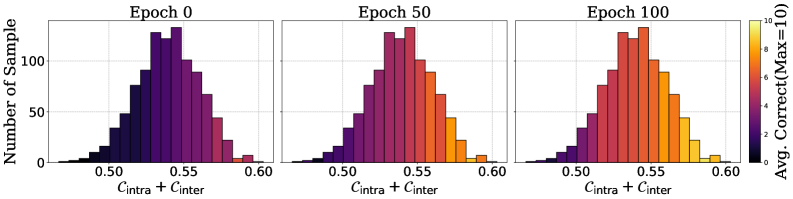
In standard GRPO training, a model might be forced to train on a difficult math problem it has zero chance of solving, or a trivial one it has already mastered, wasting compute. GAIN-RL identifies that by epoch 100, questions with high angle concentration are already mastered, while low-angle ones are not, allowing the scheduler to focus on the latter.
Key Novelty
Gradient-driven Angle-Informed Navigated RL (GAIN-RL)
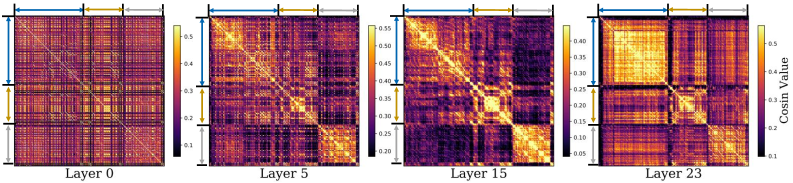
- Identifies 'angle concentration' (cosine similarity between token hidden states) as a cheap proxy for gradient magnitude, indicating how much a model can learn from a sample
- Leverages a 'Data-wise Angle Concentration Pattern': models naturally learn high-concentration samples first, then progress to lower-concentration ones
- Sorts data via a single inference pass (pre-filling) rather than expensive decoding, then dynamically samples data during training to match the model's learning pace
Architecture
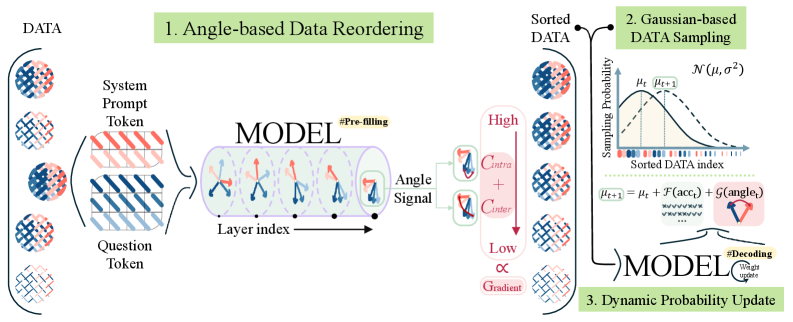
The GAIN-RL framework workflow. Left: Data Reordering via Angle Concentration. Center: Dynamic Gaussian Sampling during training. Right: Probability Update mechanism.
Evaluation Highlights
- Accelerates training efficiency by over 2.5× across diverse mathematical and coding tasks compared to vanilla GRPO
- Achieves better performance using only 50% of the training data compared to standard GRPO with full data (on GSM8K with Qwen-2.5-0.5B-Instruct)
- Preprocessing over 7,000 samples takes under 10 minutes on a single A100 GPU, avoiding the heavy compute cost of previous selection methods
Breakthrough Assessment
8/10
Strong contribution connecting theoretical gradient analysis to a practical, compute-efficient selection metric. The 2.5x speedup and 50% data reduction are significant for the resource-heavy field of LLM reasoning training.