📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning capabilities (Chain-of-Thought)
SPO improves reasoning in LLMs by estimating advantages at the segment level via Monte Carlo sampling, avoiding the instability of token-level critics and the coarseness of trajectory-level sparse rewards.
Core Problem
Existing RL methods for LLMs operate at extreme granularities: token-level methods (PPO) require unstable, expensive critic models, while trajectory-level methods (GRPO) rely on sparse final rewards that fail to assign credit accurately in long reasoning chains.
Why it matters:
- Accurate credit assignment is critical for complex STEM reasoning where a single error can invalidate a long solution
- Training critic models for LLMs is computationally expensive and empirically unreliable due to high variance across prompts
- Coarse-grained trajectory feedback causes models to struggle with identifying specific positive/negative contributions, leading to slow convergence or overfitting
Concrete Example:
In a long mathematical proof, a model might reason correctly for 90% of the steps but fail at the very end. GRPO assigns a negative reward to the entire sequence, discouraging the correct parts. PPO attempts to score every token but often produces noisy values due to critic inaccuracy.
Key Novelty
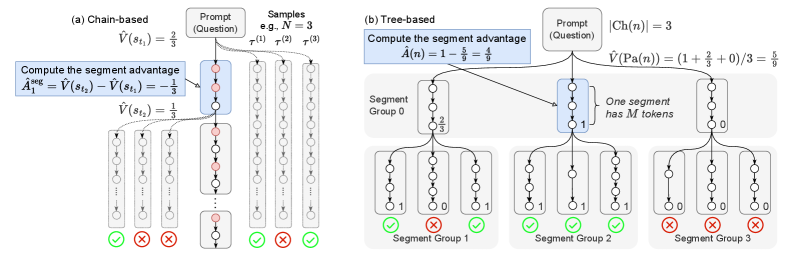
Segment-Level Advantage Estimation via Monte Carlo (SPO)
- Partitions generated sequences into contiguous segments (mid-grained) rather than treating them as single tokens or whole trajectories
- Estimates the value of each segment using Monte Carlo rollouts directly from the policy, eliminating the need for a separate critic model
- Introduces specialized sampling strategies (Chain vs. Tree) to balance computational cost and sample efficiency for short versus long reasoning tasks
Architecture
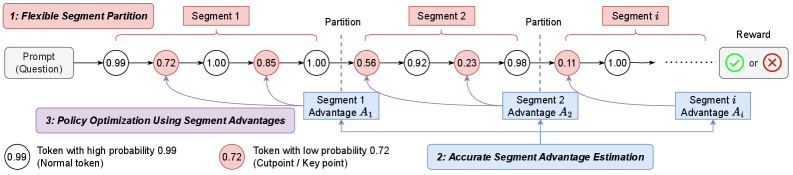
Overview of the SPO framework including Segment Partition, Advantage Estimation, and Policy Optimization.
Evaluation Highlights
- SPO-chain achieves 6–12 percentage point accuracy improvements over PPO and GRPO on the GSM8K benchmark (Short CoT)
- SPO-tree achieves 7–11 percentage point accuracy improvements over GRPO on the MATH500 benchmark (Long CoT) under 2K and 4K context evaluation
- SPO-tree significantly reduces Monte Carlo estimation costs compared to chain-based sampling by reusing samples in a tree structure
Breakthrough Assessment
7/10
Addresses a fundamental granularity trade-off in RLHF/RLAIF. The removal of the critic model while maintaining denser feedback than GRPO is a significant methodological improvement, though results are currently limited to math reasoning benchmarks.