📝 Paper Summary
Reinforcement Learning for Reasoning
Reinforcement Fine-Tuning (RFT)
GPG simplifies reinforcement learning for reasoning by removing critic models and reference policies, instead using group-level reward normalization and a corrected gradient estimator to achieve state-of-the-art performance.
Core Problem
Existing RL methods like PPO and GRPO are complex and resource-intensive, relying on critic models, reference models, or biased advantage estimators that complicate training and limit scalability.
Why it matters:
- PPO requires training separate critic models and maintaining reference models, doubling memory usage and computational cost
- GRPO introduces reward bias through its specific normalization strategy and still relies on KL divergence constraints
- Simplifying RL is crucial for scaling reasoning capabilities to larger models without incurring prohibitive infrastructure costs
Concrete Example:
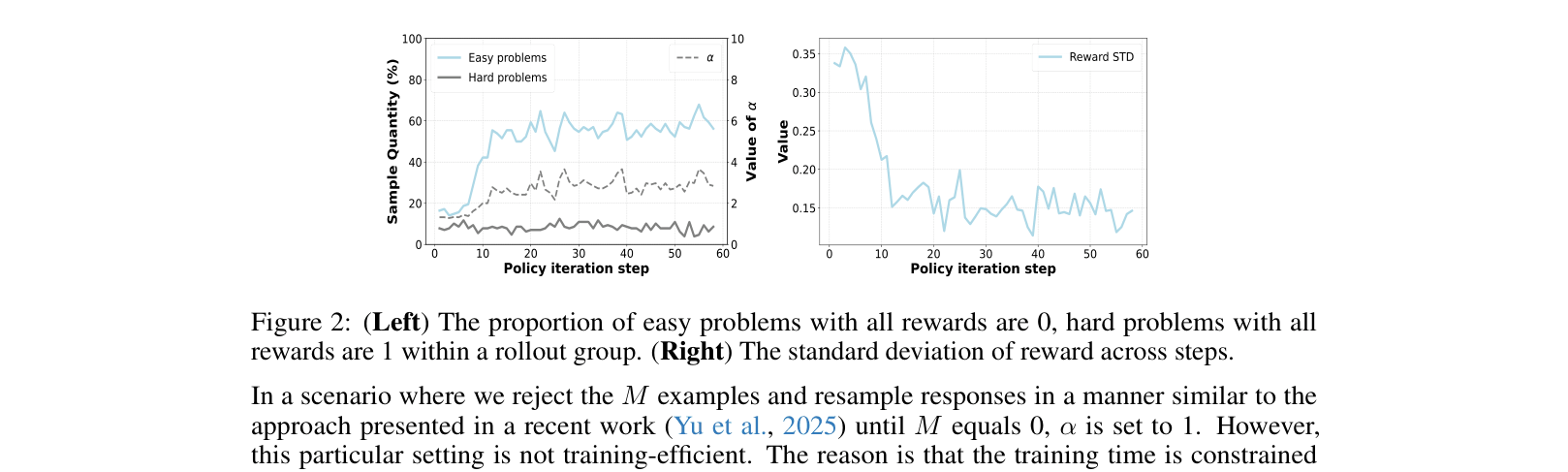
In GRPO, if a batch contains only correct answers (reward=1) or only wrong answers (reward=0), the standard deviation is 0, causing division errors or requiring heuristic fixes. GPG handles this naturally via a thresholding mechanism and accurate gradient estimation.
Key Novelty
Group Policy Gradient (GPG)
- Directly optimizes the RL objective without surrogate losses (like PPO's clip) or KL divergence constraints
- Eliminates the need for a critic model by using group-based reward normalization as the baseline
- Introduces 'Accurate Gradient Estimation' (AGE) to correct bias when samples in a group have identical rewards (all right/wrong), ensuring valid gradient updates
Architecture
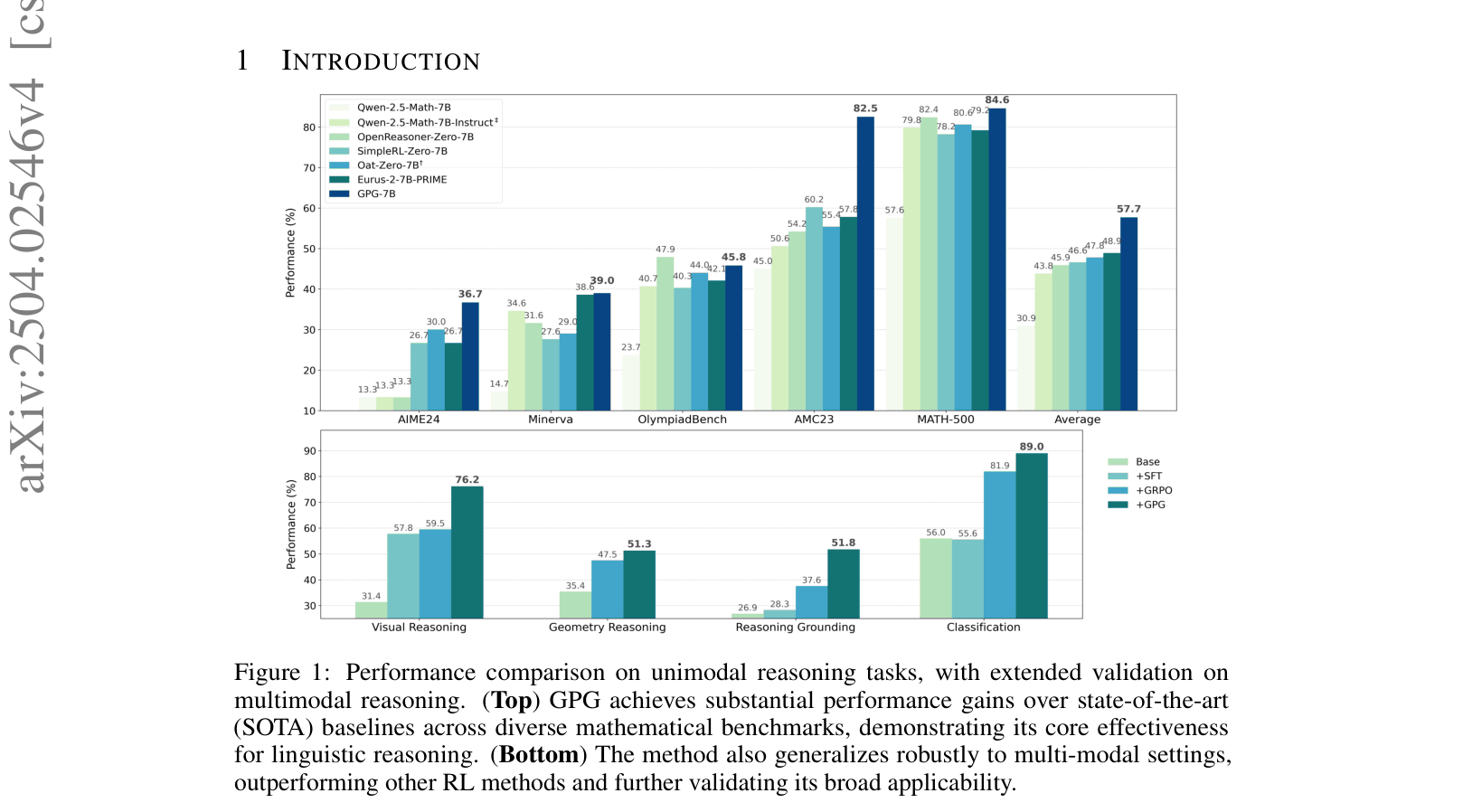
Performance comparison bar charts (Top: Math, Bottom: Multimodal) showing GPG's superiority over baselines.
Evaluation Highlights
- +14.0% improvement over Qwen2.5-Math-7B base model on MATH-500 accuracy (43.7% → 57.7%)
- +9.9% improvement over GRPO baseline on average across 5 math benchmarks using 7B models (47.8% vs 57.7%)
- +16.68% improvement over GRPO on CV-Bench visual reasoning tasks using Qwen2-VL-2B
Breakthrough Assessment
8/10
Significant simplification of RL pipelines (removing critic/ref models) while outperforming complex baselines like GRPO and PPO across diverse modalities. High practical value for efficient training.