📝 Paper Summary
Metrics and evaluation
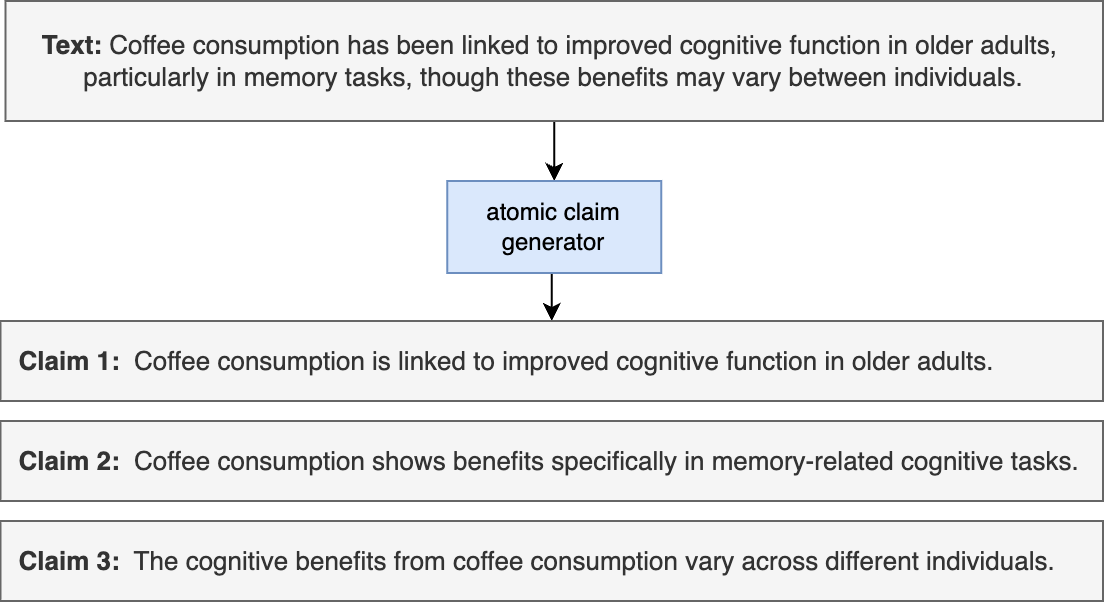
ICAT is a modular evaluation framework that decomposes long-form text into atomic claims to simultaneously measure both factual accuracy and the coverage of diverse aspects of a topic.
Core Problem
Existing evaluation metrics for long-form generation typically focus on isolated dimensions like factuality or surface-level fluency, failing to assess whether a response comprehensively covers diverse relevant perspectives.
Why it matters:
- Applications like medical systems or policy analysis require balanced, complete information; a factually correct but incomplete answer (e.g., listing benefits but omitting side effects) is misleading
- Current metrics like ROUGE or BERTScore cannot verify factuality or semantic coverage, while newer factuality metrics (FActScore) ignore information completeness
- Optimizing for factuality alone might encourage models to produce short, safe, but uninformative responses
Concrete Example:
If a user asks 'What are the health effects of coffee?', an LLM might list only benefits (alertness, disease protection). While factually true, this response is incomplete because it omits risks (anxiety, sleep disruption), presenting a biased view that current metrics would not penalize.
Key Novelty
Information Coverage and Accuracy for Text generation (ICAT)
- Decomposes long text into atomic claims, verifies each against a knowledge source, and aligns verified claims to specific topic aspects to calculate a unified score
- Introduces a weighted harmonic mean of 'Factuality Score' (ratio of accurate claims) and 'Coverage Score' (ratio of covered aspects), penalizing accurate but narrow responses
- Provides three implementation variants (ICAT-M, ICAT-S, ICAT-A) ranging from fully manual ground-truth reliance to fully automated LLM-based aspect generation and alignment
Architecture
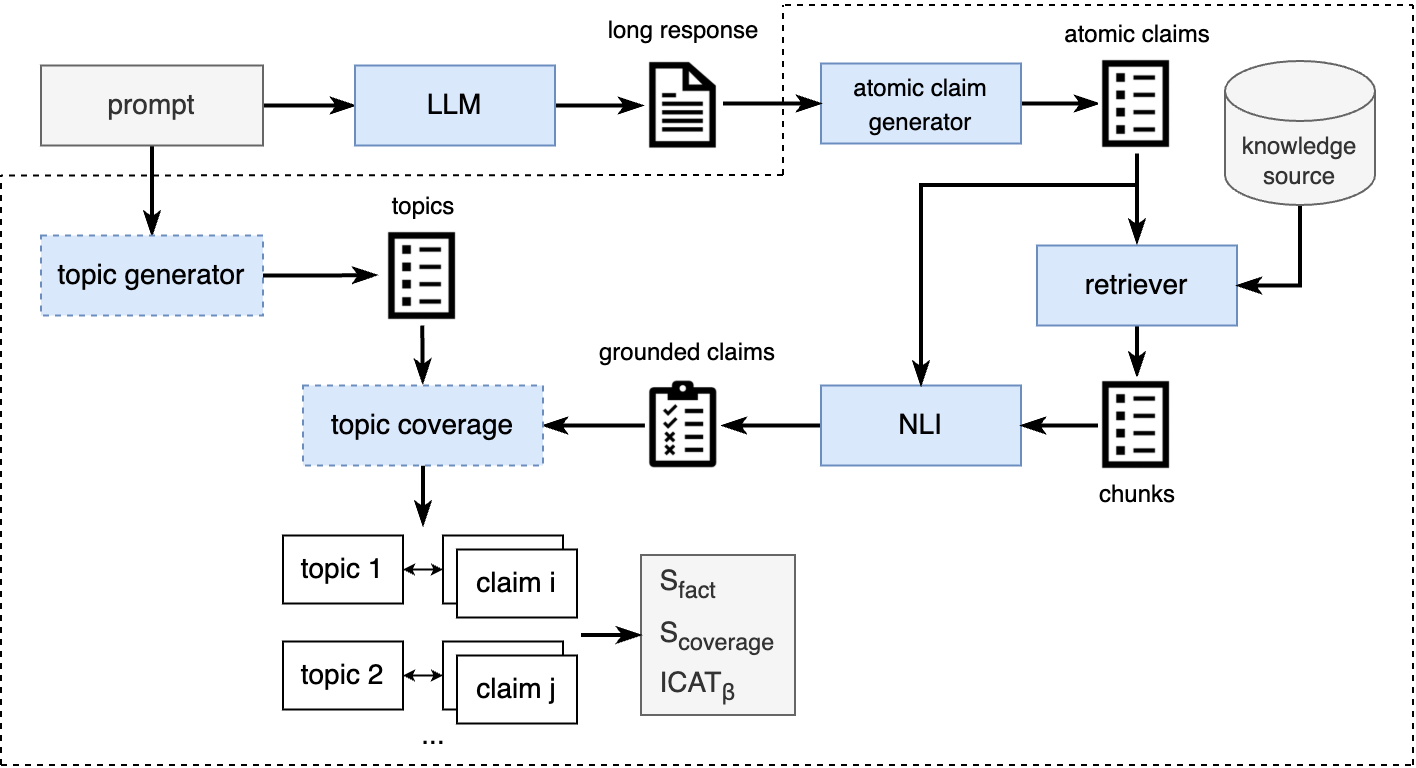
The ICAT framework workflow (implied from text description).
Evaluation Highlights
- ICAT correlates strongly with human judgments, demonstrating its utility for automated evaluation without human input
- Llama-3-70B achieves the highest ICAT scores among open models with Web-based retrieval (0.714 Factuality, 0.556 Coverage)
- GPT-4 shows superior performance with Web-based retrieval (0.748 Factuality, 0.551 Coverage), outperforming smaller models like Openchat 3.5
Breakthrough Assessment
8/10
Significant contribution by unifying factuality and coverage into a single interpretable metric. Addresses a critical blind spot in current LLM evaluation (omission bias) with a practical, modular framework.