📝 Paper Summary
Math Reasoning
LLM Alignment
Online Learning
NFT enables language models to learn from their own errors via a supervised objective that implicitly models a negative policy, achieving performance comparable to reinforcement learning without explicit reward maximization.
Core Problem
Supervised Learning (SL) methods like Rejection Fine-Tuning (RFT) typically discard incorrect self-generated answers, preventing models from reflecting on mistakes, while Reinforcement Learning (RL) handles them but adds complexity.
Why it matters:
- Throwing away negative data wastes valuable feedback signals that are critical for self-reflection and general intelligence
- The prevailing view that 'self-improvement is exclusive to RL' creates an artificial divide between SL and RL methodologies
- Existing SL methods hit a competence ceiling by reinforcing only what the model already knows (positive data) rather than correcting what it gets wrong
Concrete Example:
In RFT, if a model generates 1 correct solution and 9 incorrect ones, it trains only on the 1 correct solution and ignores the 9 mistakes. NFT uses the 9 mistakes to explicitly push the model's probability distribution away from those errors.
Key Novelty
Negative-aware Fine-Tuning (NFT)
- Constructs an 'implicit negative policy'—a mathematical re-parameterization of the target positive model—to model the distribution of incorrect answers
- Derives a supervised-style loss function for negative data that directly optimizes the positive model by minimizing the likelihood of errors, weighted by their probability ratio
- Demonstrates that this supervised approach is theoretically equivalent to the RL algorithm GRPO (Group Relative Policy Optimization) in strict on-policy settings
Architecture
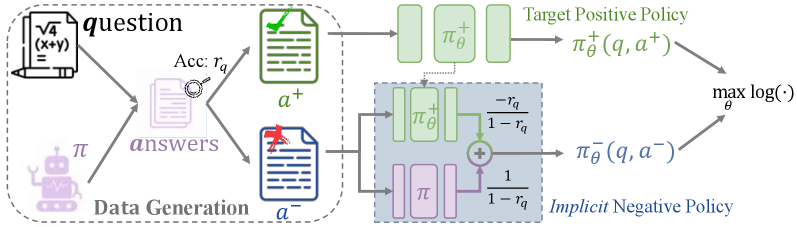
The conceptual framework of NFT compared to RFT and RL. It illustrates how NFT uses the 'Implicit Negative Policy' to derive a learning signal from negative answers.
Evaluation Highlights
- Learning from positive data (RFT) contributes ~80% of total performance gain in 32B models, while negative data (NFT) contributes the remaining ~20%
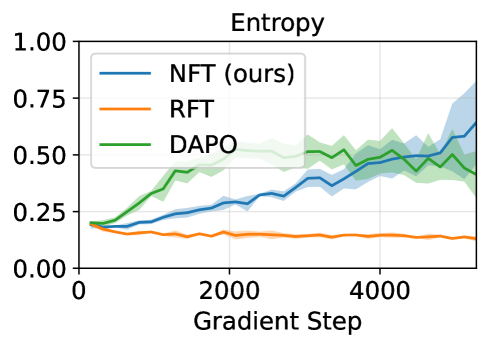
- NFT matches or surpasses state-of-the-art RL algorithms like GRPO and DAPO across 7B and 32B model scales
- Proves theoretical equivalence: NFT and GRPO loss gradients are identical when training is strictly on-policy (epsilon <= 1)
Breakthrough Assessment
8/10
Significantly bridges the gap between SL and RL, offering a simpler supervised framework that achieves RL-level performance and providing theoretical proof of their equivalence in on-policy settings.