📝 Paper Summary
Reinforcement Learning for LLMs
Mathematical Reasoning
RePO improves the data efficiency of Group Relative Policy Optimization by supplementing on-policy updates with off-policy samples retrieved from a replay buffer using diverse strategies like recency or reward maximization.
Core Problem
Group Relative Policy Optimization (GRPO) is computationally expensive due to requiring multiple on-policy samples per step and suffers from vanishing gradients when all samples yield identical rewards.
Why it matters:
- High computational costs of on-policy sampling limit the scalability of RL for Large Language Models
- When an LLM produces samples with uniform rewards (all correct or all incorrect), GRPO estimates zero advantage, providing no learning signal to improve the model
- Relying solely on current policy samples leads to data inefficiency and potential overfitting to limited recent experiences
Concrete Example:
If a current policy generates 8 outputs for a math problem and all are incorrect (reward 0), the relative advantage for each is 0. The model receives no gradient to correct its behavior, effectively wasting the computational cost of generation.
Key Novelty
Replay-Enhanced Policy Optimization (RePO)
- Integrates an off-policy update term into the GRPO objective, allowing the model to learn from previously generated samples stored in a replay buffer
- Employ diverse replay strategies (e.g., maximizing reward, variance, or recency) to select the most effective past samples for current optimization
- Uses a 'Split' advantage estimation strategy that calculates advantages separately for on-policy and off-policy batches to prevent interference
Architecture
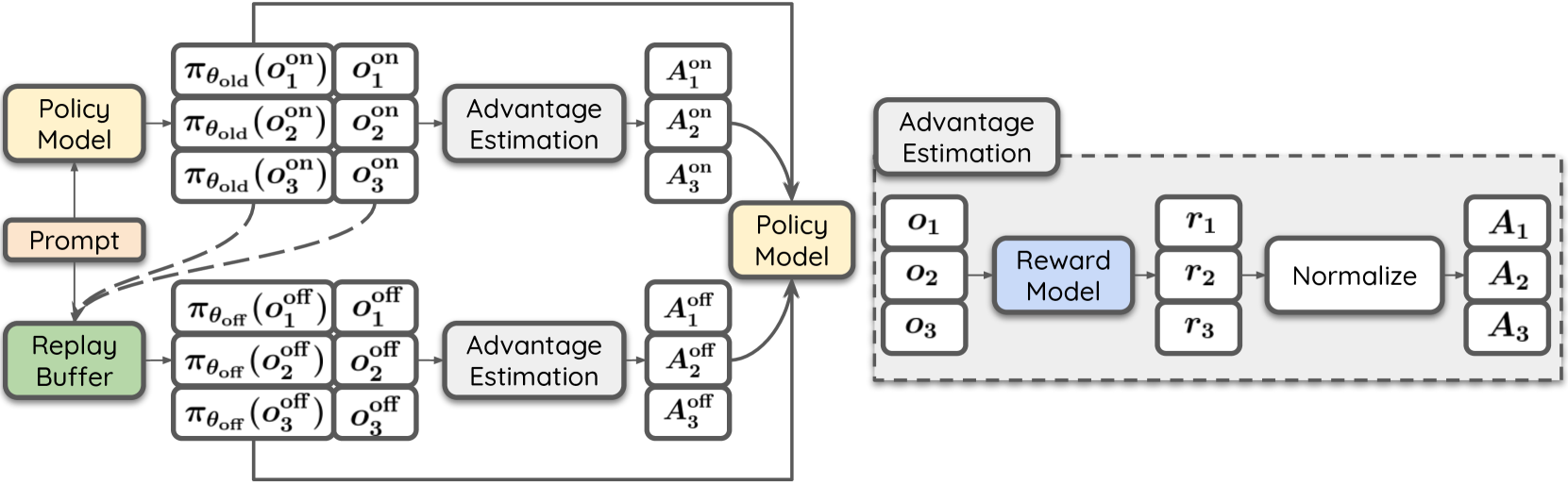
Overview of RePO optimization process involving on-policy and off-policy updates
Evaluation Highlights
- +18.4 absolute average accuracy gain on math benchmarks for Qwen2.5-Math-1.5B compared to GRPO
- +4.1 absolute average accuracy gain for Qwen3-1.7B compared to GRPO across seven mathematical reasoning benchmarks
- Increases effective optimization steps by 48% while only increasing computational cost by 15% on Qwen3-1.7B (normalized against GRPO baseline)
Breakthrough Assessment
7/10
Significant performance gains and efficiency improvements over the state-of-the-art GRPO method for math reasoning. The approach is a logical extension of RL principles (replay buffers) to the specific GRPO setting.