📝 Paper Summary
Reinforcement Learning for LLMs
Policy Optimization Algorithms
SFPO stabilizes reasoning training by splitting updates into a fast exploration trajectory on the same batch, a repositioning step to control drift, and a final slow correction.
Core Problem
On-policy RL algorithms like GRPO suffer from noisy gradients and instability in early training because one-shot updates underutilize batch data while naive reuse leads to off-policy drift.
Why it matters:
- Noisy gradients from low-quality early rollouts cause training instability and inefficient exploration
- Discarding batch data after a single update step is sample-inefficient, requiring excessive rollouts to converge
- Simply applying multiple updates to the same batch (naive off-policy) introduces distribution mismatch that degrades performance
Concrete Example:
In early training, if a batch yields weak reasoning chains with stochastic rewards, a single GRPO update might step in a high-variance direction. Naively taking multiple steps on this noisy batch moves the policy too far from the data-generating distribution (drift), damaging future convergence.
Key Novelty
Fast-Reposition-Slow Update Mechanism
- Decomposes each iteration into a 'fast trajectory' of multiple inner updates to stabilize direction, followed by a 'reposition' step that interpolates back toward the original policy to curb drift
- Uses an entropy-based schedule to dynamically disable the repositioning mechanism near convergence, reverting to standard on-policy updates when noise dominates signal
Architecture
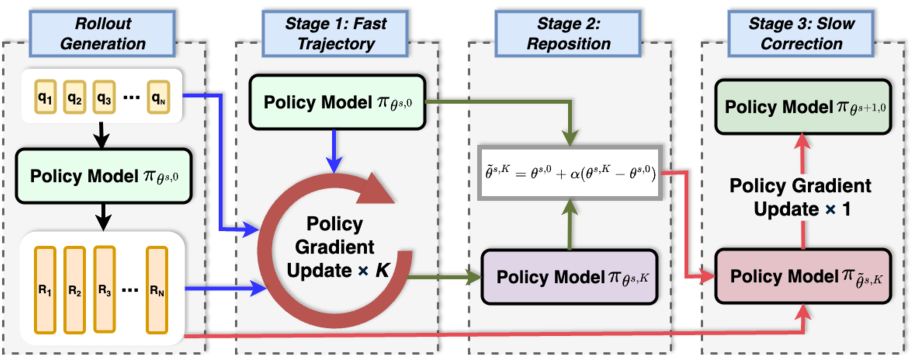
Conceptual diagram of the Slow-Fast Policy Optimization update trajectory in parameter space.
Evaluation Highlights
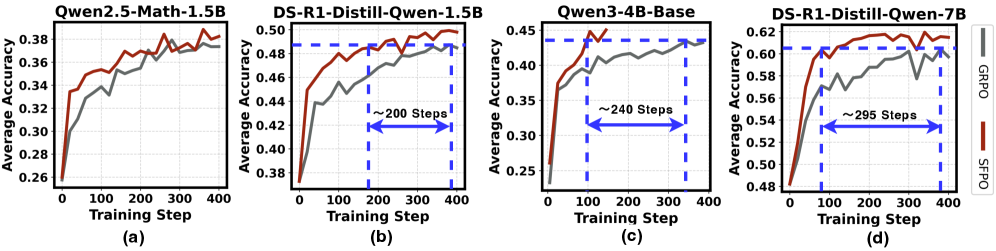
- +2.80 average accuracy improvement on math benchmarks for DeepSeek-R1-Distill-Qwen-1.5B compared to GRPO
- Up to +7.5 absolute accuracy gain on the challenging AIME25 benchmark with DeepSeek-R1-Distill-Qwen-1.5B
- Reduces wall-clock training time by up to 4.19x and requires 4.93x fewer rollouts to match GRPO's best accuracy
Breakthrough Assessment
7/10
Significant efficiency and stability gains over GRPO, a standard industry baseline. The method is a plug-and-play optimization improvement rather than a fundamental architectural shift.