📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Post-training of Large Language Models
Optimization Theory
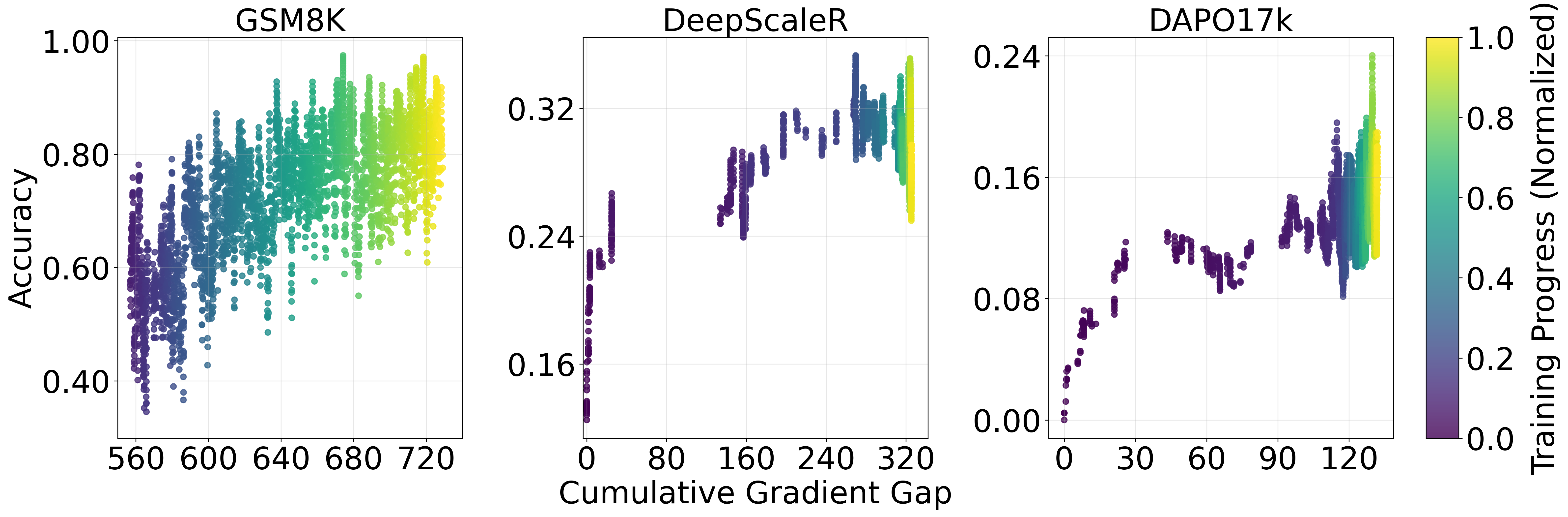
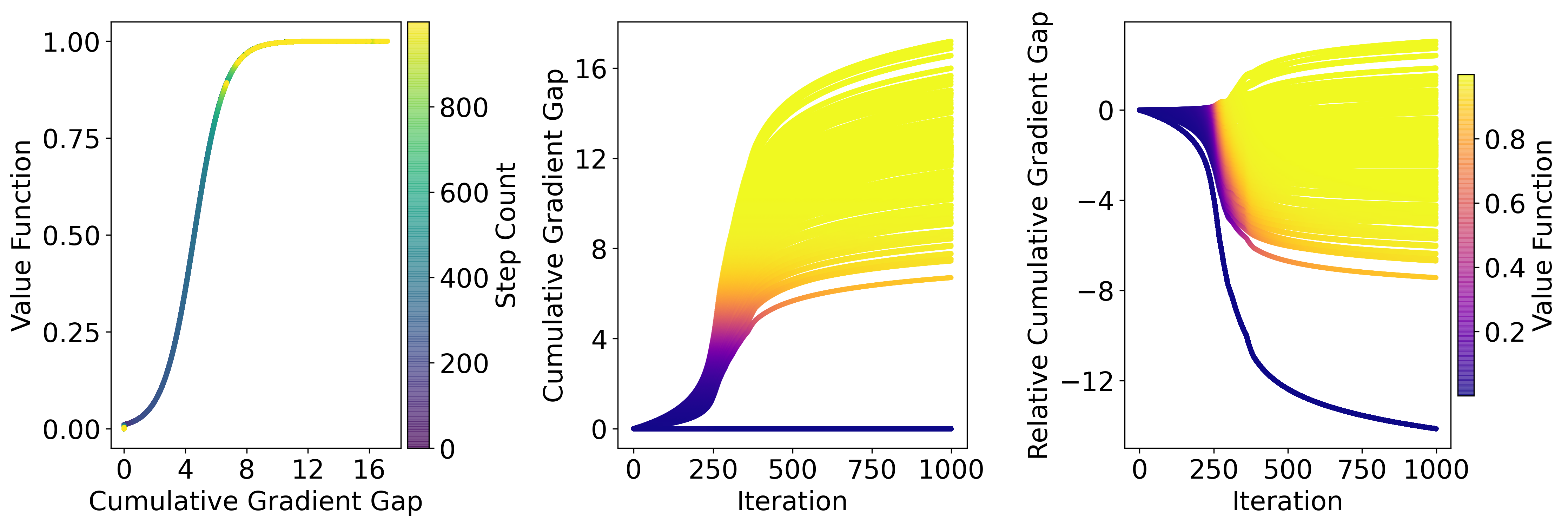
The paper provides a theoretical framework for RLVR, proving that convergence depends on aligning updates with a 'Gradient Gap' and that step sizes must be scaled by response length and success rates to prevent collapse.
Core Problem
RLVR methods like GRPO are empirically successful but lack theoretical understanding, particularly regarding why specific heuristics (like length normalization) work and how to choose hyperparameters to avoid instability.
Why it matters:
- Practitioners currently rely on trial-and-error for critical hyperparameters, which can lead to catastrophic collapse or stagnation
- Sparse binary rewards (pass/fail) make it difficult to analyze how gradient descent navigates the parameter space compared to dense reward settings
- Heuristics like length normalization are widely used in state-of-the-art models (e.g., DeepSeek-R1) but have lacked principled justification until now
Concrete Example:
When fine-tuning a model on math problems, an overly aggressive step size that doesn't account for response length might cause the model to overshoot the optimal policy, leading to a collapse where the probability of correct answers strictly decreases to zero instead of improving.
Key Novelty
Gradient Gap Optimization Framework
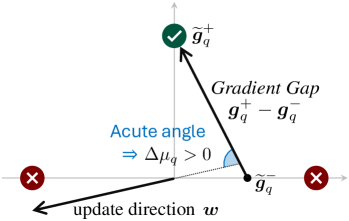
- Introduces 'Gradient Gap' to quantify the direction of improvement from low-reward to high-reward regions in response space, distinct from the raw policy gradient
- Derives a sharp step-size threshold based on the Gradient Gap magnitude; updates below this threshold converge, while updates above it cause performance collapse
- Theoretically validates practical heuristics by showing effective learning rates must scale inversely with response length and adapt to the current success rate
Architecture
Conceptual illustration of the Gradient Gap. It shows the response space partitioned into Correct (O+) and Incorrect (O-) regions. The Gradient Gap vector points from the average incorrect response gradient to the average correct response gradient.
Evaluation Highlights
- Validates theory by fine-tuning Qwen2.5-Math-7B on GSM8K, showing that exceeding the theoretical step size threshold triggers immediate performance collapse
- Demonstrates that length normalization (dividing updates by token count) stabilizes training by keeping the effective step size within the safe convergence region
- Proves that with a fixed learning rate, the success rate can stagnate strictly below 100% due to vanishing gradients, necessitating adaptive scheduling
Breakthrough Assessment
8/10
Provides the first rigorous theoretical foundation for GRPO and RLVR heuristics. While it doesn't propose a new SOTA algorithm, it explains *why* current SOTA methods work and how to tune them, which is high-impact.