📝 Paper Summary
Mathematical Reasoning
Reinforcement Learning from Human Feedback (RLHF)
ScRPO improves mathematical reasoning in LLMs by actively collecting errors during exploration and training the model to reflect on and correct those specific mistakes using targeted reward attribution.
Core Problem
Standard reinforcement learning methods like GRPO maximize rewards but fail to learn from mistakes, often ignoring the specific reasoning flaws behind incorrect answers.
Why it matters:
- Current RL methods (GRPO) waste data from incorrect attempts, providing minimal learning signal from failed trajectories
- Scalar rewards do not explain *why* a reasoning step was wrong, limiting the model's ability to diagnose and fix conceptual errors
- Models struggle to generalize to high-difficulty problems because they lack the human-like capability to introspectively analyze and correct their own logic
Concrete Example:
In a multi-step math problem, a model might make a calculation error in step 2. Standard GRPO just gives a zero reward for the final answer. ScRPO forces the model to take that specific incorrect trajectory, generate a 'Analysis' of why it was wrong, and then a 'Corrected Solution', applying gradient updates only if the correction logic is sound.
Key Novelty
Self-correction Relative Policy Optimization (ScRPO)
- Two-stage iterative training: first exploring to find 'informative' errors (neither too hard nor too easy), then switching to a self-correction stage to fix them
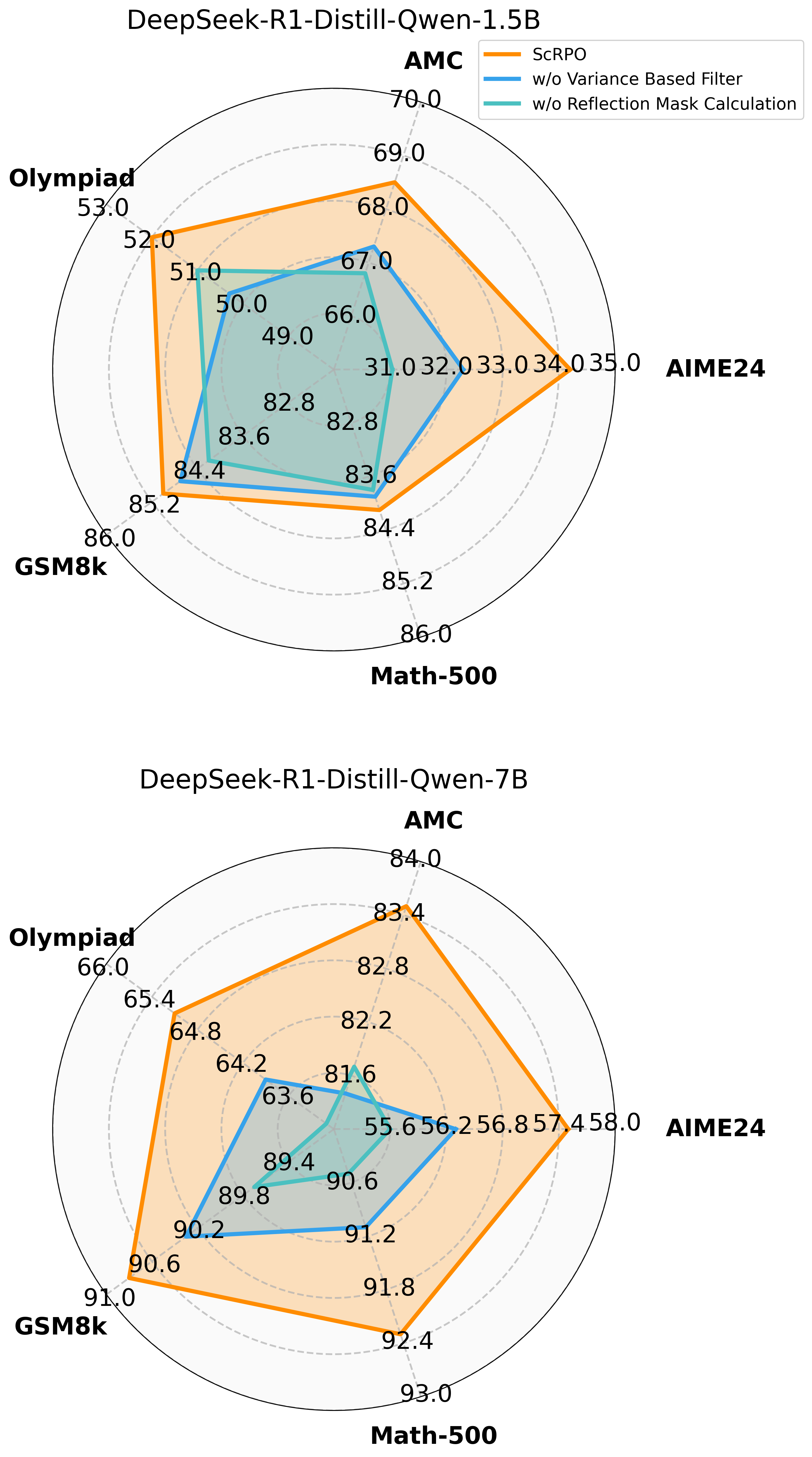
- Variance-Based Filter: Automatically identifies problems at the model's knowledge boundary (where it is inconsistent) to populate the error pool, maximizing learning efficiency
- Success-Conditioned Gradient Attribution: When the model successfully corrects an error, gradients are backpropagated *only* through the reflection/analysis tokens, specifically reinforcing the ability to diagnose faults.
Architecture
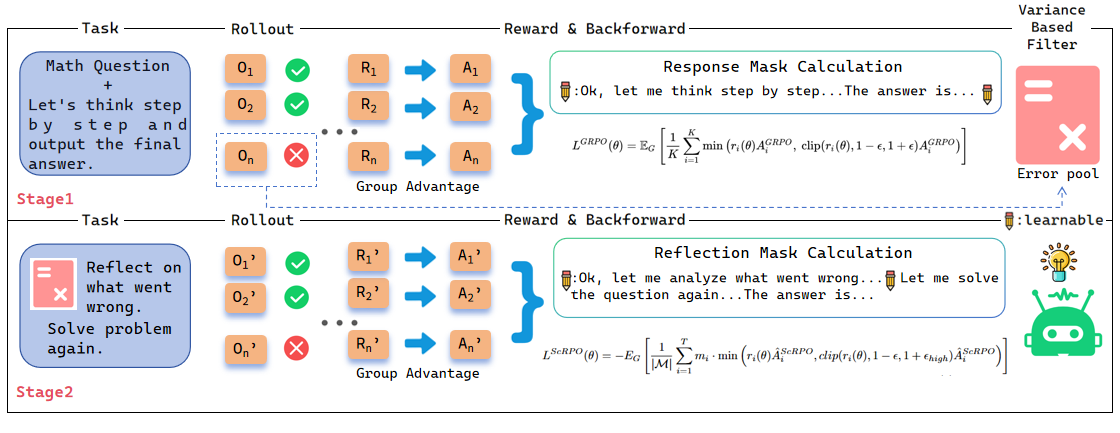
The complete ScRPO training pipeline with its two alternating stages.
Evaluation Highlights
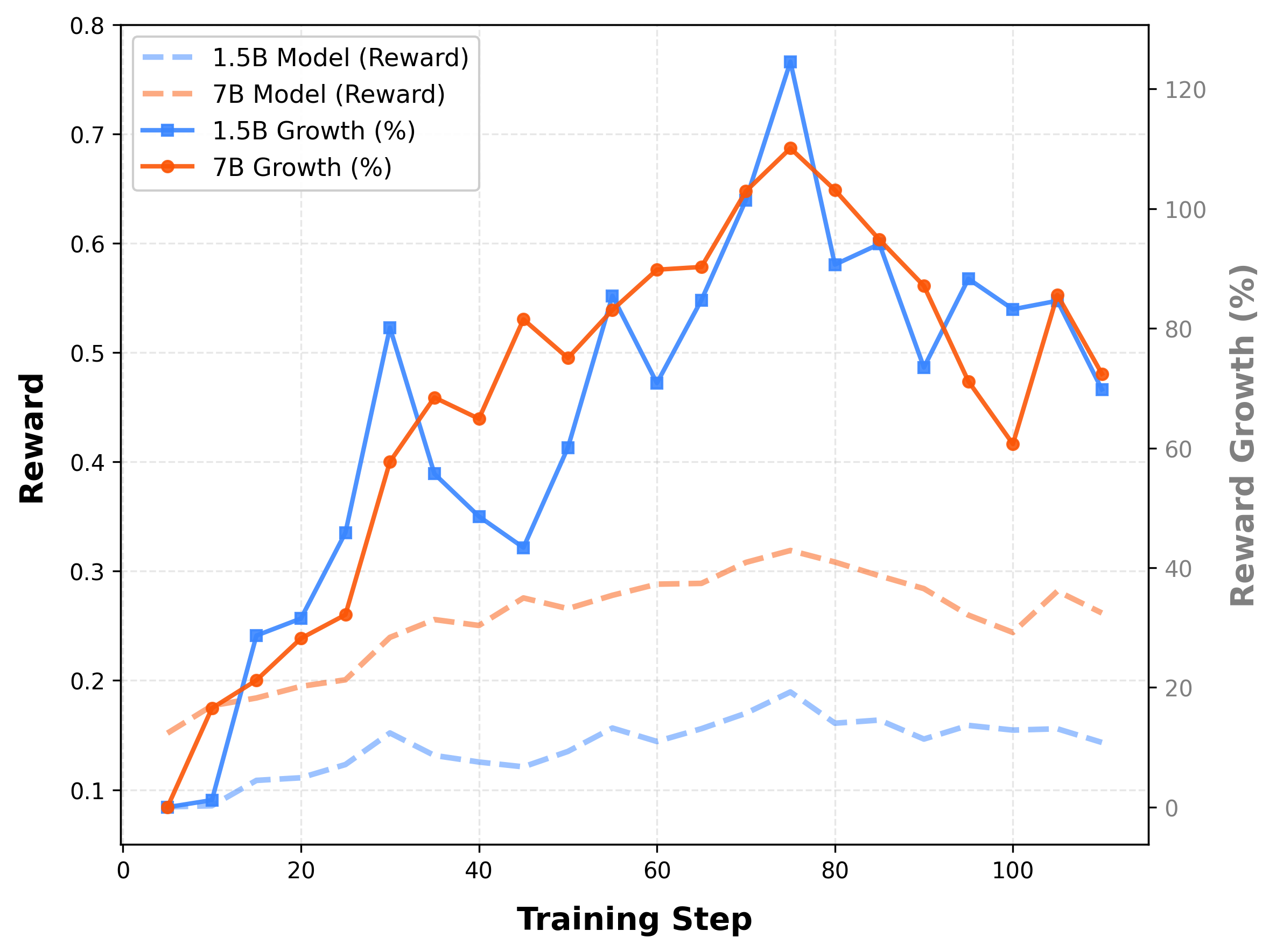
- +6.0% average accuracy improvement over vanilla DeepSeek-R1-Distill-Qwen-1.5B across 5 math benchmarks
- +5.7% improvement on the challenging AIME-2024 benchmark (1.5B model), significantly outperforming standard GRPO (+3.4%) and DAPO (+4.5%)
- Consistent gains across model scales: the 7B model achieves 77.8% average accuracy (+3.2% over vanilla baseline), validating the method's scalability
Breakthrough Assessment
8/10
Strong empirical results on hard math benchmarks with a methodologically distinct approach (learning from errors via targeted masking). Effectively addresses the 'wasted negative sample' problem in RLHF.