📝 Paper Summary
Reinforcement Learning for LLMs
Post-training Optimization
OAPL is an off-policy RL algorithm that enables reasoning models to learn effectively from lagged inference data by optimizing a regression objective rather than using unstable importance sampling.
Core Problem
Standard RL post-training (like GRPO) assumes on-policy data, but system constraints (distributed lag, different kernels) cause the inference policy to differ from the training policy, breaking this assumption.
Why it matters:
- Infrastructure mismatches (e.g., vLLM vs HuggingFace) cause log-probability discrepancies, destabilizing training
- Synchronous training is slow; forcing the inference engine to stay perfectly synced with the trainer introduces bottlenecks
- Current fixes like Importance Sampling (IS) introduce high variance or require complex heuristics like clipping and token deletion
Concrete Example:
In an asynchronous setup, the inference engine generating math solutions might be 400 gradient steps behind the trainer. GRPO would fail or require massive importance sampling corrections because the data is 'stale', whereas OAPL treats this lag as a natural part of the learning process.
Key Novelty
Optimal Advantage-based Policy Optimization with Lagged Inference (OAPL)
- Treats the policy mismatch as a KL-regularized RL problem where the optimal solution has a known closed form
- Derives a squared regression loss that pulls the training policy toward the optimal policy without needing importance sampling ratios
- Intentionally lags the inference policy, syncing it with the trainer only infrequently, to maximize generation throughput without instability
Architecture
The asynchronous training loop of OAPL.
Evaluation Highlights
- Matches performance of DeepCoder on LiveCodeBench while using ~3x fewer generations during training
- Maintains effective training with policy lags of >400 gradient steps (100x more off-policy than prior approaches)
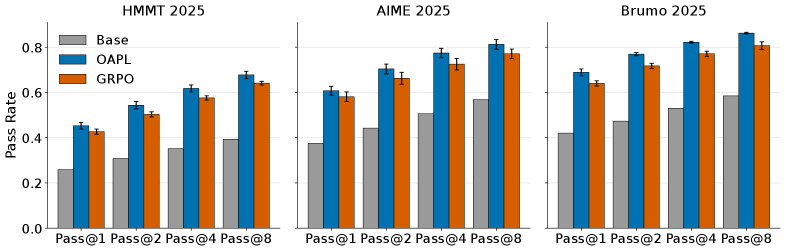
- Outperforms GRPO with Importance Sampling on AIME 2025 and HMMT 2025 math benchmarks
Breakthrough Assessment
8/10
Provides a principled, theoretically grounded solution to the practical 'policy lag' problem in distributed LLM training, eliminating the need for brittle importance sampling heuristics.