📝 Paper Summary
Radiology Report Generation (RRG)
Medical Vision-Language Models
Reinforcement Learning with Human Feedback (RLHF)
OraPO enables data-efficient radiology report generation by converting failed reinforcement learning explorations into direct preference supervision, guided by a clinical fact-checking reward system.
Core Problem
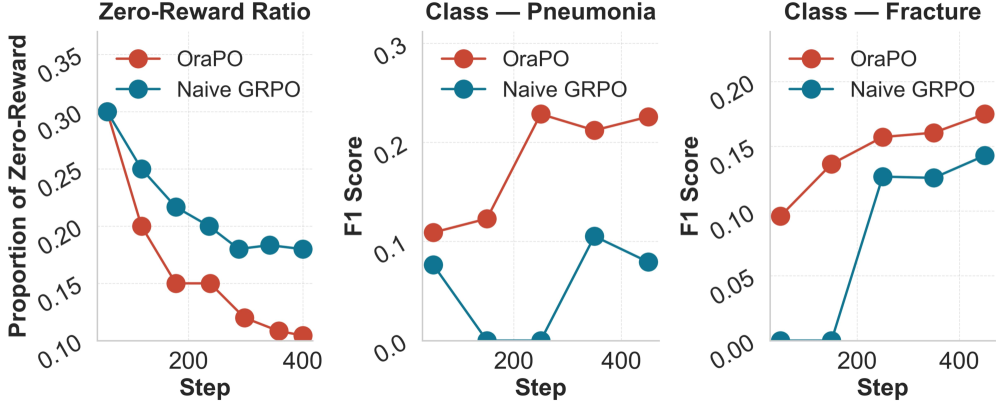
Standard RL (GRPO) fails in radiology generation because base models lack medical knowledge, producing 'zero-reward' outputs that provide no learning signal, while existing metrics (BLEU) fail to capture clinical factual correctness.
Why it matters:
- Radiologist shortages (29% shortfall in England) create urgent need for automated drafting, but current methods require massive, curated datasets (>200K pairs) and large compute.
- Existing rewards reward fluent but factually incorrect hallucinations (missed positives, unsupported claims), which are dangerous in healthcare.
- Vanilla GRPO wastes compute on 'all-zero' reward groups, causing vanishing gradients and stalled training in domain-specific tasks.
Concrete Example:
A base VLM might miss a 'subtle interstitial edema' in a chest X-ray. GRPO samples 8 reports, all failing to mention it, resulting in zero reward for the entire group. Standard GRPO discards this batch (no gradient), wasting compute. OraPO effectively says 'These 8 were bad compared to the ground truth' and updates the model to avoid them.
Key Novelty
Oracle-educated Group Relative Policy Optimisation (OraPO)
- Detects when the model fails to explore (Zero-Reward Rate) and dynamically switches from pure RL to Direct Preference Optimization (DPO).
- Reuses failed RL rollouts as 'negative' samples and the ground truth as the 'positive' sample for the DPO update, turning wasted compute into supervision.
- Introduces FactS Reward: instead of text overlap, it extracts atomic clinical facts from the report and checks entailment against ground-truth labels for a dense, interpretable signal.
Architecture
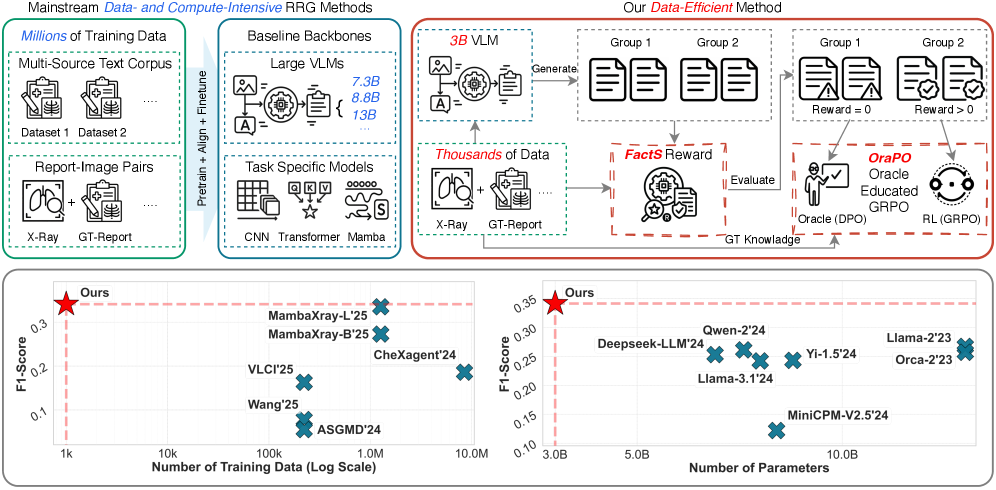
Comparison of the standard Multi-stage SFT paradigm vs. the proposed OraPO Single-stage RL paradigm.
Evaluation Highlights
- Achieves new SOTA F1 score of 0.357 on MIMIC-CXR and 0.341 on CheXpert Plus using only 1K training samples.
- Outperforms the previous best model (MambaXray-L) while using 2-3 orders of magnitude less data (1K vs 1.27M samples).
- Achieves a 160.8% improvement in recall compared to the baseline, significantly reducing clinically dangerous false negatives.
Breakthrough Assessment
9/10
Achieving SOTA with 1,000 samples versus 1.27 million is a massive efficiency breakthrough. Successfully adapting GRPO for domain-specific exploration failures addresses a major limitation in applying modern RL to specialized fields.