📝 Paper Summary
Large Reasoning Models (LRMs)
Efficient Inference
Reinforcement Learning for Reasoning
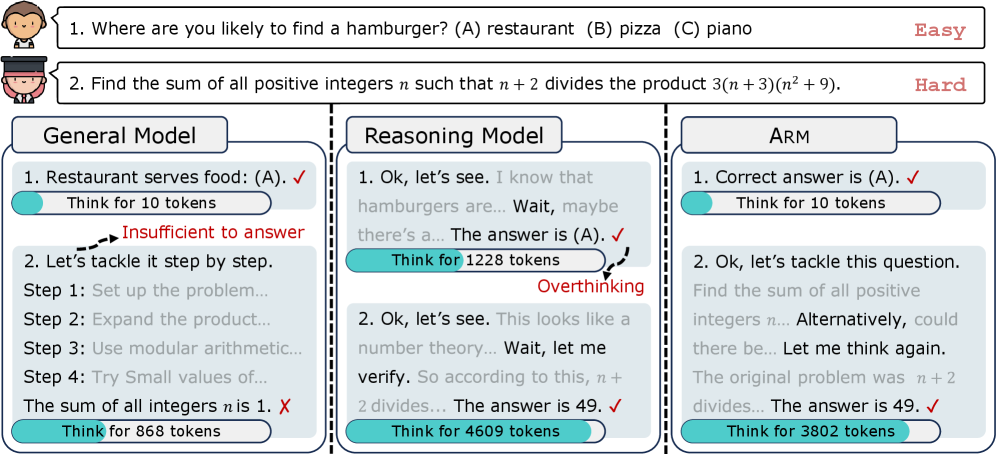
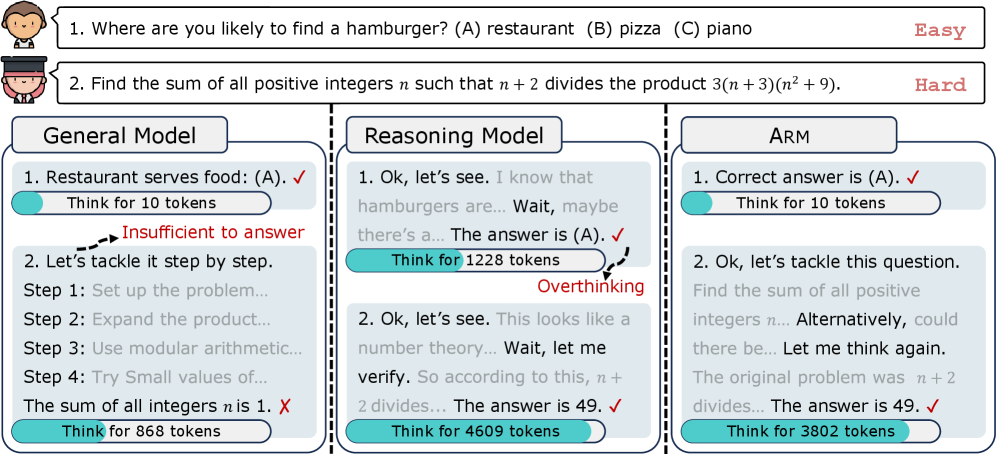
Arm addresses the 'overthinking' problem in reasoning models by using Ada-GRPO to train the model to adaptively select the most efficient reasoning format (from Direct Answer to Long CoT) based on task difficulty.
Core Problem
Large reasoning models (LRMs) like OpenAI-o1 apply Long Chain-of-Thought (Long CoT) uniformly to all tasks, wasting computational resources on easy problems ('overthinking') and potentially introducing noise.
Why it matters:
- Inefficiency: Models consume excessive tokens (and cost) for simple queries that don't require complex reasoning
- Format Collapse: Standard RL training (GRPO) tends to over-optimize for the highest-accuracy format (Long CoT), leading models to lose the ability to answer concisely
- Current mitigation strategies rely on inaccurate manual token budgets or separate length-constrained models rather than autonomous adaptation
Concrete Example:
For an easy commonsense question (e.g., 'What is the color of the sky?'), a standard reasoning model might generate hundreds of tokens of reasoning (Long CoT) before answering, whereas a Direct Answer is sufficient and cheaper. Conversely, complex math requires Long CoT. Standard models cannot switch between these autonomously.
Key Novelty
Adaptive Reasoning Model (Arm) trained via Ada-GRPO
- Trains a single model to autonomously select one of four formats (Direct Answer, Short CoT, Code, Long CoT) based on the input prompt's difficulty
- Introduces Ada-GRPO (Adaptive Group Relative Policy Optimization), which modifies the reward function to encourage format diversity early in training
- Uses a time-decaying diversity factor that initially rewards using less-frequent formats to prevent 'format collapse' to Long CoT, then gradually shifts focus purely to accuracy
Architecture
Conceptual illustration of Adaptive Reasoning. It contrasts fixed Long CoT (used by standard models) with Arm's adaptive selection.
Evaluation Highlights
- Reduces inference token usage by an average of ~30% (and up to ~70% on easy tasks) compared to models relying solely on Long CoT
- Achieves comparable accuracy to standard GRPO-trained models (within 1% difference) while using significantly fewer tokens
- Instruction-Guided Mode (explicitly forcing Long CoT) achieves 74.5% accuracy on Arm-7B, outperforming the same backbone trained with standard GRPO (73.2%)
Breakthrough Assessment
8/10
Significant contribution to reasoning efficiency. Successfully addresses the 'overthinking' problem and 'format collapse' in RL training without sacrificing accuracy, offering a practical Pareto improvement for LRMs.