📝 Paper Summary
Sovereign LLMs
Low-resource post-training
Multilingual adaptation
Typhoon-S is a minimal post-training recipe that combines supervised fine-tuning, on-policy distillation, and knowledge-injected reinforcement learning to adapt base models for sovereign capabilities using limited compute.
Core Problem
Developing state-of-the-art LLMs typically requires massive compute and data resources inaccessible to sovereign entities (nations/regions), while existing open weights lack specific regional capabilities (e.g., local legal reasoning).
Why it matters:
- Sovereign entities need control over model weights and training data for high-stakes local tasks (e.g., legal, cultural) but cannot afford standard industry-scale training
- Standard post-training pipelines rely on massive general-purpose corpora that under-represent low-resource languages, leading to poor performance on region-specific tasks
- Resource gatekeeping prevents academic and national groups from transforming base models into capable assistants
Concrete Example:
A sovereign-adapted base model might perform well on Thai multiple-choice exams but fails completely at general instruction following or tool use (e.g., scoring 0 on Agentic tasks) because it lacks the massive alignment data used by frontier models.
Key Novelty
Typhoon-S Post-Training Recipe & InK-GRPO
- Combines lightweight Supervised Fine-Tuning (SFT) with On-Policy Distillation (OPD), where the student model learns from a teacher's distribution on its *own* generated outputs to correct errors dynamically
- Introduces InK-GRPO (Injected Knowledge GRPO), which adds a next-token prediction loss to the reinforcement learning objective, allowing the model to learn new domain knowledge while optimizing for reasoning performance
Architecture
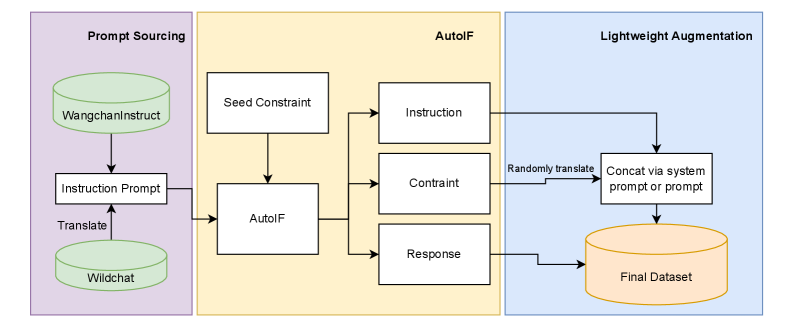
The data construction pipeline for the Thai target-language dataset
Evaluation Highlights
- +6.49 points improvement in average score (37.45 → 43.94) when adding On-Policy Distillation (OPD) to standard SFT on Qwen3 8B Instruct
- +28.0 points improvement on Thai Code-Switching consistency (65.4 → 93.4) using the full SFT+OPD recipe compared to SFT alone
- Typhoon-S-8B outperforms the strong baseline Qwen3-8B on Thai-specific benchmarks (Avg 71.20 vs. 66.66) while using only academic-scale compute
Breakthrough Assessment
8/10
Provides a practical, low-resource blueprint for 'sovereign' AI that is highly relevant for non-English/Chinese contexts. The InK-GRPO method addresses the specific challenge of teaching knowledge during RL.