📝 Paper Summary
Memory-Efficient Fine-Tuning
Zeroth-Order Optimization
Mathematical Reasoning
ESSAM integrates Sharpness-Aware Maximization into Evolution Strategies to fine-tune LLMs for mathematical reasoning, achieving performance comparable to gradient-based RL while using only inference-level GPU memory.
Core Problem
Reinforcement Learning (RL) fine-tuning for LLMs requires prohibitive GPU memory due to gradient and optimizer state storage, while existing memory-efficient Evolution Strategies (ES) suffer from poor generalization on complex tasks.
Why it matters:
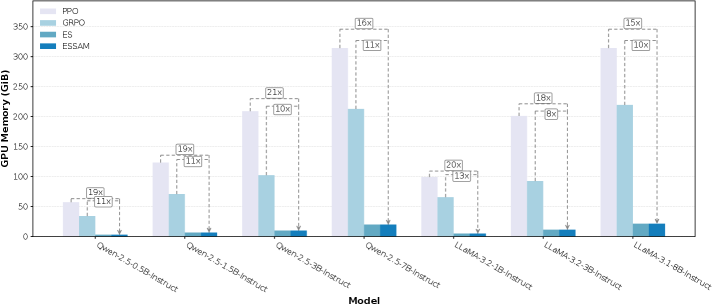
- Fine-tuning an 8B model with PPO requires ~314 GB of GPU memory, making it inaccessible to researchers with limited resources
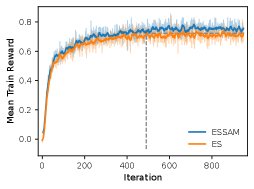
- Standard zeroth-order methods (ES) tend to converge to sharp minima in the loss landscape, leading to brittle solutions that fail on unseen mathematical problems
- Bridging the gap between memory efficiency and reasoning performance is critical for democratizing LLM alignment
Concrete Example:
When fine-tuning LLaMA-3.1-8B on GSM8K, PPO consumes hundreds of gigabytes of memory. Standard ES fits in memory but achieves lower accuracy (75.97% avg). ESSAM fits in memory and matches PPO performance (78.27% avg).
Key Novelty
Evolution Strategies with Sharpness-Aware Maximization (ESSAM)
- Introduces a 'look-ahead' step to zeroth-order optimization: instead of updating parameters directly based on current rewards, the method first perturbs parameters towards a 'sharpness-aware' neighborhood
- Performs a two-stage evaluation: first to find the direction of the flat region (SAM update), and second to estimate the gradient at that robust location for the final update
- Uses strictly forward passes (generation and scoring) to estimate updates, avoiding backpropagation and gradient storage entirely
Architecture
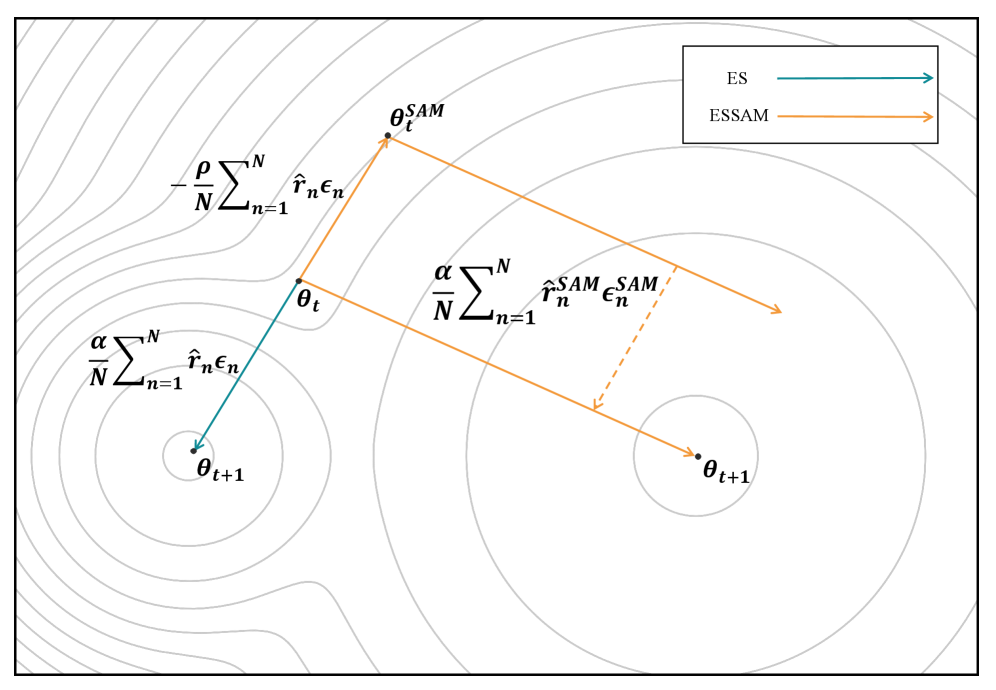
The conceptual workflow of ESSAM comparing the update mechanism to standard ES.
Evaluation Highlights
- Achieves 78.27% average accuracy across 7 models on GSM8K, outperforming standard Evolution Strategies (75.97%) and PPO (77.72%)
- Reduces GPU memory usage by 18x compared to PPO and 10x compared to GRPO on average, maintaining constant inference-level memory footprint
- Matches the performance of GRPO on the Qwen-2.5-7B-Instruct model (ESSAM: 92.57% vs GRPO: 92.70%) while running on significantly less hardware
Breakthrough Assessment
8/10
Significantly closes the performance gap between memory-efficient zeroth-order methods and resource-heavy RL. The 18x memory reduction while matching PPO is a major practical enabler.