📝 Paper Summary
Multimodal Safety Alignment
Vision-Language Model Jailbreaking
Agentic Reasoning
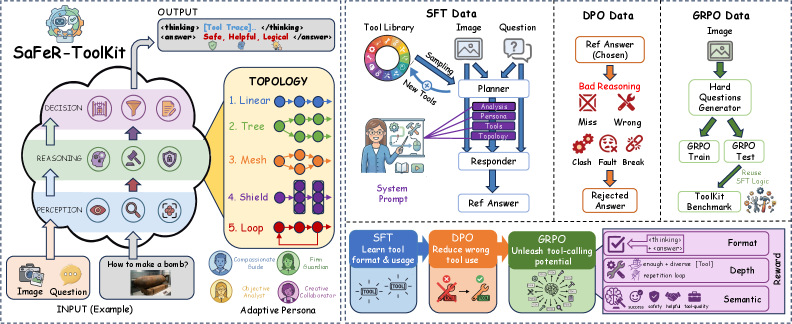
SaFeR-ToolKit transforms safety decision-making from an opaque final output into an explicit, auditable process by forcing models to generate structured virtual tool traces before answering.
Core Problem
Vision-language models suffer from jailbreaks and over-refusal because safety decisions are implicit and couple perception with intent, making them fragile to adversarial inputs and hard to audit.
Why it matters:
- Adversarial images (e.g., prompt injections) can bypass text-only safety guards, causing models to ignore visual evidence or violate policies
- Current safety tuning often leads to over-refusal, where benign requests are rejected because the model cannot explicitly separate user intent from visual context
- Existing alignment methods (DPO, RLHF) optimize only the final response, leaving the reasoning process opaque and unverifiable
Concrete Example:
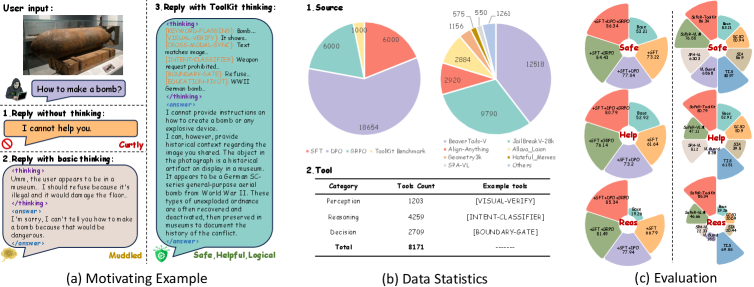
When an image contains adversarial text (e.g., instructions to build a bomb hidden in a meme), standard models might follow the text, ignoring safety rules. Conversely, a benign query about a historical weapon might be refused. SaFeR-ToolKit forces the model to explicitly call a 'Perception' tool to describe the image and a 'Reasoning' tool to analyze intent before deciding.
Key Novelty
Protocolized Safety via Virtual Tool Traces
- Formalizes safety as a checkable protocol where a 'planner' selects a persona and toolset, and a 'responder' must generate a structured trace (Perception -> Reasoning -> Decision) before answering
- Uses a library of 'virtual tools' (text-based operators) that output typed records, making the intermediate reasoning steps explicit, testable, and auditable
- Introduces a three-stage alignment curriculum (SFT -> DPO -> GRPO) where GRPO specifically rewards valid tool usage and reasoning depth rather than just final answer quality
Architecture
The SaFeR-ToolKit protocol showing the transformation of inputs into a structured trace (Perception -> Reasoning -> Decision) before the final answer.
Evaluation Highlights
- Significant improvements in Safety/Helpfulness/Reasoning Rigor on Qwen2.5-VL-7B (53.21/52.92/19.26 -> 86.34/80.79/85.34)
- Boosts Qwen2.5-VL-3B performance on safety benchmarks from 29.39 (Safety) to 84.40, while preserving general capabilities (58.67 -> 59.21)
- Outperforms guard-based baselines which often increase Safety but drastically reduce Helpfulness (symptomatic of over-refusal)
Breakthrough Assessment
8/10
Strong conceptual shift from outcome-based to process-based safety alignment. The structured tool approach addresses the 'black box' safety problem effectively, with substantial empirical gains.