📝 Paper Summary
LLM Self-Debugging
Iterative Refinement
Code Generation
TGPR improves code debugging by using a Thompson Sampling-guided tree search during training to generate diverse refinement trajectories, allowing the model to learn from both successes and failures without expensive search at test time.
Core Problem
Standard reinforcement learning for code refinement (like GRPO) suffers from inefficient exploration, often getting stuck in local optima because it relies solely on the policy's own limited sampling to find fixes.
Why it matters:
- Single-pass code generation frequently fails on complex algorithms or subtle bugs, necessitating iterative repair strategies
- Existing refinement methods use fixed heuristics or myopic RL that cannot effectively navigate the vast search space of possible code edits
- Inefficient exploration leads to models that cannot fix subtle semantic errors or algorithmic flaws, limiting their utility in real-world software development
Concrete Example:
When a model generates code with a subtle boundary error (e.g., off-by-one loop), a standard RL agent might try random syntax changes that fail or only fix the syntax without solving the logic. TGPR's tree search would explore a branch where the loop condition is modified, identify it as a high-reward path via Thompson Sampling, and use that trajectory to train the policy.
Key Novelty
Training-Time Tree-Guided Exploration
- Integrates a Thompson Sampling-guided search tree into the GRPO training loop to actively manage exploration and exploitation of code refinements
- Uses the tree search strictly as a data generation engine during training to create high-quality trajectories (including informative failures), allowing the final model to perform single-shot refinement at inference without the computational cost of the tree
Architecture
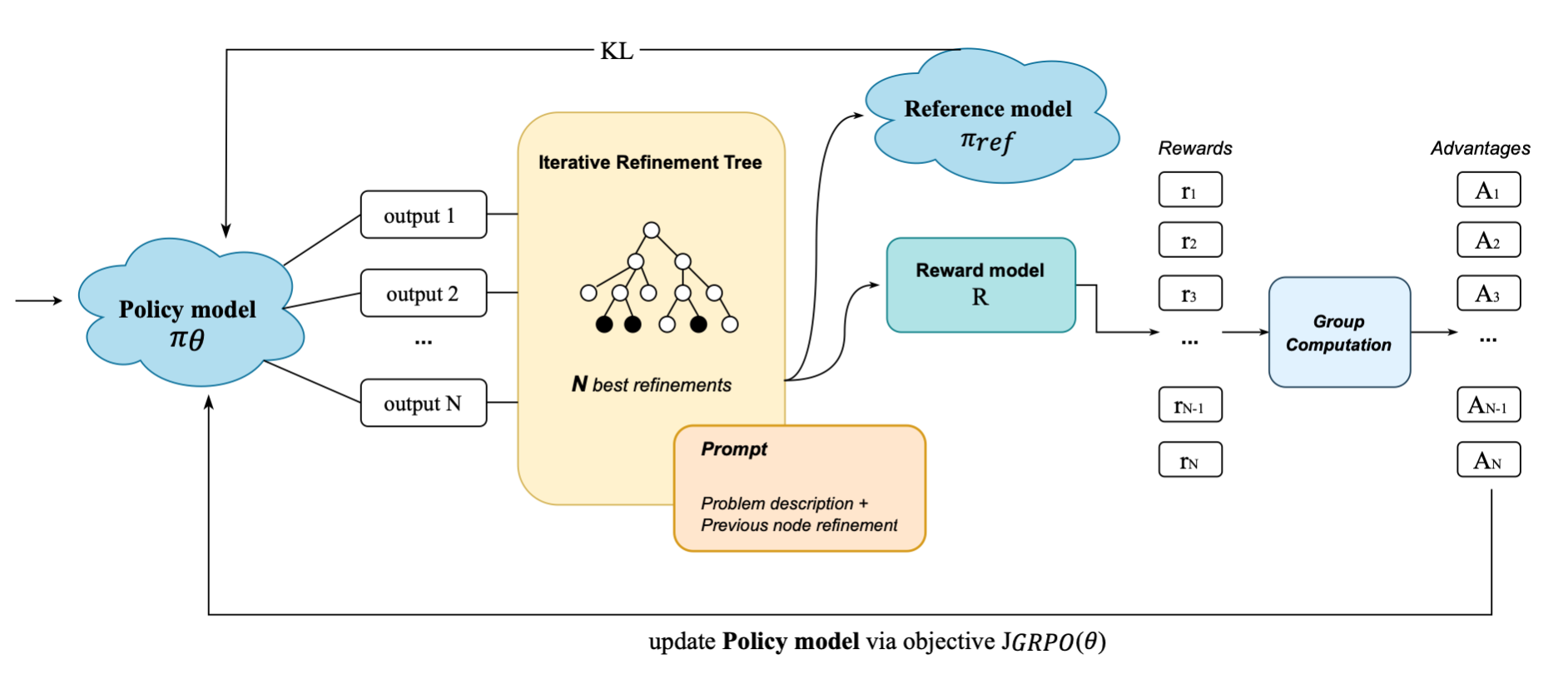
The TGPR framework architecture showing the interaction between the Policy Model, Reward Model, and the Thompson Sampling-guided Tree during training.
Evaluation Highlights
- +12.51 percentage points improvement in pass@10 on the APPS benchmark compared to the GRPO baseline
- +4.2 percentage points improvement in pass@1 on MBPP compared to GRPO
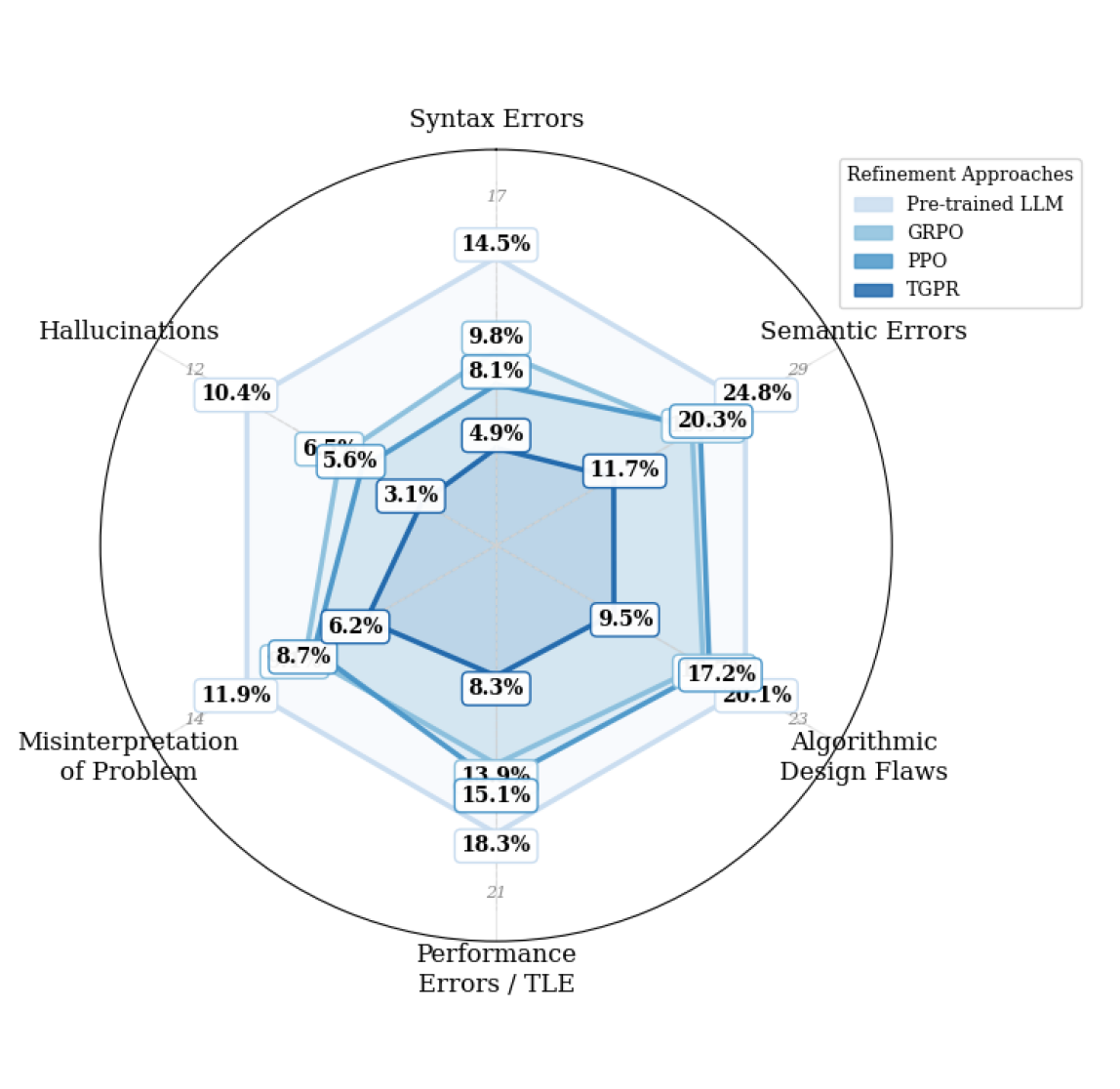
- Achieved lowest error rates across all categories (Semantic, Algorithmic, Performance) compared to PPO and GRPO baselines
Breakthrough Assessment
7/10
Strong empirical results (+12.5pp on APPS) and a principled approach to the exploration problem in RL HF (RL from Human/Heuristic Feedback). The idea of using tree search for training-data augmentation rather than inference is clever and efficient.