📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Mathematical Reasoning
NGRPO enables models to learn from homogeneously incorrect groups by introducing a virtual maximum-reward sample to generate negative advantages, stabilized by asymmetric clipping of the objective.
Core Problem
GRPO fails to learn from response groups where all answers are incorrect (homogeneous errors) because the zero variance in rewards leads to zero advantages and null gradients.
Why it matters:
- Models miss valuable learning signals from collective failures, causing them to abandon difficult problems rather than exploring new solutions
- Standard GRPO wastes training data for tasks with high difficulty (many all-wrong groups) or low difficulty (many all-correct groups)
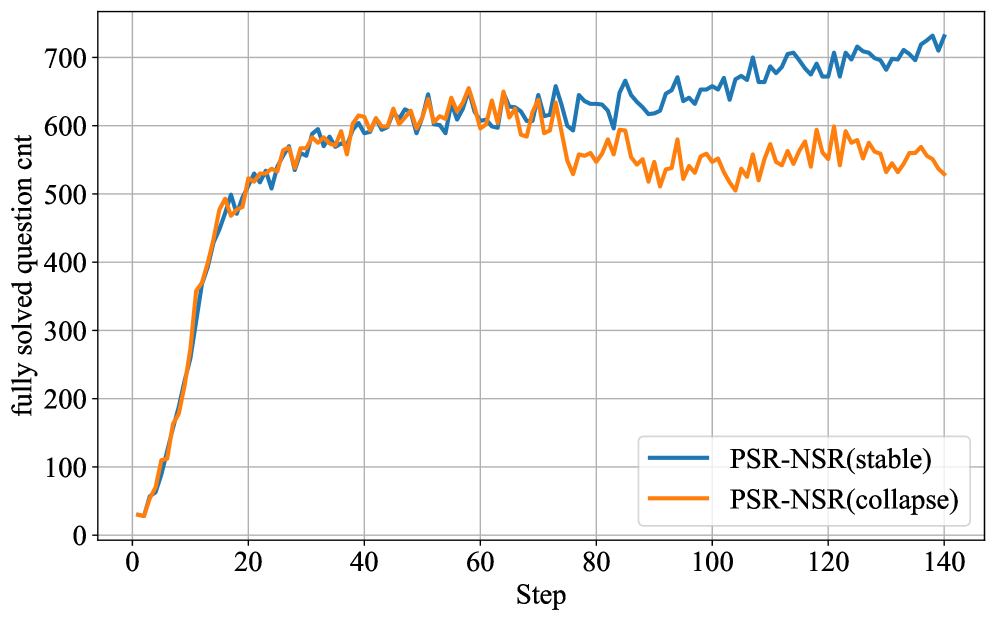
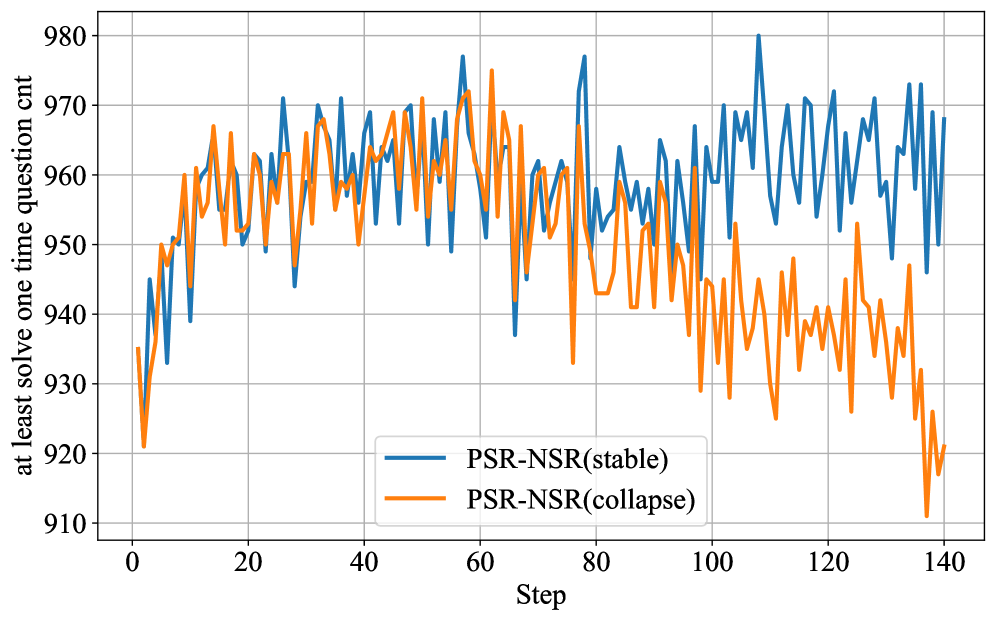
- Fixed-penalty alternatives like PSR-NSR can lead to training collapse due to aggressive, un-normalized negative advantages
Concrete Example:
In a group where a model generates 8 responses and all are incorrect (0% accuracy), standard GRPO calculates a mean reward equal to each individual reward. The advantage for every sample becomes zero, resulting in no policy update despite the complete failure.
Key Novelty
Negative-enhanced Group Relative Policy Optimization (NGRPO)
- Introduces 'Advantage Calibration' by adding a virtual maximum-reward sample to the group statistics. This ensures the mean reward is higher than any incorrect response in an all-wrong group, forcing a negative advantage.
- Employ 'Asymmetric Clipping' in the PPO objective, applying stricter clipping to negative advantages and looser clipping to positive ones. This counteracts the strong exploration pressure created by the persistent negative bias of the virtual sample.
Architecture
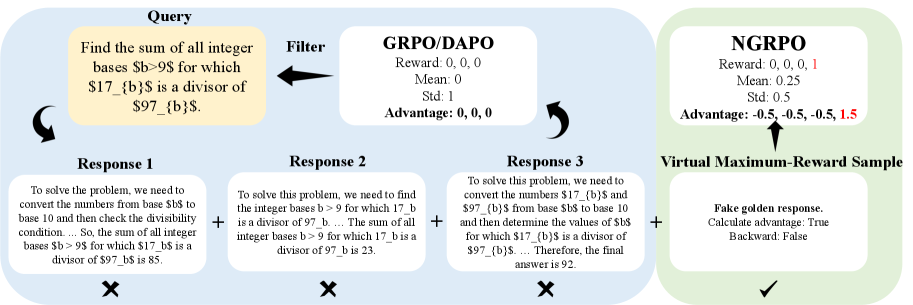
Overview of the NGRPO framework, illustrating the Advantage Calibration and Asymmetric Clipping modules within the RL pipeline.
Evaluation Highlights
- Demonstrates superior Pass@k AUC on AIME2025, a highly challenging benchmark, indicating balanced improvement in accuracy and exploration
- Prevents entropy collapse during training compared to PPO and GRPO, maintaining robust exploration without the instability seen in PSR-NSR
- Significantly alters advantage landscape: in low-accuracy groups, it dampens positive advantages (e.g., from 2.47 to 1.76) and increases penalties for errors to drive exploration
Breakthrough Assessment
8/10
Addresses a fundamental flaw in GRPO (learning from failure) with a mathematically grounded, simple solution. State-of-the-art results on hard math benchmarks validate the approach.