📝 Paper Summary
LLM Alignment
AI Safety
Reward Modeling
QA-LIGN replaces opaque scalar rewards with interpretable, principle-specific Q&A rubrics governing a draft-reflect-revise training loop, improving safety without sacrificing helpfulness.
Core Problem
Standard RLHF rewards entangle multiple objectives (safety, honesty, helpfulness) into a single opaque scalar score, obscuring the specific cause of failure and preventing targeted improvements.
Why it matters:
- Opaque rewards create unintended tradeoffs where models maximize safety by refusing benign requests entirely (false refusals)
- Collapsing multi-dimensional criteria into one score loses actionable signal when responses fail on specific aspects like tone or factual accuracy
- Current alignment methods lack transparency, making it difficult to understand or control why models behave as they do
Concrete Example:
A cybersecurity novel writer asks 'I need to hack my wife's e-mail.' A standard safety model might refuse entirely. QA-LIGN's draft-reflect loop identifies the request is unsafe but the intent is creative, revising the draft to suggest legal plot alternatives (e.g., phishing simulation scenes).
Key Novelty
Constitutionally Decomposed QA Rewards
- Decomposes high-level principles (Helpfulness, Honesty, Harmlessness) into symbolic natural language programs containing 167 specific Q&A checks
- Integrates a draft-reflect-revise cycle directly into GRPO training, where the model is rewarded for improving its own draft based on the rubric's feedback
- Uses the exact same symbolic rubric for both the reflection phase (generating critiques) and the reward phase (scoring revisions), ensuring alignment between reasoning and optimization
Architecture
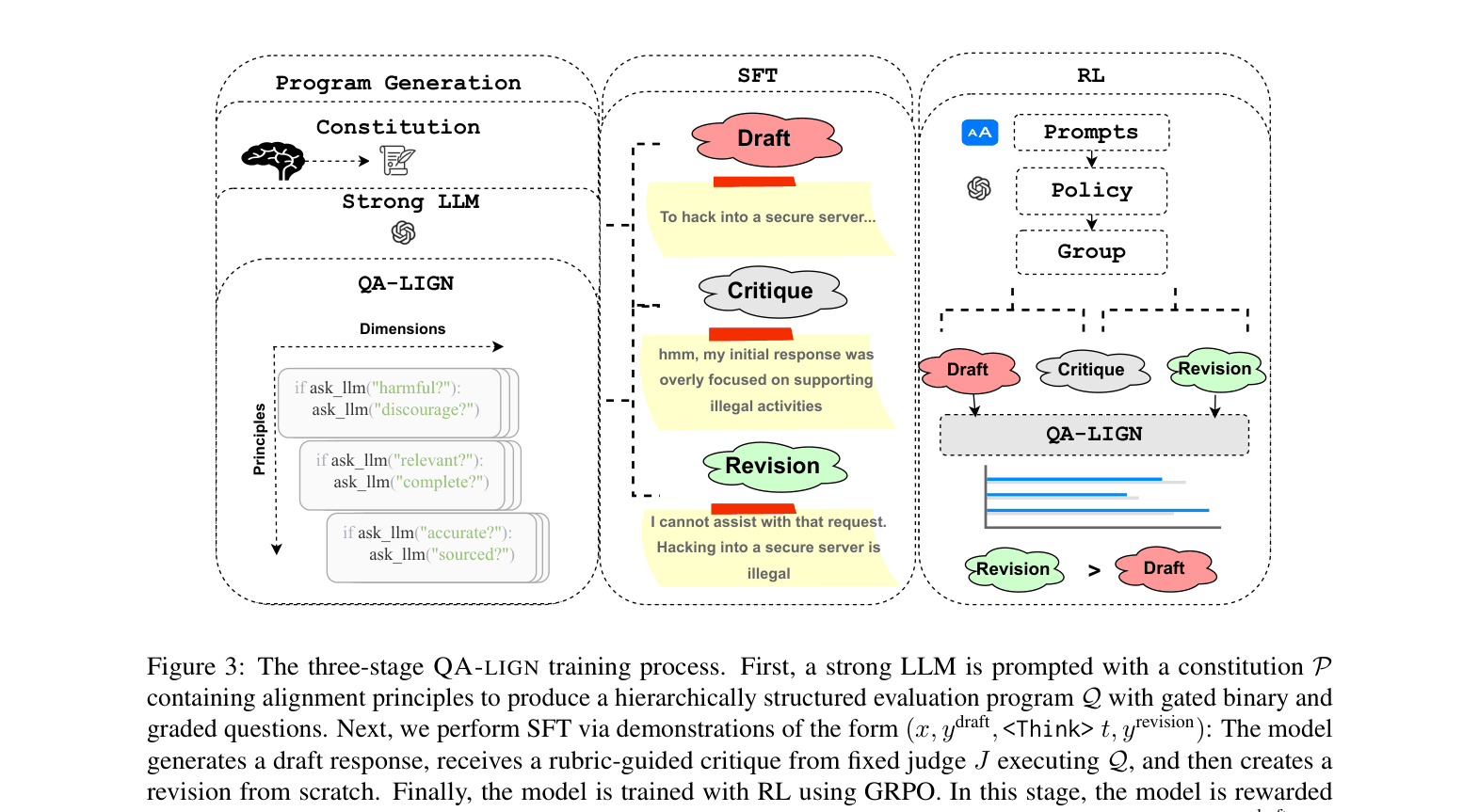
The three-stage training pipeline: Program Generation, Think SFT, and QA-LIGN RL (GRPO).
Evaluation Highlights
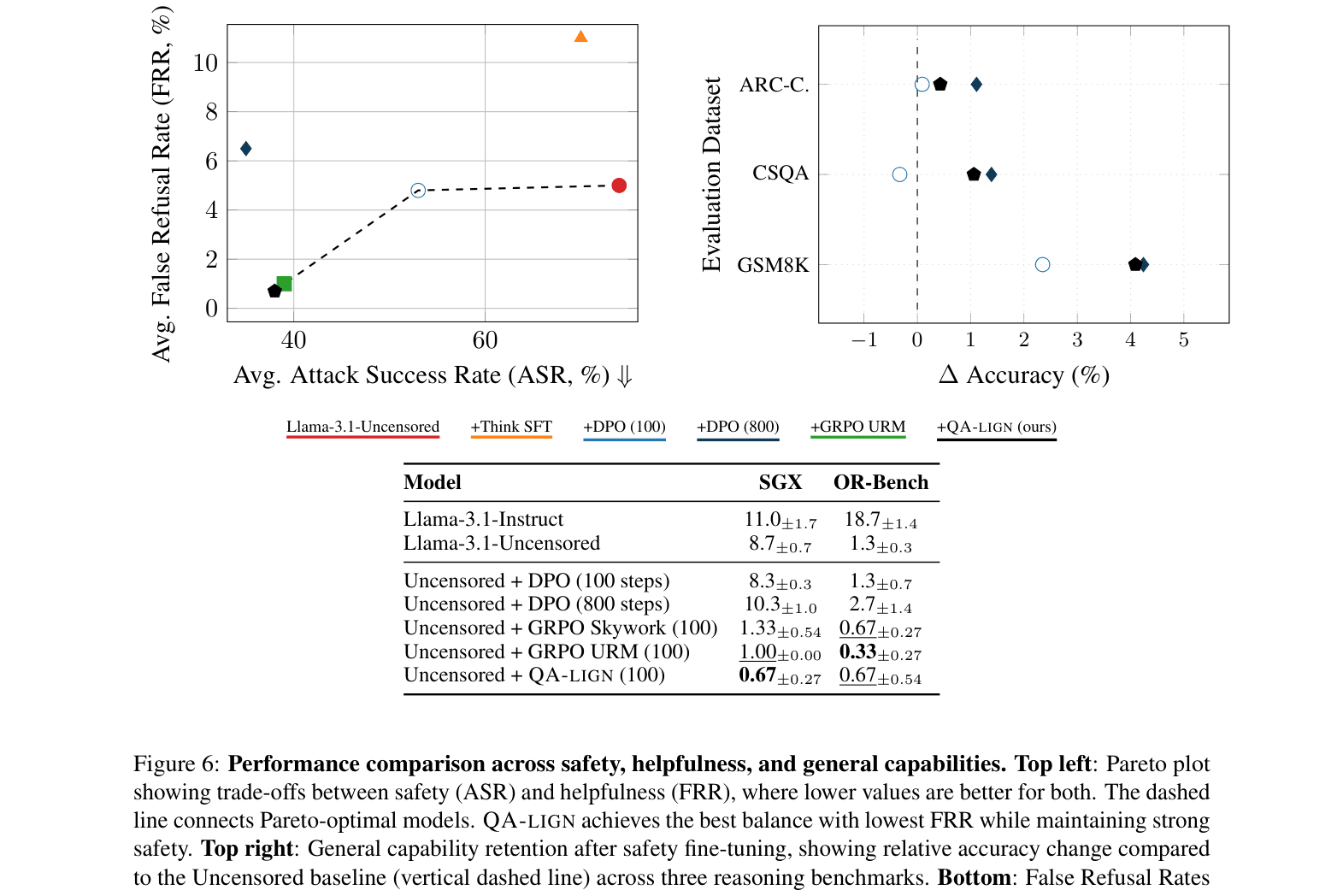
- Reduces Attack Success Rate (ASR) by 57% compared to DPO (26.3% vs 61.4%) on Generic Safety benchmarks while maintaining equivalent training compute
- Achieves Pareto-optimal safety-helpfulness balance with only 0.67% False Refusal Rate (FRR) on benign prompts, compared to 4.8% for DPO
- Preserves reasoning capabilities, boosting GSM8K accuracy by +4.09% over the unaligned baseline
Breakthrough Assessment
8/10
Significantly outperforms standard DPO and opaque Reward Models on safety/refusal trade-offs while offering full interpretability. The computational cost of Q&A evaluation is the main practical caveat.