📝 Paper Summary
Reinforcement Learning for Reasoning
Curriculum Learning
Goldilocks trains a Teacher model to dynamically select training questions for a Student model that are neither too easy nor too hard, maximizing the learning signal from sparse outcome-based rewards.
Core Problem
Outcome supervision in RL creates sparse rewards where models must explore vast spaces to find correct solutions, making training highly sample-inefficient.
Why it matters:
- Standard scaling of test-time compute is resource-intensive; improving training efficiency is critical for modern LLMs.
- Existing curriculum learning methods (history-based or category-based) do not scale to massive datasets because they require revisiting examples or rely on rigid categorization.
- Models waste valuable GPU resources training on examples that are either too easy (zero gradient) or too hard (no positive signal), slowing down convergence.
Concrete Example:
If a model has a 0% or 100% chance of solving a math problem, the gradient variance is zero, and it learns nothing. Standard training randomly samples these useless questions, wasting compute.
Key Novelty
Goldilocks Teacher-Student Framework
- Simultaneously trains a Teacher model to predict the 'learning potential' (utility) of unseen questions based on the Student's current performance.
- Uses a 'Goldilocks principle' to select questions where the Student's success probability is near 0.5, maximizing reward variance and gradient magnitude.
- The Teacher generalizes to new data streams without requiring the Student to see every example multiple times, unlike history-based curriculum learning.
Architecture
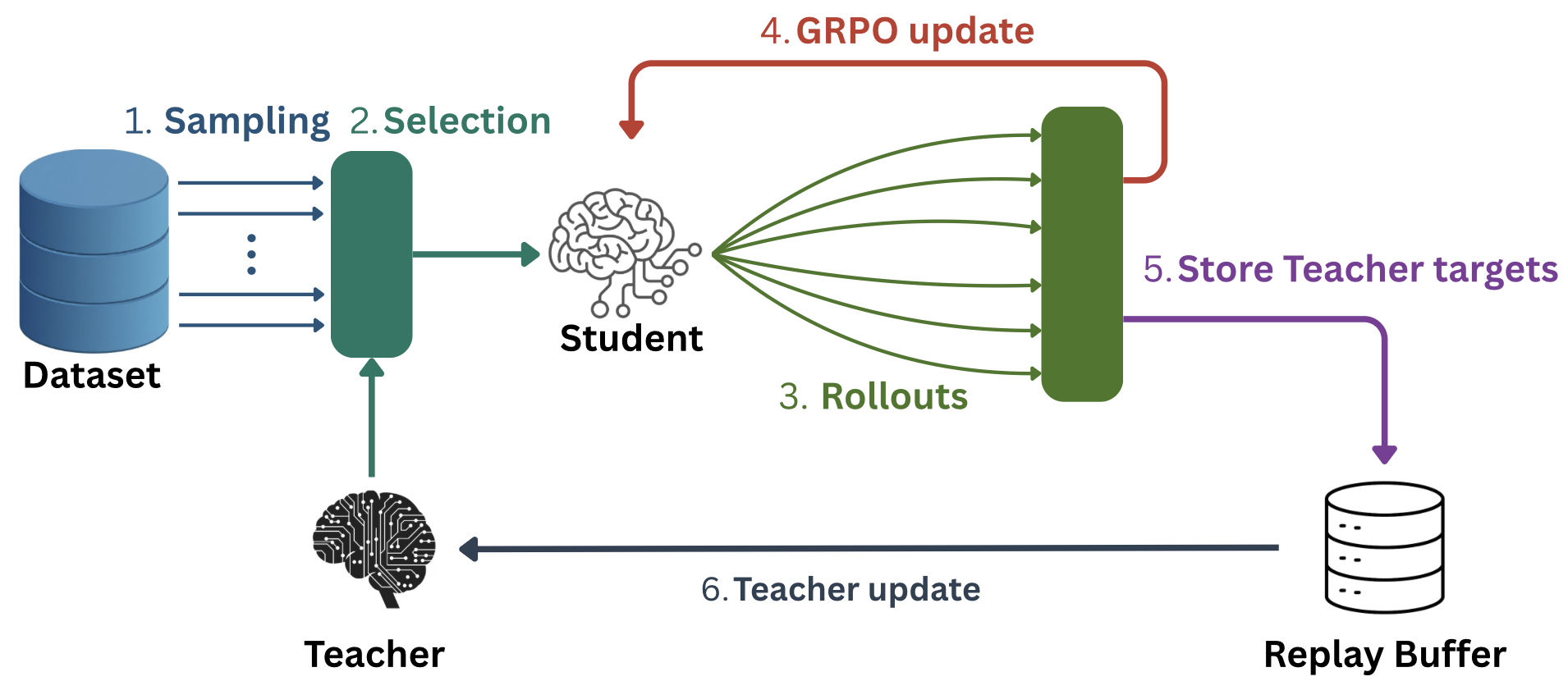
The joint training loop of Goldilocks, showing the interaction between the Teacher, Student, and Replay Buffer.
Evaluation Highlights
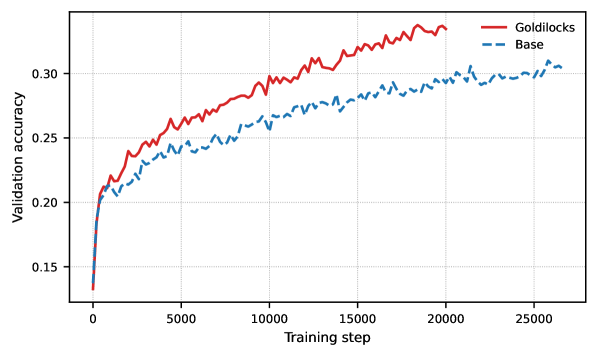
- Outperforms standard GRPO baseline by ~2-5% accuracy on OpenMathReasoning validation set across multiple model sizes (1.5B to 4B parameters) under identical compute budgets.
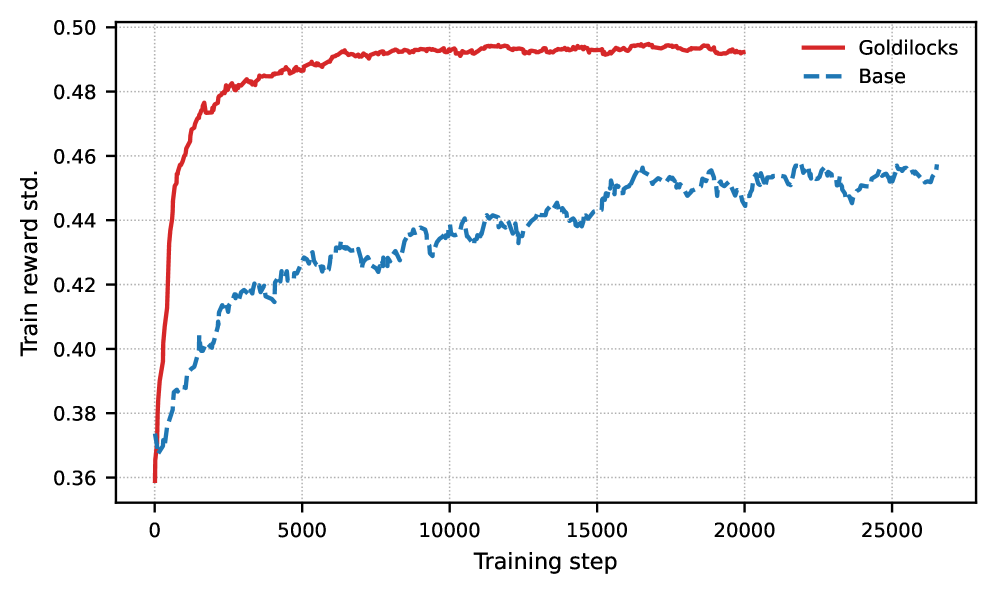
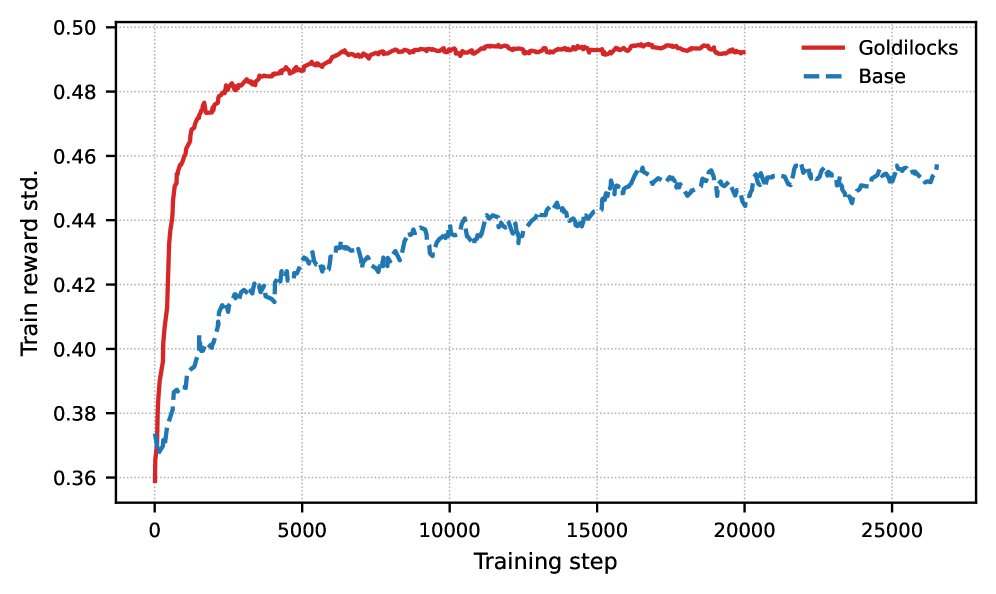
- Significantly reduces the fraction of training batches with zero reward variance (useless gradients), ensuring more effective parameter updates per step.
- Maintains consistently higher gradient norms throughout training compared to random sampling, preventing optimization stagnation.
Breakthrough Assessment
7/10
A strong efficiency improvement for RL fine-tuning of reasoning models. While the core idea of curriculum learning is established, the dynamic, scalable implementation for sparse rewards is practically valuable.