📝 Paper Summary
Reinforcement Learning for Reasoning
Efficient Training of LLMs
CPPO accelerates reasoning model training by pruning low-advantage completions from the GRPO process and dynamically allocating new questions to maximize GPU utilization without sacrificing accuracy.
Core Problem
Group Relative Policy Optimization (GRPO) is computationally expensive because it requires sampling and processing a large group of completions for every question to estimate baselines.
Why it matters:
- Training reasoning models like DeepSeek-R1 requires massive computational resources, limiting scalability and accessibility
- Standard GRPO scales linearly with the number of completions; processing 64 completions requires 192 forward passes per question, creating a major bottleneck
- Not all sampled completions contribute equally to learning; processing low-value samples wastes compute
Concrete Example:
In DeepSeek-Math, using 64 completions per question requires 192 forward passes (64 × 3 models). If many of these completions have near-zero advantage (e.g., they are neither clearly correct nor helpfully incorrect), processing them for gradient updates wastes time without improving the policy.
Key Novelty
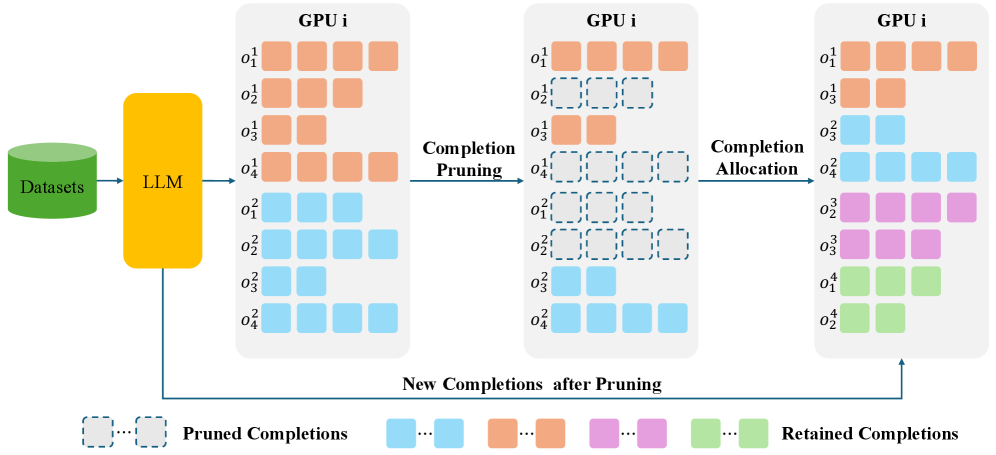
Completion Pruning Policy Optimization (CPPO)
- Calculate the advantage of generated completions *before* the full policy forward pass used for gradient computation
- Prune completions with low absolute advantage (those that don't provide strong positive or negative reinforcement signals)
- Dynamically fill the GPU batch with completions from new questions to replace pruned ones, ensuring high hardware utilization
Architecture
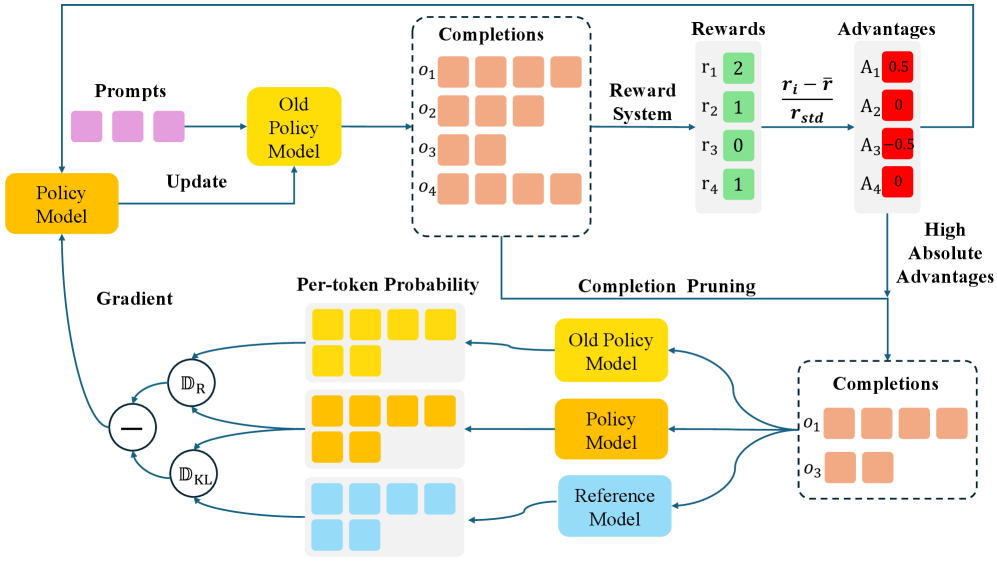
Comparison of the GRPO and CPPO training pipelines.
Evaluation Highlights
- Achieves up to 7.98x training speedup on GSM8K with Qwen2.5-1.5B-Instruct while maintaining accuracy
- Attains 3.48x speedup on the more challenging MATH dataset with Qwen2.5-7B-Instruct
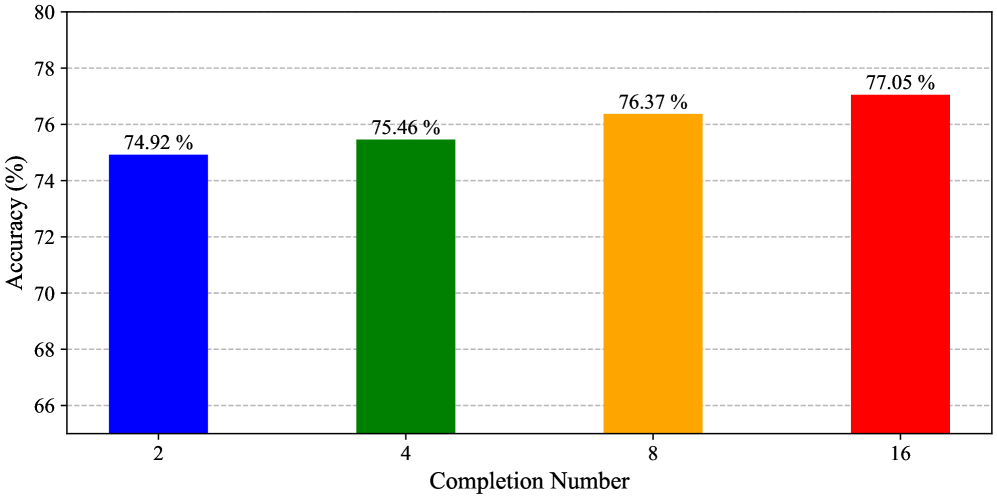
- Maintains or improves accuracy compared to GRPO: e.g., +2.63% accuracy on GSM8K at 87.5% pruning rate
Breakthrough Assessment
8/10
Offers a significant practical efficiency gain (3-8x speedup) for a popular new training method (GRPO) with a theoretically grounded pruning strategy. The dynamic allocation mechanism addresses the 'bucket effect' effectively.