📝 Paper Summary
Reinforcement Learning for Diffusion Models
Training Stability
StableDRL prevents reward collapse in diffusion language models by using unconditional clipping and self-normalization to constrain gradient updates derived from noisy importance ratio estimates.
Core Problem
Applying Group Relative Policy Optimization (GRPO) to diffusion models causes reward collapse because importance ratios must be estimated (yielding high variance/outliers) and standard GRPO's conditional clipping fails to contain noise-induced gradient spikes.
Why it matters:
- Discrete Diffusion LLMs (dLLMs) offer parallel decoding and bidirectional context but currently cannot be effectively fine-tuned with RL due to severe training instability
- Standard RL methods like GRPO assume tractable likelihoods, but dLLM likelihoods are intractable and their estimates (proxies) introduce noise that destabilizes optimization
- Current solutions focusing only on better estimation (ELBO/mean-field) still suffer from instability loops where policy drift amplifies future estimation variance
Concrete Example:
Due to estimation noise, an importance ratio for a single rollout can explode to 10^5. If the advantage is negative, standard GRPO allows this outlier to bypass clipping (conditional clipping), creating a massive gradient spike that destroys the policy.
Key Novelty
StableDRL (Stable Diffusion Reinforcement Learning)
- Unconditional Clipping: Enforces strict bounds on importance ratios regardless of the advantage sign, preventing estimation noise outliers from generating gradient spikes
- Self-Normalization: Normalizes updates by the sum of clipped importance ratios instead of fixed group size, constraining updates to the convex hull of per-sample gradients
- Staircase Attention: A structured masking primitive for block diffusion models that enables leakage-free probability estimation in a single pass
Architecture
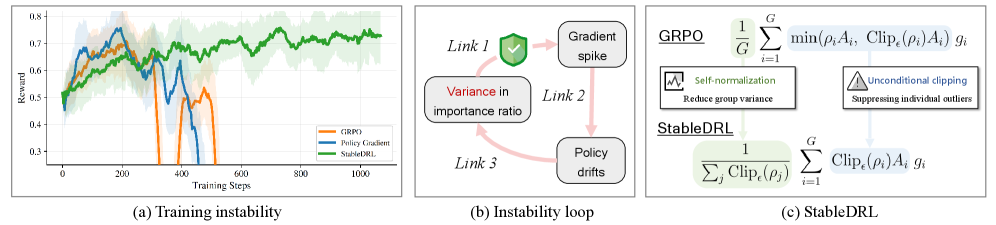
The StableDRL update mechanism compared to standard GRPO.
Evaluation Highlights
- Enables stable full-parameter RL training on dLLMs for >1,000 steps, overcoming the reward collapse observed at ~300 steps with standard GRPO
- Mitigates the impact of importance ratio estimation noise, which can reach magnitudes of 10^5 in individual rollouts
Breakthrough Assessment
8/10
Identifies a fundamental theoretical incompatibility between GRPO and diffusion models (noise-induced unclipping). Proposes a mathematically grounded fix that enables RL where it previously failed.