📝 Paper Summary
LLM Reasoning
Reinforcement Learning (RL) efficiency
DPPO accelerates Group Relative Policy Optimization (GRPO) by dynamically pruning low-value prompts and completions while using importance sampling to correct the resulting estimation bias.
Core Problem
GRPO requires sampling many completions per prompt to estimate advantages, causing high computational cost. Existing pruning methods introduce estimation bias by altering the sampling distribution without correction.
Why it matters:
- GRPO's forward-pass cost scales linearly with group size, making large-scale reasoning training prohibitively expensive
- Heuristic pruning (discarding 'bad' samples) changes the data distribution, causing gradient estimates to deviate from the true objective and leading to suboptimal convergence
- Memory fragmentation from pruning often reduces hardware utilization, negating theoretical speedups
Concrete Example:
In a MATH problem requiring the Cauchy-Schwarz inequality, heuristic pruning methods (GRESO, CPPO) discard samples that seem low-value but provide critical contrast, causing the model to converge to an incorrect answer (1/2). DPPO's unbiased weighting retains the correct gradient direction, allowing the model to find the true solution (55).
Key Novelty
Hierarchical Importance-Weighted Pruning
- Treats data pruning as an importance sampling problem: instead of just discarding samples, it reweights the retained ones to mathematically restore the original gradient expectation
- Applies pruning hierarchically: first filters redundant prompts based on historical difficulty, then filters low-information completions based on intra-group advantage
- Uses 'Dense Prompt Packing' to repack variable-length pruned sequences into compact buffers, preventing the memory fragmentation that usually slows down sparse training
Architecture
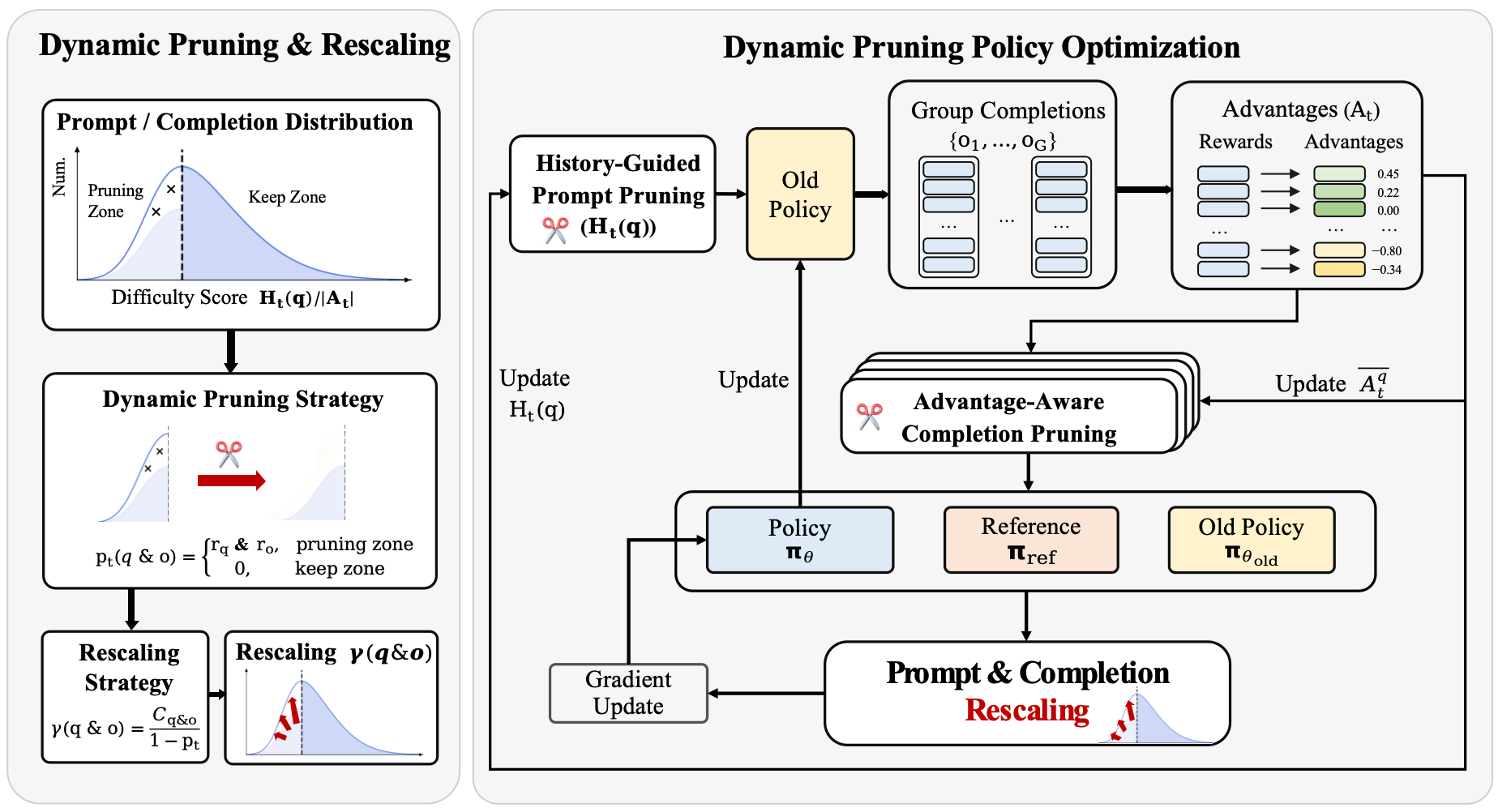
The hierarchical pruning workflow of DPPO compared to standard GRPO.
Evaluation Highlights
- 2.37× training speedup on MATH with Qwen3-4B while improving accuracy by +3.15% over the GRPO baseline
- Outperforms heuristic pruning baselines (GRESO, CPPO) by +1.7% to +5.2% on Qwen3-4B across 6 math benchmarks
- Achieves up to 4.87× speedup on Qwen3-30B-MoE without accuracy degradation, showing scalability to large architectures
Breakthrough Assessment
8/10
Strong theoretical grounding (unbiased estimator) addresses a major flaw in previous heuristic pruning methods. The combination of algorithmic correction and system-level packing yields significant, practical speedups.