📝 Paper Summary
AI for Quantum Computing
LLM Post-training for Code
This paper trains a specialized Large Language Model (LLM) for quantum computing by using pass/fail execution feedback from real quantum hardware and simulators as a reinforcement learning reward signal.
Core Problem
General-purpose coding models often generate quantum code (Qiskit) that is syntactically correct but fails to execute on actual quantum hardware due to deprecated APIs or violations of physical constraints.
Why it matters:
- Quantum SDKs evolve rapidly, causing models trained on stale data to produce deprecated, non-executable code
- Correct quantum programming requires adhering to strict physical hardware constraints (e.g., qubit connectivity) that standard language modeling objectives do not enforce
- Existing execution-based feedback methods focus on CPU execution, missing the specific nuances of Quantum Processing Unit (QPU) compilation and execution
Concrete Example:
A user asks for a circuit to run on a specific backend. A standard model might import `qiskit.providers.aer` (deprecated) or fail to transpile the circuit for the device's coupling map. The proposed model, optimized with hardware feedback, correctly identifies the backend and uses the modern `SamplerV2` primitive.
Key Novelty
Quantum-Verifiable Reinforcement Learning
- Integrates a 'Quantum Verification' loop into the training pipeline, where generated code is executed on quantum simulators or hardware to generate a binary pass/fail reward
- Uses Group Relative Policy Optimization (GRPO) to optimize the model specifically for this quantum execution reward, ensuring code isn't just plausible but physically executable
- Distills quantum physics reasoning from a larger teacher model (DeepSeek V3) into the code assistant to improve problem understanding before code generation
Architecture
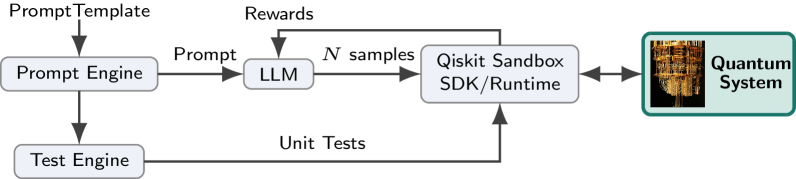
The GRPO training loop where the LLM interacts with a 'Quantum Sandbox' environment.
Evaluation Highlights
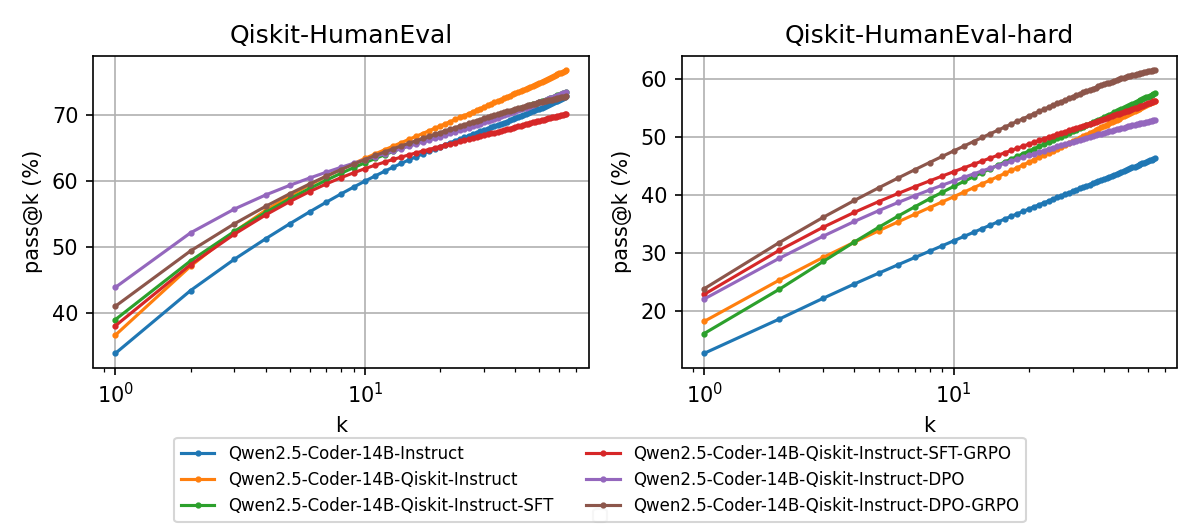
- Achieves 28.48% pass@1 on the Qiskit-HumanEval-hard benchmark, outperforming the massive Qwen3-Coder-480B-Instruct (highest score among all evaluated models)
- Outperforms the base Qwen2.5-Coder-14B-Instruct model by a margin of 12-16% on Qiskit-HumanEval-hard
- Matches the performance of the 30x larger Qwen3-Coder-480B on the standard Qiskit-HumanEval benchmark (50.33% vs 51.65%)
Breakthrough Assessment
8/10
Novel application of physical hardware verification (QPUs) as an RL reward signal. Demonstrates that domain-specific verification can allow small models to outperform massive generalist models in specialized fields.