📝 Paper Summary
End-to-End Autonomous Driving
Vision-Language-Action (VLA) Models
Reinforcement Learning for VLA
NoRD achieves state-of-the-art driving performance using a weak vision-language policy trained on minimal data by replacing standard RL post-training with Dr. GRPO to correct for reward variance bias.
Core Problem
Current VLA driving models rely on expensive, massive datasets with detailed reasoning annotations; naively removing this data creates 'weak' policies that fail to learn via standard RL methods like GRPO.
Why it matters:
- Collecting and annotating millions of driving scenarios with reasoning traces is prohibitively expensive and unscalable
- Reasoning tokens increase inference latency, making real-time deployment difficult
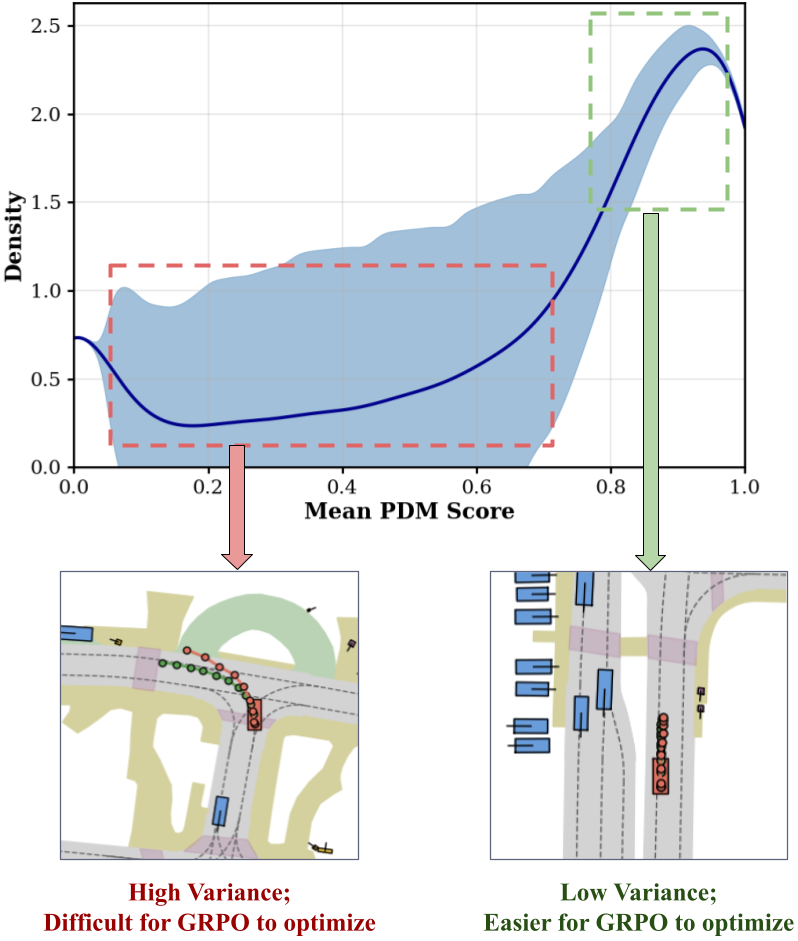
- Standard RL post-training (GRPO) fails on weak policies because it disproportionately penalizes high-variance scenarios, preventing effective learning from limited data
Concrete Example:
A weak SFT model attempting a complex turn often fails, producing high variance in rewards across rollouts. Standard GRPO effectively ignores these high-variance 'learning moments' and over-optimizes trivial scenarios (like driving straight) where the model is already stable, leading to negligible improvement (+0.67% PDM score).
Key Novelty
Dr. GRPO for Difficulty-Biased Driving Policies
- Identifies that the failure of RL on weak driving policies is due to 'difficulty bias': standard GRPO favors low-variance groups (easy scenarios) and ignores high-variance groups (complex maneuvers where learning is needed)
- Replaces standard GRPO with Dr. GRPO, which removes the standard deviation term from the advantage calculation, forcing the model to learn from high-variance, intermediate-difficulty scenarios
Architecture
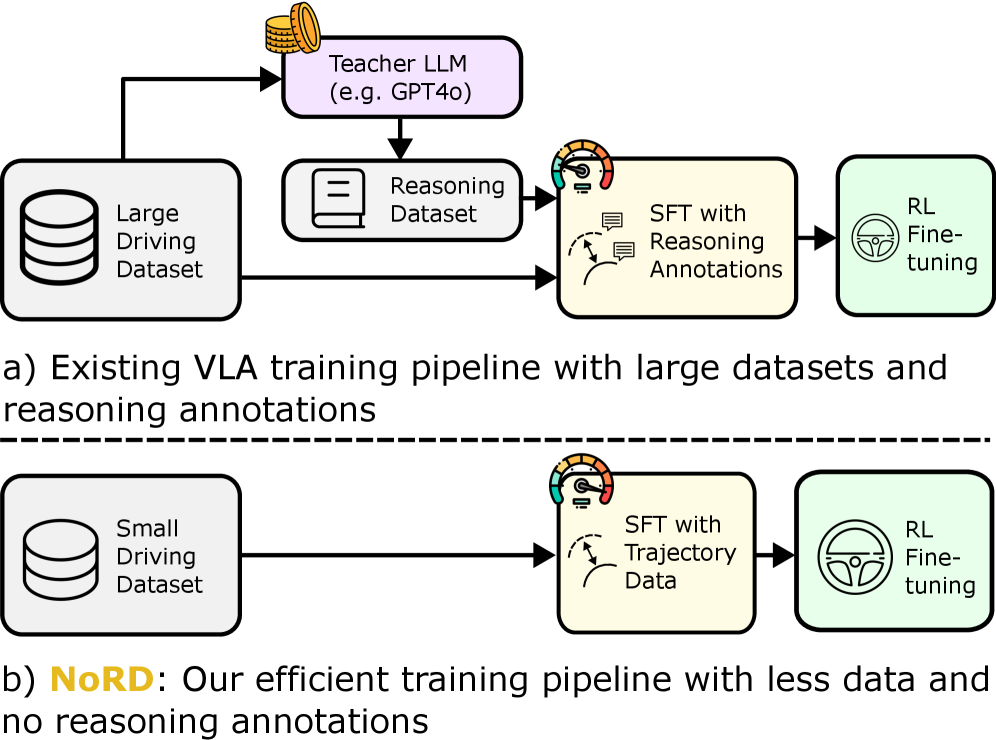
Overview of the NoRD training pipeline contrasting standard VLA training with the proposed method
Evaluation Highlights
- Achieves competitive performance on NAVSIM with >60% less training data (80k vs 200k+) and zero reasoning annotations compared to state-of-the-art VLAs
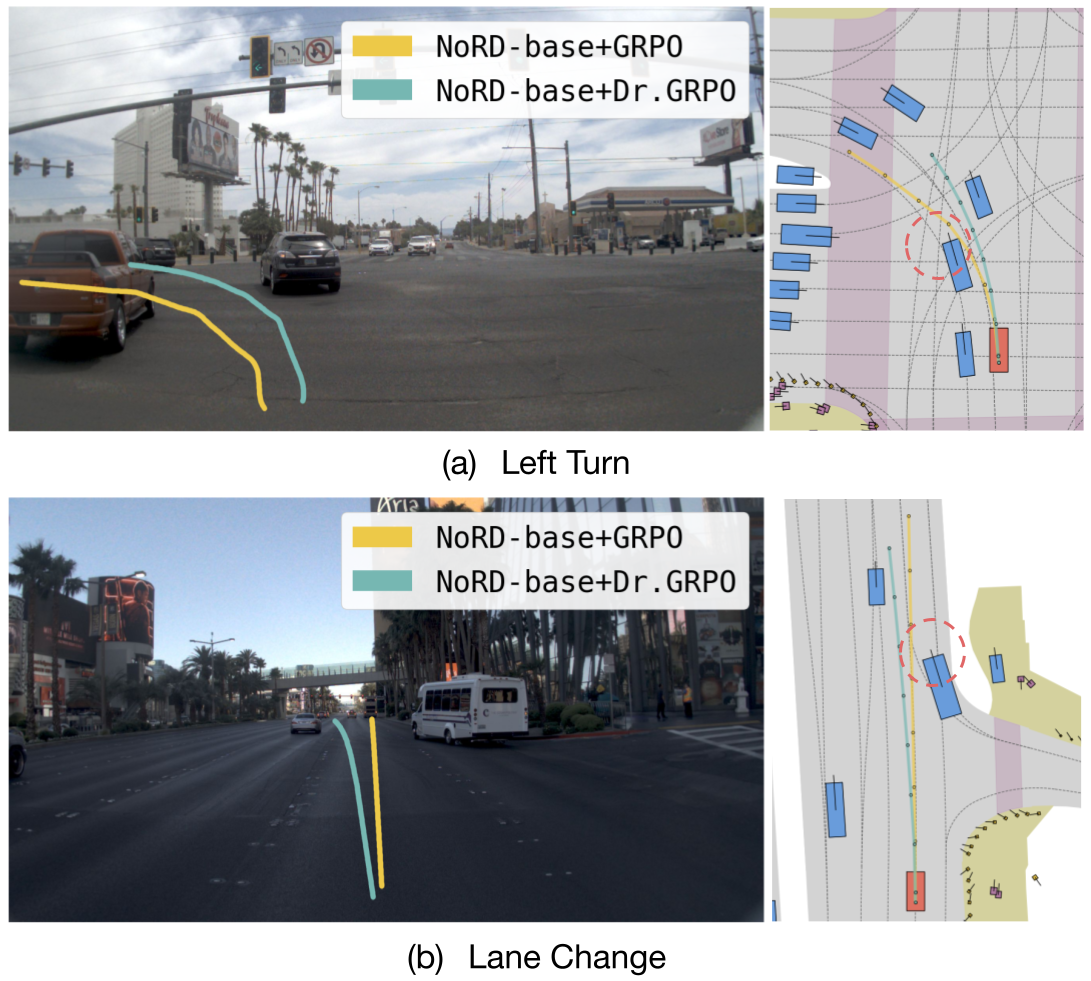
- Improves PDM score by +11.68% using Dr. GRPO compared to only +0.67% with standard GRPO, proving the optimization method was the bottleneck
- Ranks as the 3rd best VLA on WaymoE2E benchmark (RFS: 7.709) while using 17x less data than competitors like Poutine
Breakthrough Assessment
8/10
Significantly challenges the prevailing dogma that explicit reasoning and massive data are required for VLA driving models. Successfully adapts an LLM-reasoning optimization technique (Dr. GRPO) to the autonomous driving domain.