📝 Paper Summary
Mathematical Reasoning
Reinforcement Learning for LLMs
iGRPO improves mathematical reasoning by training models to refine their own best generated drafts, creating a self-improving feedback loop within the reinforcement learning optimization process.
Core Problem
Standard Reinforcement Learning (RL) treats reasoning generation as a single-pass process, failing to leverage the iterative refinement and self-correction strategies that characterize effective human problem-solving.
Why it matters:
- Humans rarely solve complex problems in one attempt; they iterate and refine based on internal feedback
- Existing RL methods like GRPO optimization optimize independent generations, missing the opportunity to learn from the model's own best prior attempts
- Single-pass optimization limits the model's ability to correct errors or deepen reasoning chains during the learning process
Concrete Example:
When training on a complex math problem, a standard GRPO model treats every attempt as independent. In contrast, iGRPO first generates several drafts, identifies the one that got the correct answer (even if the reasoning was messy), and then feeds this best draft back to the model as a prompt, forcing it to learn how to refine and perfect that specific solution path.
Key Novelty
Iterative Group Relative Policy Optimization (iGRPO)
- Introduces a two-stage training loop: Stage 1 samples exploratory drafts and selects the best one using a reward model; Stage 2 optimizes the policy to generate refinements conditioned on that best draft.
- Uses 'dynamic self-conditioning' where the prompting context evolves (bootstraps) as the policy improves, ensuring the model always trains on refining its current best capabilities.
Architecture
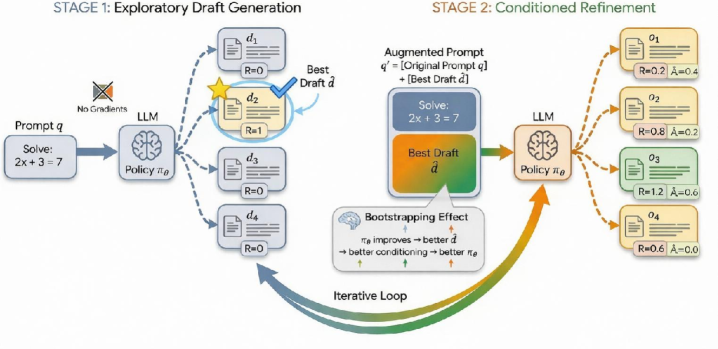
The two-stage training workflow of iGRPO.
Evaluation Highlights
- Achieves 85.62% accuracy on AIME24 with OpenReasoning-Nemotron-7B, setting a new state-of-the-art result.
- Achieves 79.64% accuracy on AIME25 with OpenReasoning-Nemotron-7B.
- Consistently outperforms standard GRPO baselines across 7B and 14B parameter models on benchmarks like MATH and GSM8K under matched rollout budgets.
Breakthrough Assessment
8/10
Offers a simple yet logically grounded extension to GRPO that aligns training with iterative human reasoning. The reported gains on difficult benchmarks like AIME are significant, though full baseline numbers for direct comparison are needed.