📝 Paper Summary
Video-LLM Reasoning
Reinforcement Fine-Tuning (RFT)
VerIPO improves video reasoning by inserting a rollout-aware verifier into the RL loop that filters exploration data into high-quality contrastive pairs for efficient Direct Preference Optimization.
Core Problem
Applying reinforcement learning to Video-LLMs often yields short, shallow, or inconsistent reasoning chains, while supervised fine-tuning suffers from data scarcity and high annotation costs.
Why it matters:
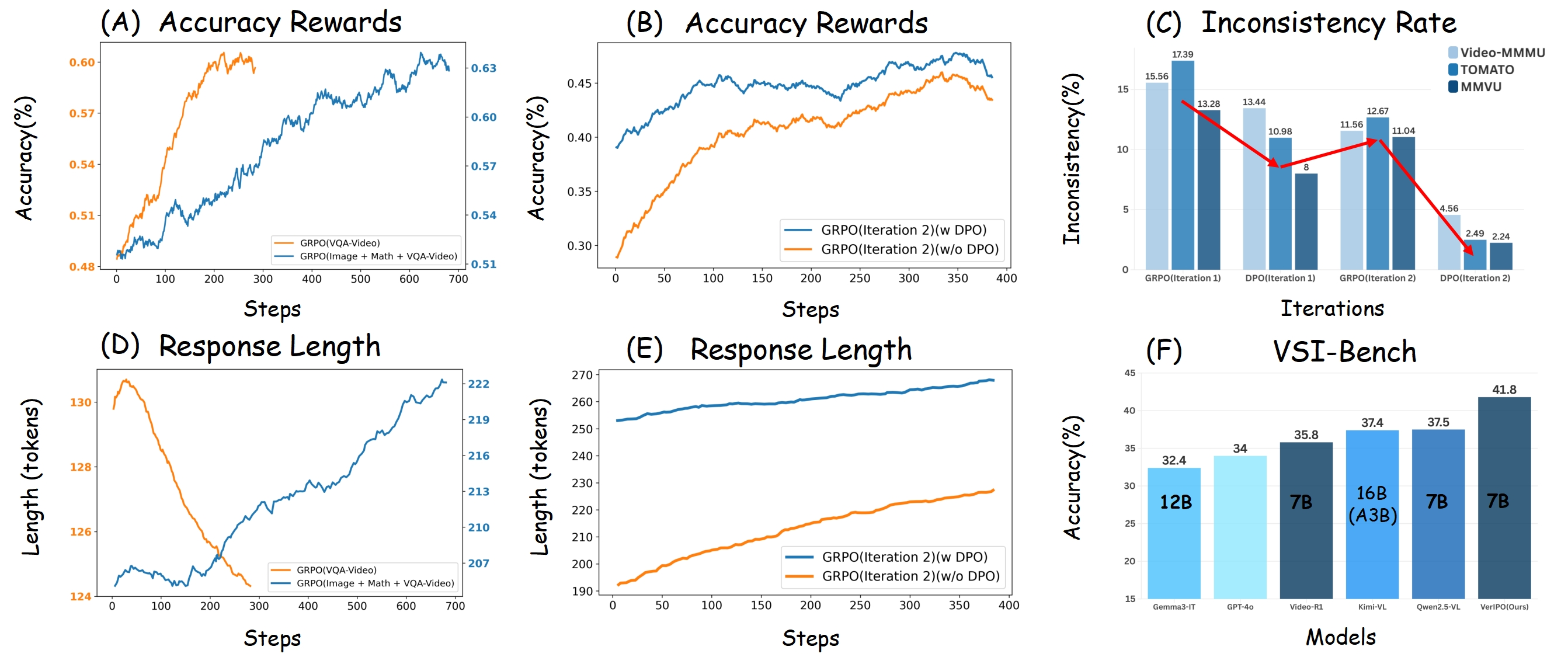
- Existing RL methods like GRPO (Group Relative Policy Optimization) are unstable and can encourage 'correct answers based on wrong thinking' (hallucinated reasoning).
- Online RL training is computationally expensive and does not guarantee a stable increase in reasoning depth or chain length.
- Manual annotation of long Chain-of-Thought data for video is prohibitively expensive and difficult to scale.
Concrete Example:
A Video-LLM might correctly answer 'The man is running' but the reasoning chain claims 'The man is sitting on a chair', showing disjointed logic. VerIPO's verifier detects this inconsistency and uses it as a negative sample.
Key Novelty
GRPO-Verifier-DPO Iterative Loop
- Iterates between exploration (GRPO), curation (Verifier), and exploitation (DPO) to gradually cultivate long reasoning capabilities.
- Introduces a **Rollout-Aware Verifier** that filters GRPO outputs based on accuracy, consistency, repetition, and length to construct high-quality contrastive data.
- Uses 'Reflective Preference Pairs' where the model is taught to prefer self-corrected reasoning over initial incorrect attempts, simulating reflection.
Architecture
Conceptual flow of the VerIPO training loop: GRPO -> Rollout-Aware Verifier -> DPO.
Evaluation Highlights
- Achieves 7x faster optimization speed compared to standard GRPO by leveraging efficient DPO updates on curated data.
- Outperforms RL-trained reasoning models (Video-R1, Kimi-VL-Thinking) and direct-answer models (Qwen2.5-VL-7B) on benchmarks like VSI-Bench and Video-MME.
- Produces consistently longer and more contextually consistent Chain-of-Thoughts compared to baselines initiated with static long-CoT datasets.
Breakthrough Assessment
7/10
Addresses the stability and quality issues of RL for reasoning in multimodal models with a practical iterative pipeline. While improvements are qualitative or relative in the provided text, the methodology for self-training reasoning is sound.