📊 Experiments & Results
Evaluation Setup
Mathematical reasoning on standard and olympiad-level problems
Benchmarks:
- MATH500 (Standard Mathematics)
- OmniMath (Olympiad-Level Math)
- AIME 2024/2025 (Olympiad-Level Math)
- GPQA-Diamond (Scientific Reasoning)
Metrics:
- Pass@1 (Accuracy)
- Pass@32 (for small datasets)
- Tok (Average tokens generated per solution)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| TreeAdv consistently improves accuracy while reducing generation length compared to the GRPO baseline. | ||||
| Average (Olympiad Suite) | Accuracy (%) | 60.55 | 61.99 | +1.44 |
| Average (Olympiad Suite) | Tok (Output Length) | 15693 | 12073 | -3620 |
| OlymH | Accuracy (%) | 23 | 27 | +4 |
| MATH500 | Accuracy (%) | 82.2 | 82.6 | +0.4 |
Experiment Figures
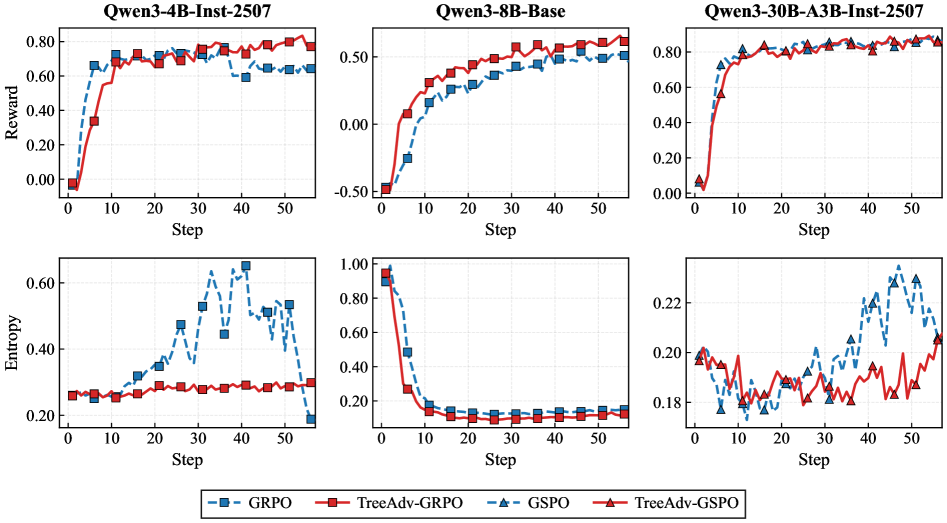
Training dynamics (Reward and Entropy) over steps for TreeAdv vs GRPO/GSPO
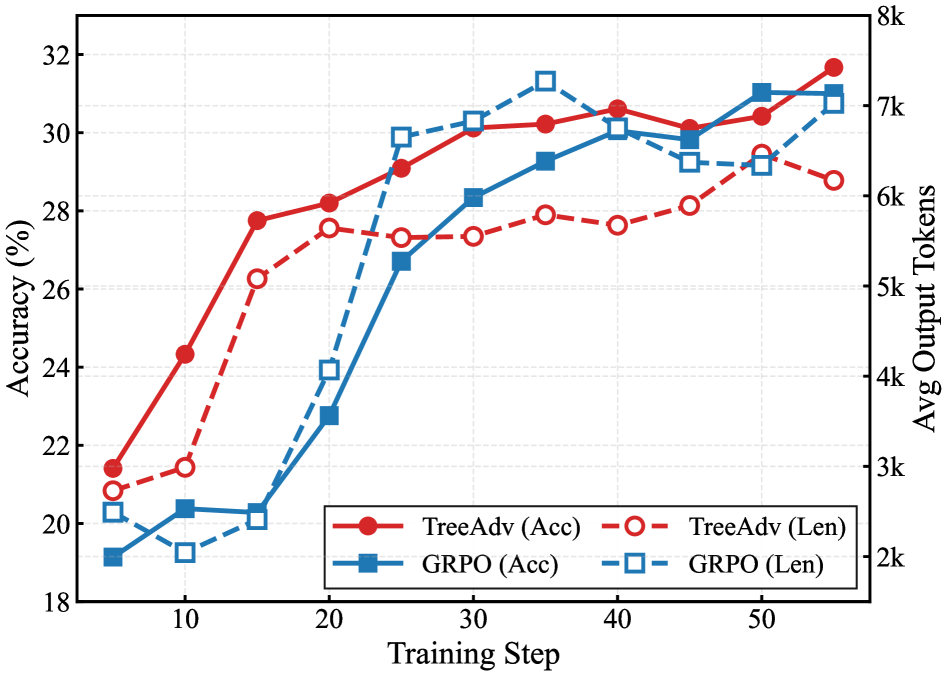
Joint plot of Pass@1 Accuracy and Average Output Length over training steps
Main Takeaways
- TreeAdv shifts the accuracy-efficiency frontier: it achieves higher accuracy with significantly fewer tokens than baselines
- Entropy-guided branching effectively identifies critical decision points, allowing the model to focus exploration where it matters
- Token-level advantages reduce variance in optimization, leading to smoother entropy curves and more stable training
- The method is effective across different model scales (4B to 30B MoE) and baselines (GRPO and GSPO)