📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning Alignment
SAGE prevents RL training collapse under sparse rewards by injecting self-generated hints to diversify rollout outcomes, ensuring valid gradient signals for hard prompts.
Core Problem
Under sparse rewards, Group Relative Policy Optimization (GRPO) often stalls because all rollouts in a group receive identical zero rewards, causing advantages to collapse and gradients to vanish.
Why it matters:
- Standard RL fine-tuning for reasoning tasks relies on correct final answers; without them, models cannot learn from hard prompts
- Existing solutions like discarding degenerate groups bias training toward easy prompts, limiting generalization
- External guidance (distillation) requires stronger teacher models, which may not be available or scalable
Concrete Example:
For a difficult math problem, a model might generate 16 incorrect solutions, all receiving a reward of 0. In GRPO, the advantage (reward - mean) becomes 0 for everyone, resulting in no policy update. SAGE provides a 'hint' (e.g., a first step) that helps the model generate at least one correct solution, creating a variance in rewards that drives learning.
Key Novelty
Self-hint Aligned GRPO with Privileged Supervision (SAGE)
- Injects 'privileged hints' (compressed plans from reference solutions) into the prompt during training to artificially boost success rates on hard problems
- Uses a policy-dependent scheduler that only activates hints when the model's rollout group collapses (zero variance), creating an automatic curriculum
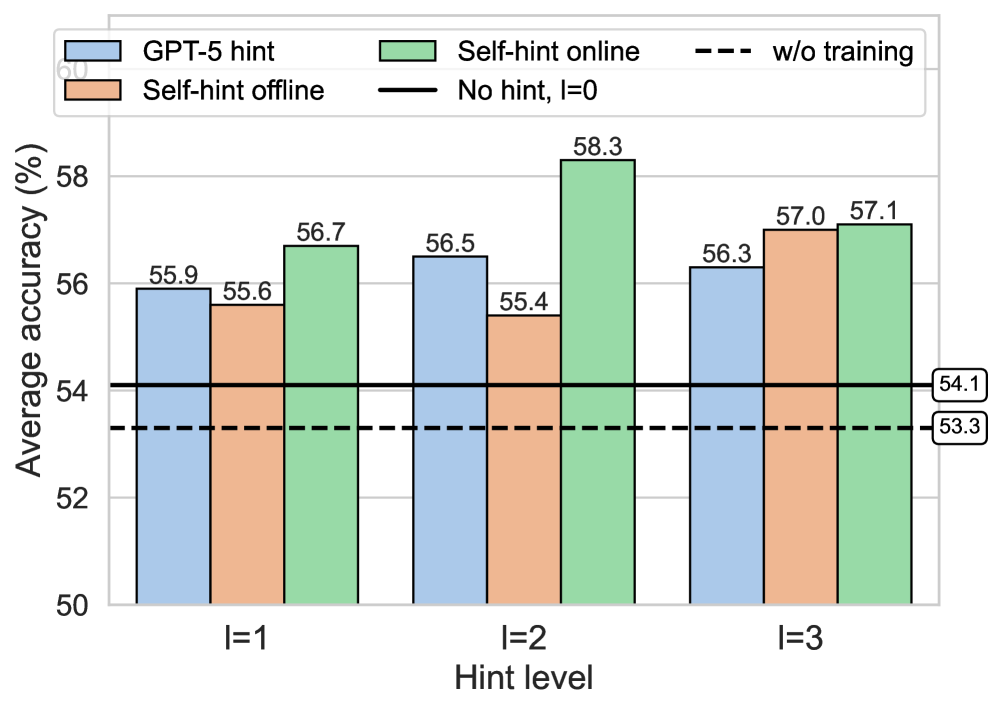
- Refreshes hints online by prompting the current policy to generate plans, ensuring hints remain calibrated to the learner's current capabilities
Architecture
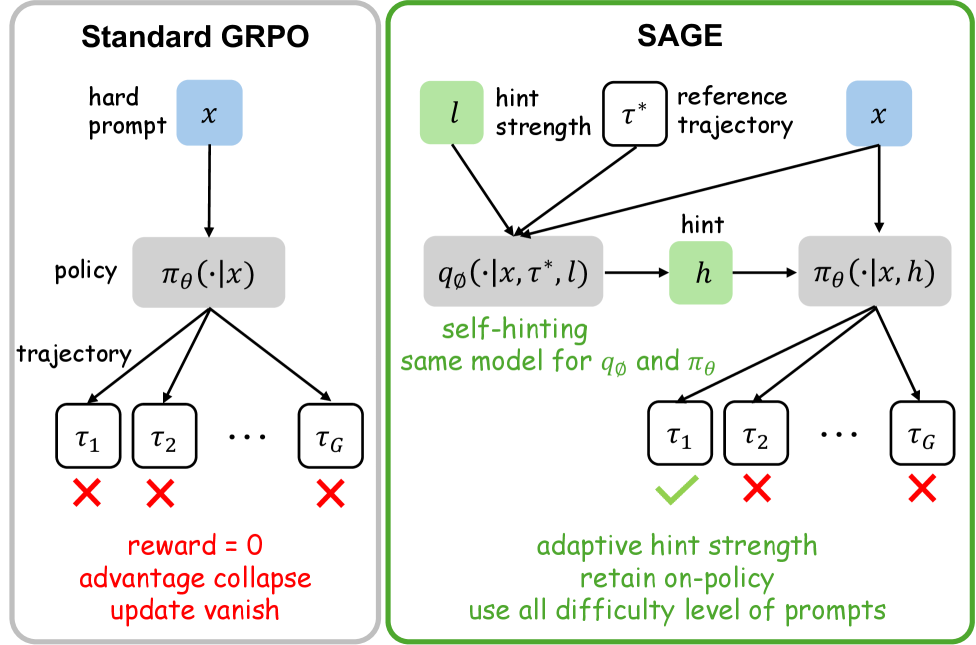
Overview of the SAGE framework contrasting the training and testing phases.
Evaluation Highlights
- +2.0 average accuracy improvement on Llama-3.2-3B-Instruct across 6 benchmarks compared to standard GRPO
- Achieves +6.1 point average gain over Supervised Fine-Tuning (SFT) baseline with Llama-3.2-3B-Instruct
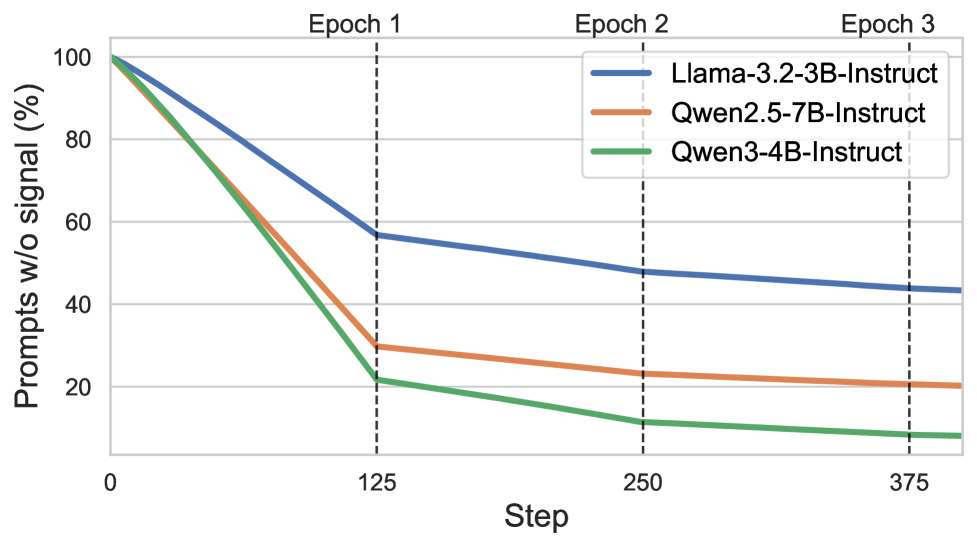
- Effectively utilizes 10% more training prompts than GRPO by recovering learning signals from previously 'dead' (zero-reward) prompts
Breakthrough Assessment
8/10
Addresses a fundamental pathology in sparse-reward RL (gradient collapse) with a simple, elegant mechanism that requires no external supervision at inference time. Significant empirical gains.