📝 Paper Summary
Reinforcement Learning for Reasoning
Reward Modeling
S-GRPO stabilizes reasoning model training by reweighting advantage signals based on group balance to mitigate the impact of false positive rewards where correct answers stem from flawed reasoning.
Core Problem
Standard GRPO assumes correct answers imply correct reasoning, but 'Think-Answer Mismatch' errors (correct answer, wrong logic) introduce reward noise that disproportionately corrupts gradients in unbalanced groups.
Why it matters:
- In highly unbalanced groups (e.g., 1 correct out of 8), a single false positive mismatch can inflate the advantage signal by up to 60%, severely distorting the learning process.
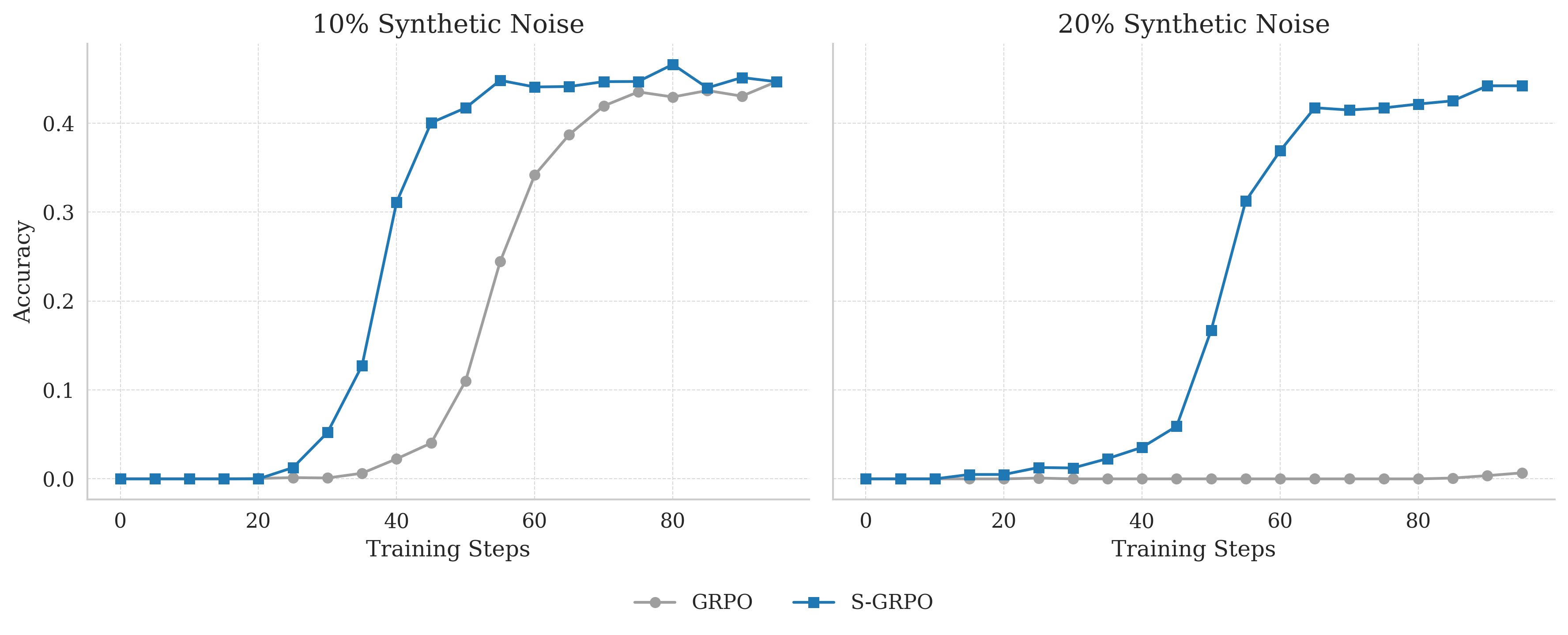
- Standard methods like GRPO collapse entirely under moderate noise levels (e.g., 20% mismatch rate), preventing models from learning robust reasoning patterns.
- Existing heuristics like Dr. GRPO address variance but lack explicit noise modeling, failing to filter out high-risk signals from rare stochastic successes.
Concrete Example:
When solving a math problem, a model might hallucinate gibberish like 'p(n) = n/(n^2-1)' that accidentally evaluates to the correct answer '8/63'. In a group where this is the only 'correct' response, standard GRPO assigns it a massive positive advantage, reinforcing the hallucination. S-GRPO identifies the group as unreliable and gates the update.
Key Novelty
Stable Group-Relative Policy Optimization (S-GRPO)
- Models the Think-Answer Mismatch as symmetric label noise and derives a closed-form optimal weight that minimizes the error between observed and true advantages.
- Introduces a 'Noise-Gating Mechanism' that automatically down-weights or zeros out signals from highly unbalanced groups where the likelihood of noise corruption is highest.
Architecture
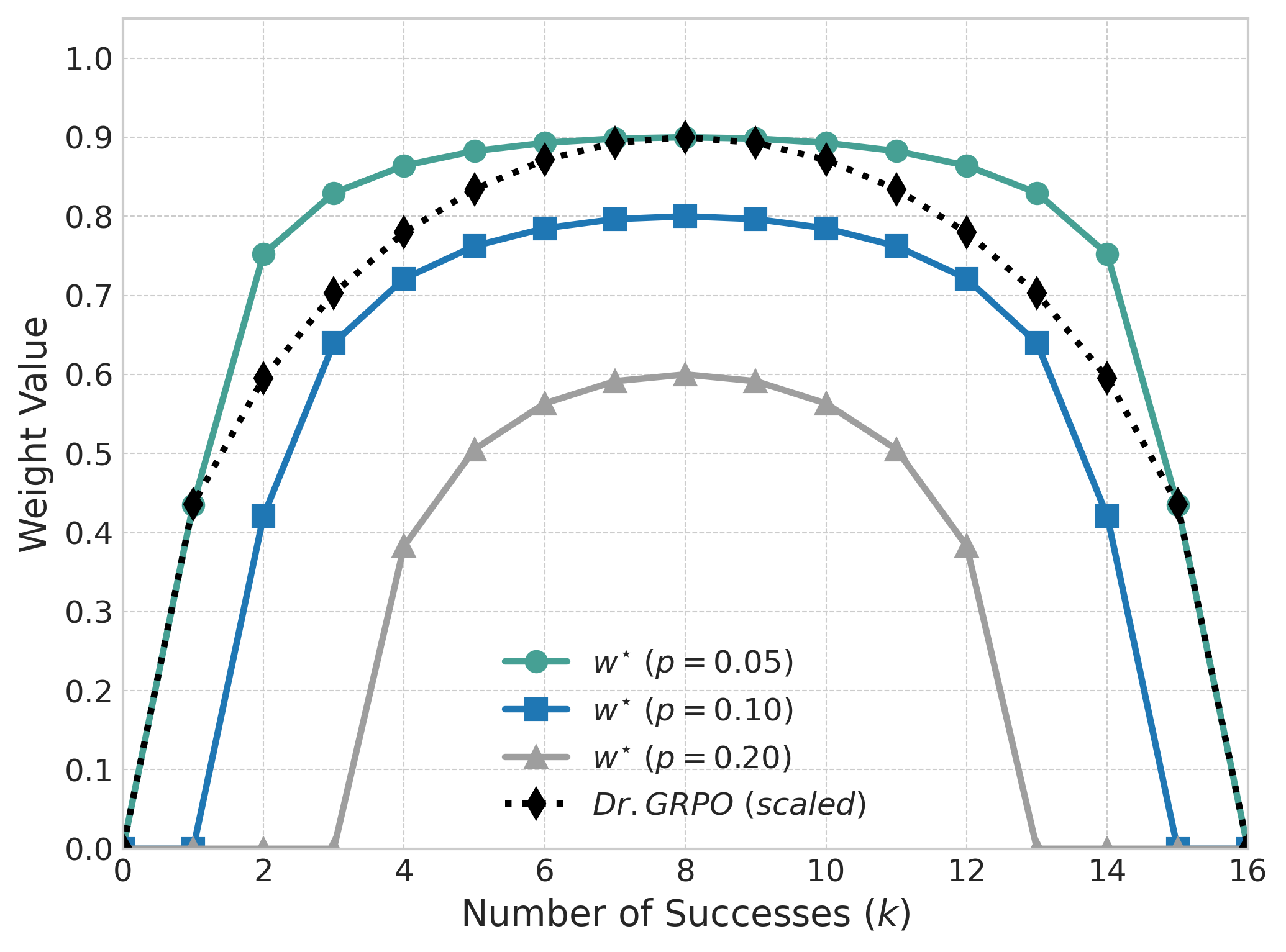
The shape of the optimal advantage weight w* as a function of the number of correct responses k in a group of size N=16, for different noise levels p.
Evaluation Highlights
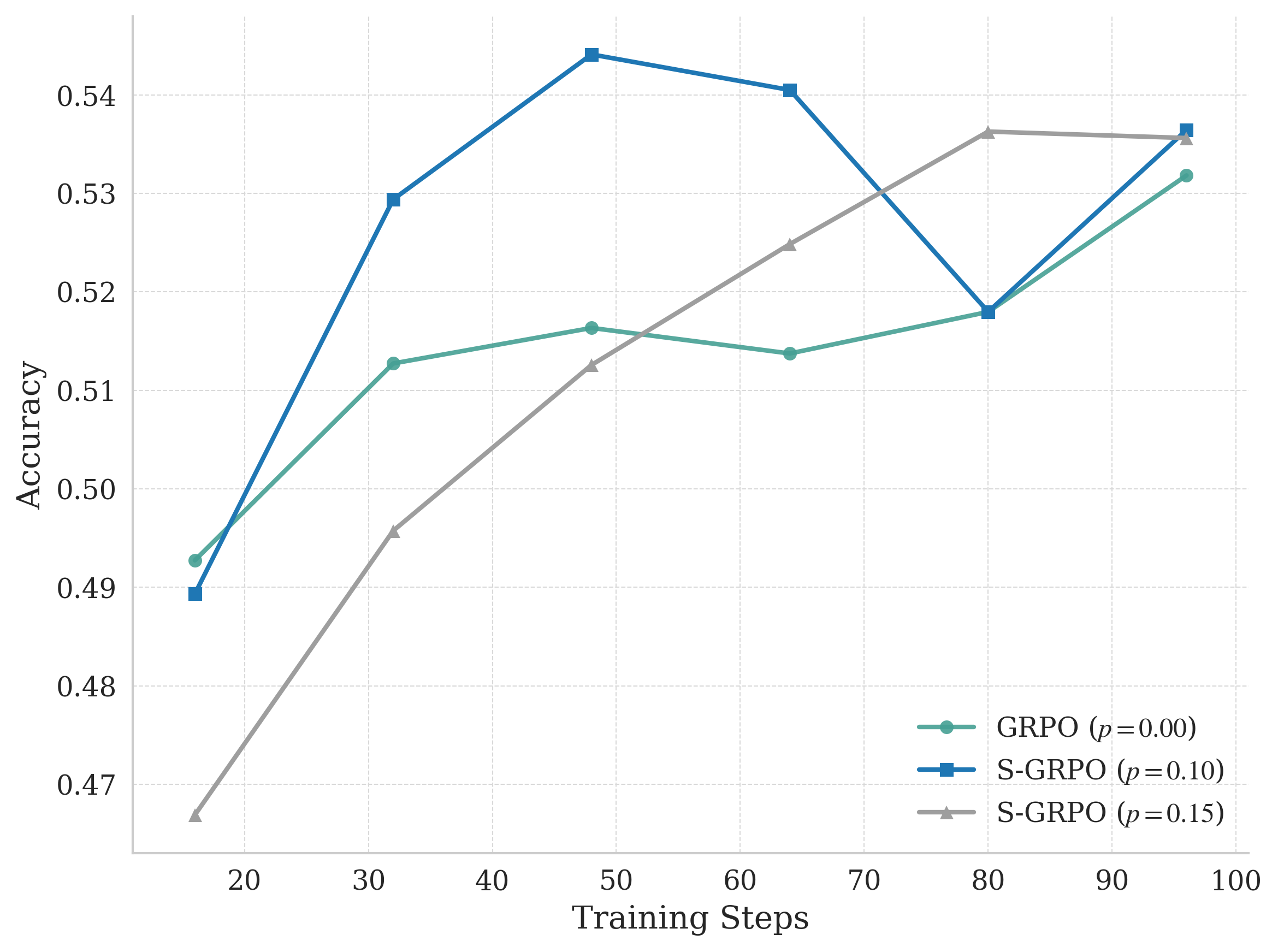
- +2.5% average accuracy gain on Qwen-Math-7B-Base across four math benchmarks (AMC, MATH500, Minerva, OlympiadBench) compared to the strong baseline Dr. GRPO.
- Maintains stable learning progress under 20% synthetic reward noise, whereas standard GRPO suffers complete performance collapse (zero improvement).
- +2.4% average accuracy gain on Qwen-Math-1.5B-Instruct compared to Dr. GRPO, demonstrating effectiveness across different model scales.
Breakthrough Assessment
8/10
Addresses a fundamental flaw in outcome-based reasoning rewards (Think-Answer Mismatch) with a theoretically principled and empirically effective reweighting scheme. Robustness results are particularly strong.