📝 Paper Summary
Reasoning in Large Language Models
Reinforcement Learning from Verifiable Rewards
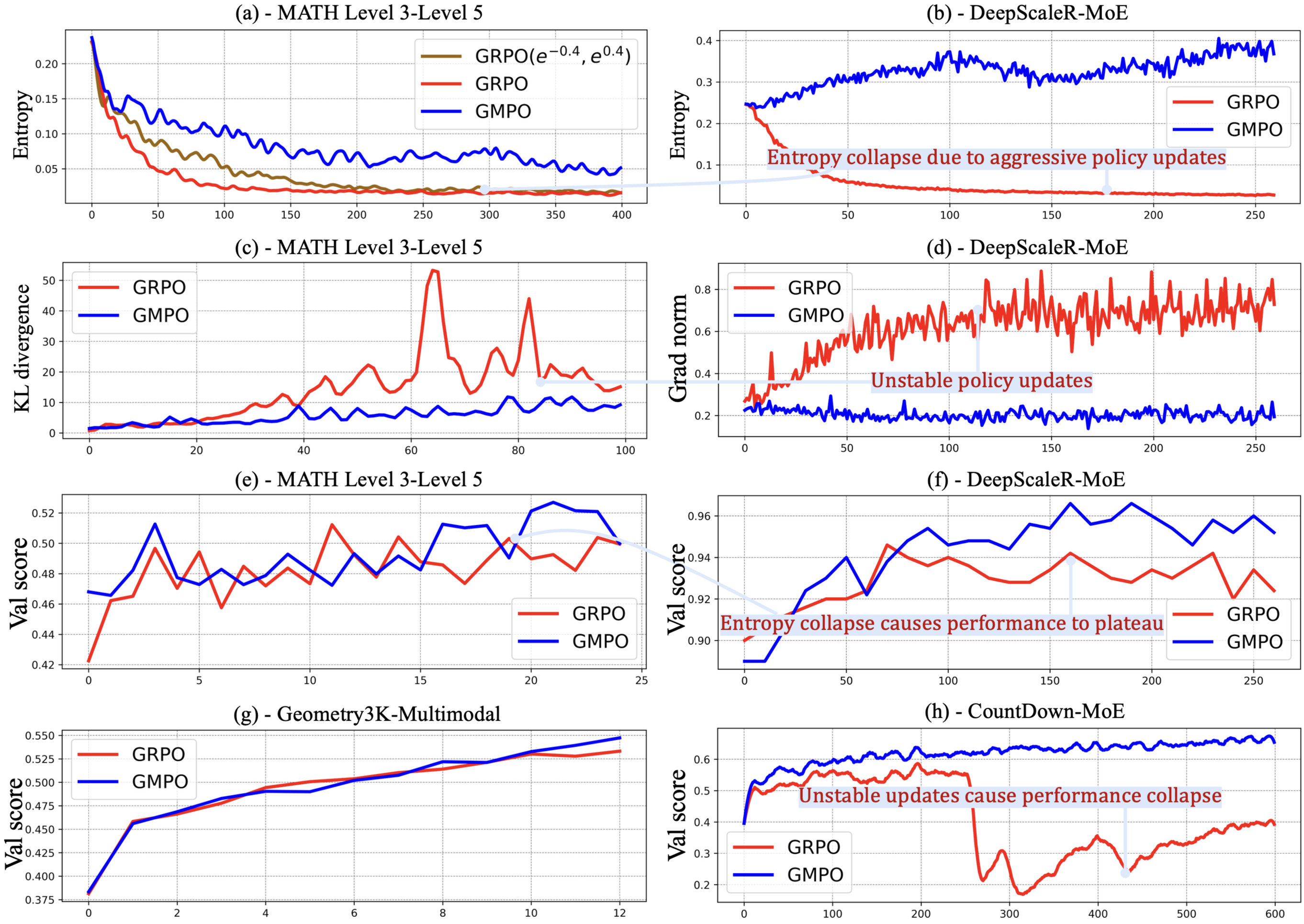
GMPO stabilizes Group Relative Policy Optimization (GRPO) by maximizing the geometric mean of token-level rewards instead of the arithmetic mean, reducing sensitivity to outlier importance sampling ratios.
Core Problem
GRPO suffers from unstable updates because its arithmetic mean objective is sensitive to outlier importance weights, forcing the use of narrow clipping ranges that hinder exploration.
Why it matters:
- Unstable policy updates lead to degraded model performance and training collapse in reasoning tasks
- Narrow clipping ranges (required for stability in GRPO) cause early deterministic policies, limiting the model's ability to explore and self-correct during training
- Current methods struggle to balance the trade-off between training stability and sufficient exploration for scaling reasoning capabilities
Concrete Example:
During training, GRPO often encounters tokens with extreme importance sampling ratios (e.g., far from 1.0). Because GRPO averages these arithmetically, a single outlier can dominate the gradient, causing aggressive updates. To prevent this, GRPO must clip ratios tightly (e.g., 0.8 to 1.2), which stops the model from learning from high-deviation but potentially informative trajectories.
Key Novelty
Geometric-Mean Policy Optimization (GMPO)
- Replaces the arithmetic mean of token-level importance weights with the geometric mean in the optimization objective
- The geometric mean is inherently less sensitive to outliers, naturally suppressing extreme values in the importance sampling ratio distribution
- Allows for a significantly wider clipping range (e^{-0.4}, e^{0.4}) compared to GRPO, enabling greater exploration without sacrificing stability
Architecture

Comparison of GRPO vs. GMPO objectives and their effect on importance sampling ratio stability during training.
Evaluation Highlights
- +4.1% average Pass@1 accuracy over GRPO on five math benchmarks (AIME24, AMC, MATH500, Minerva, OlympiadBench) using DeepSeek-R1-Distill-Qwen-7B
- +2.1% Pass@1 accuracy on MATH500 using a Qwen-32B Mixture-of-Experts model compared to GRPO
- +1.4% Pass@1 accuracy on the Geometry3K multimodal benchmark using Qwen2.5-VL-Instruct-7B
Breakthrough Assessment
8/10
Simple yet theoretically grounded modification to a dominant algorithm (GRPO). Solves a critical stability-exploration trade-off and shows consistent gains across diverse models and tasks.