📝 Paper Summary
Reinforcement Learning for LLM Reasoning
Policy Gradient Methods
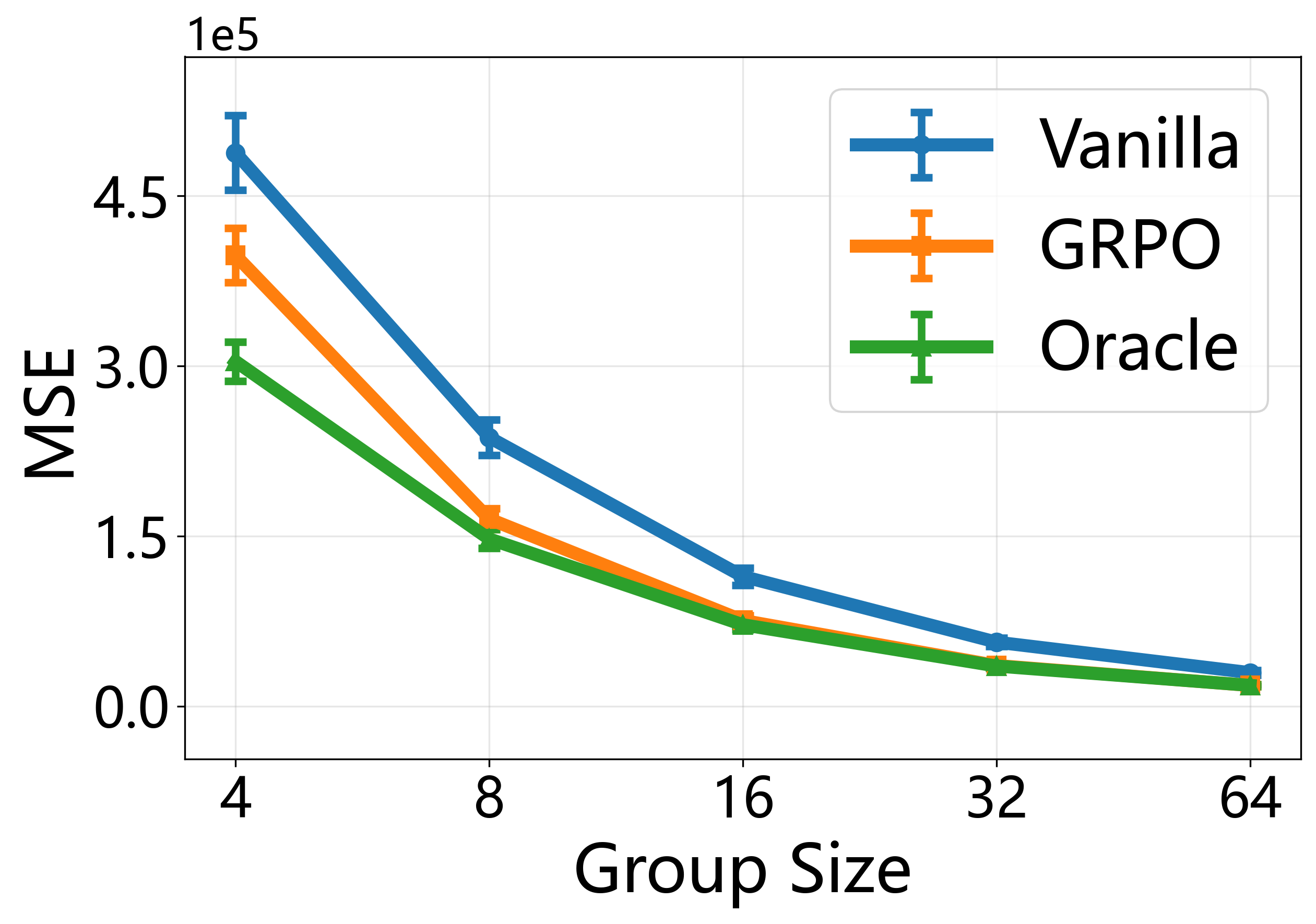
The paper proves that the Group Relative Policy Optimization (GRPO) gradient is a U-statistic, establishing its asymptotic equivalence to an oracle policy gradient and deriving a universal scaling law for optimal group size.
Core Problem
Despite GRPO's success in scaling LLM reasoning (e.g., DeepSeek-R1), its theoretical properties are unstudied: it lacks convergence guarantees, a rationale for using group means as critic proxies, and guidance on selecting group size.
Why it matters:
- GRPO is a foundational algorithm for state-of-the-art reasoning models like DeepSeek-R1, yet its effectiveness was empirically observed rather than theoretically understood
- Standard PPO requires training a separate critic network, which is computationally expensive for reasoning tasks with long trajectories
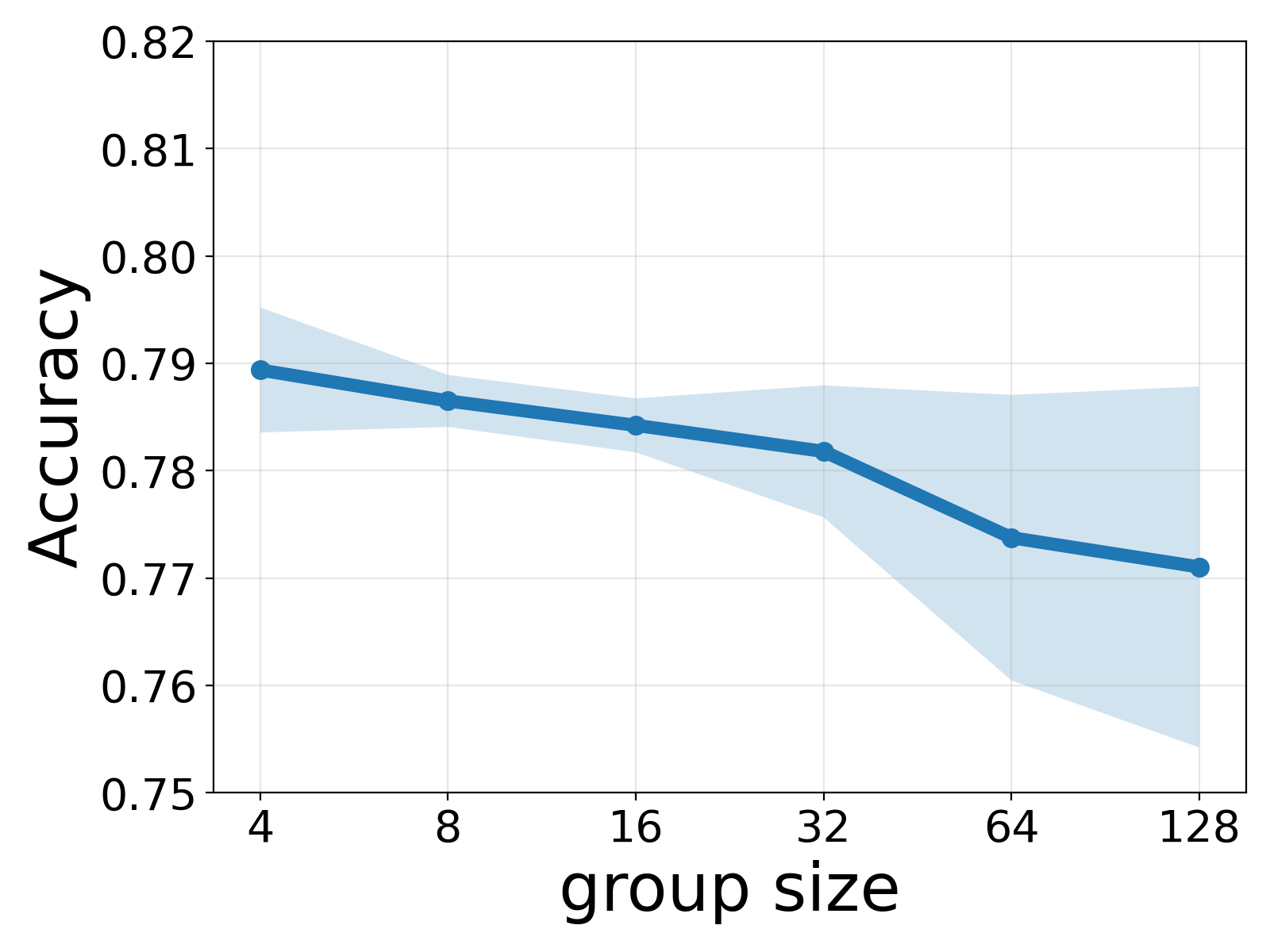
- Practitioners currently lack principled guidance on hyperparameter selection, specifically how many outputs to sample per prompt (group size)
Concrete Example:
In standard PPO, a value network must be trained to estimate the reward of a reasoning step. GRPO bypasses this by sampling a group of outputs (e.g., 4 or 8) and using the group average as a baseline. However, without theory, it is unclear if this average is a valid proxy for the true value function or how the noise from this approximation affects convergence.
Key Novelty
GRPO as a U-Statistic
- Identifies that the GRPO policy gradient estimator mathematical structure is identical to a U-statistic (an average over kernels of multiple variables)
- Leverages Hoeffding decomposition to prove GRPO is asymptotically equivalent to an oracle algorithm that knows the true value function, explaining why it works without a learned critic
- Derives a universal scaling law that predicts the optimal group size based solely on data and architecture, independent of training budget
Architecture
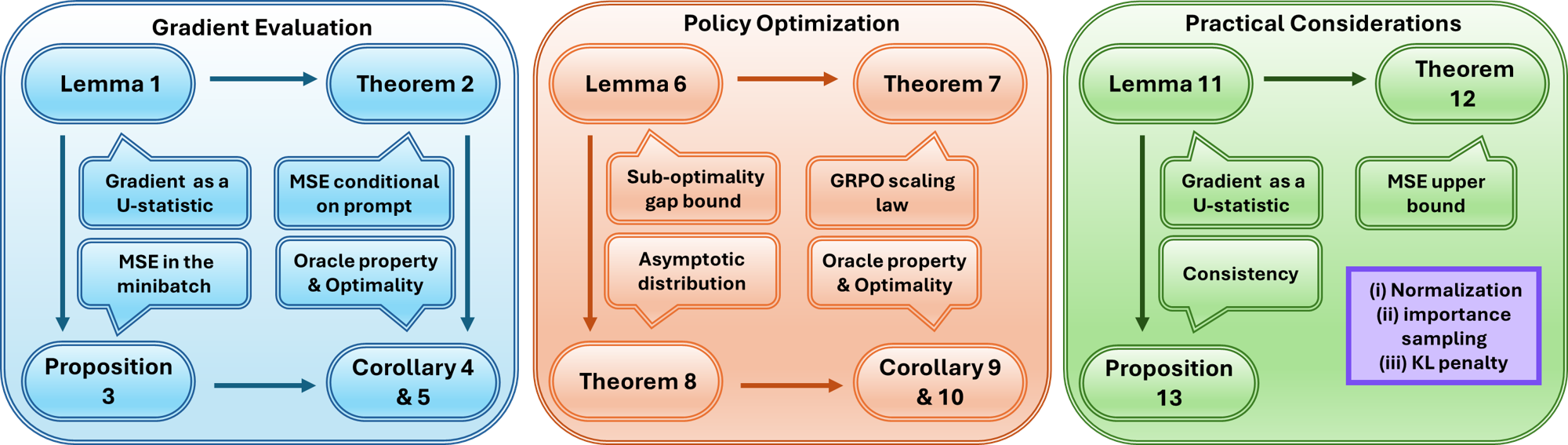
Visualization of the theoretical framework connecting GRPO to U-statistics
Evaluation Highlights
- Theoretical proof that GRPO achieves asymptotically optimal performance (minimum MSE and suboptimality gap) within a broad class of policy gradient algorithms
- Empirical validation of a 'Universal Scaling Law' where the optimal group size matches theoretical predictions across different training budgets
- Demonstration that GRPO's policy gradient MSE converges to that of an oracle method (one with access to the true value function) as sample size increases
Breakthrough Assessment
9/10
Provides the first rigorous theoretical foundation for GRPO, a critical algorithm in modern LLM reasoning. It explains 'why' it works using classical statistics and offers a practical, universal rule for hyperparameter tuning.