📊 Experiments & Results
Evaluation Setup
RLVR on Math, Agentic QA, and Logic Puzzles
Benchmarks:
- OlympiadBench (Mathematical Reasoning)
- AIME 2024 (Mathematical Reasoning)
- VerlTool (HotpotQA, etc.) (Agentic Tool-Use QA)
- K&K Logic Puzzles (Logic Puzzle Solving)
Metrics:
- Accuracy (Greedy)
- Pass@16
- Avg@16 (Mean accuracy across 16 samples)
- Exact Match (EM)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Results on mathematical reasoning benchmarks show consistent improvement over GRPO, particularly on harder tasks like AIME. | ||||
| AIME 2024 | Avg@16 | 28.89 | 43.33 | +14.44 |
| OlympiadBench | Accuracy | 36.50 | 38.48 | +1.98 |
| MATH-500 | Accuracy | 74.67 | 79.40 | +4.73 |
| Agentic reasoning tasks show the largest relative gains, suggesting sharpness control helps significantly in tool-use/multi-hop settings. | ||||
| HotpotQA (VerlTool) | Exact Match | 14.50 | 24.50 | +10.00 |
| Agentic QA (Average) | Exact Match | 13.84 | 27.29 | +13.45 |
| Logic puzzles show that GRPO-SG prevents collapse where standard GRPO fails on complex reasoning chains. | ||||
| K&K Logic Puzzles | Average Accuracy | 0.39 | 0.63 | +0.24 |
| K&K Logic Puzzles | Average Accuracy | 0.77 | 0.91 | +0.14 |
Experiment Figures
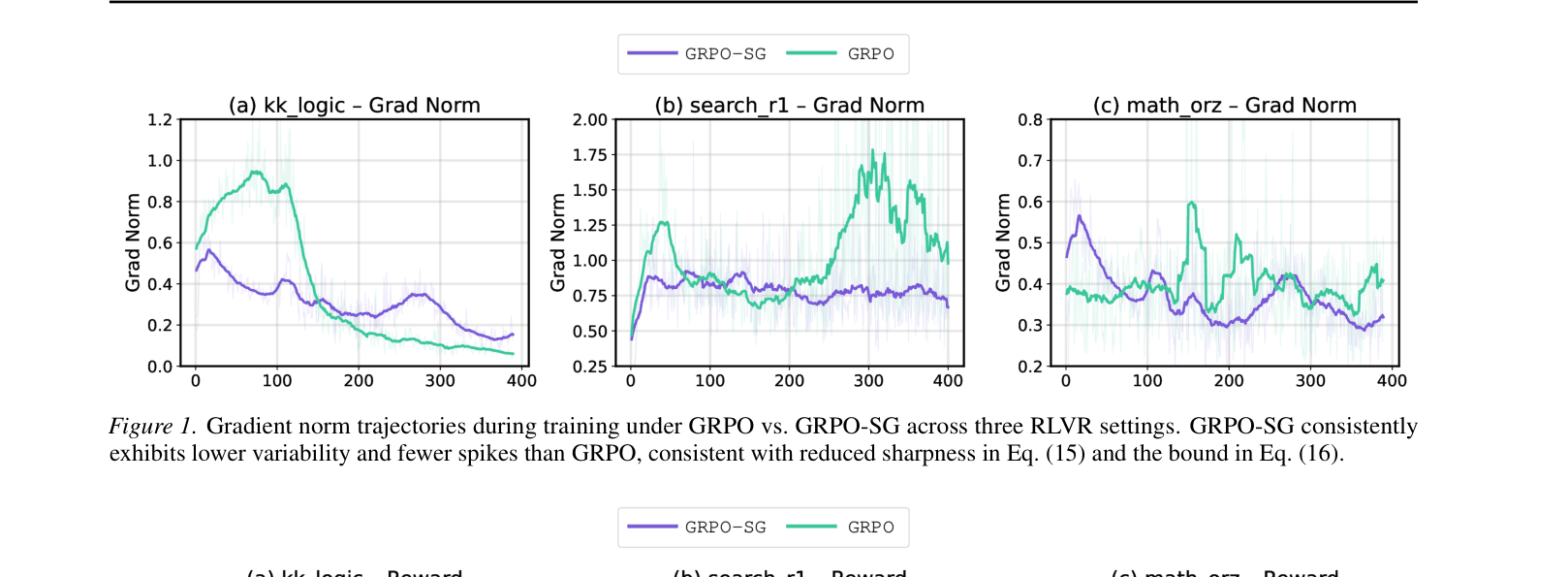
Gradient norm trajectories during training for GRPO vs GRPO-SG across three settings.
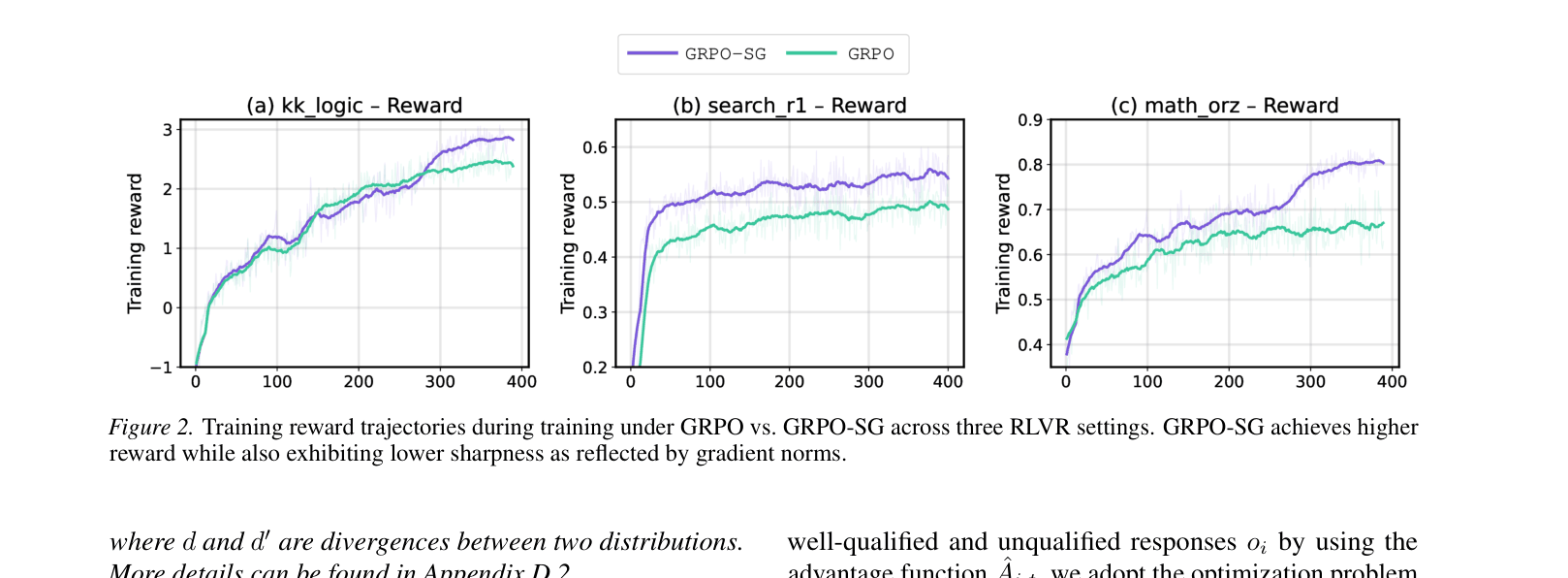
Training reward trajectories for GRPO vs GRPO-SG.
Main Takeaways
- GRPO-SG consistently outperforms standard GRPO across Math, Logic, and Agentic domains, with gains ranging from +6% to +97%.
- Gradient norm analysis (Figure 1) confirms GRPO-SG results in smoother trajectories and fewer outlier spikes, validating the sharpness reduction hypothesis.
- The method is particularly effective in 'Agentic' and 'Logic' settings where reasoning chains are fragile and sharp updates can easily derail the policy.
- Computational overhead is minimal (weights derived from existing probabilities), making it a practical drop-in replacement for GRPO.