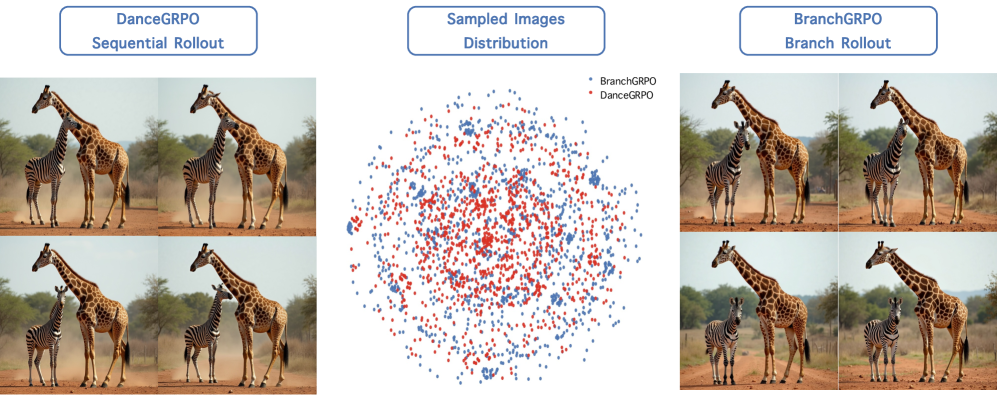
📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF) for Vision
Diffusion Model Alignment
BranchGRPO improves diffusion model alignment by replacing sequential rollouts with a branching tree structure that shares prefixes to reduce computation and provides dense, step-level advantages from sparse terminal rewards.
Core Problem
Existing Group Relative Policy Optimization (GRPO) methods for diffusion are inefficient due to independent sequential rollouts (O(N*T) complexity) and suffer from unstable credit assignment because they propagate a single sparse terminal reward uniformly across all denoising steps.
Why it matters:
- Inefficient rollouts severely limit the scalability of RLHF for large-scale image and video generation models.
- Uniform reward propagation fails to identify which specific denoising steps caused a high-quality or low-quality outcome, leading to high-variance gradients.
- Current methods like DanceGRPO struggle with stability and require excessive computational resources to achieve convergence.
Concrete Example:
In standard GRPO, if a generated image has a deformed hand (bad reward), the negative feedback is applied equally to all 50 denoising steps, even though the early structural steps might have been correct and only the later refinement steps failed.
Key Novelty
Tree-Structured Branching Rollouts for Diffusion RL
- Replaces independent trajectories with a tree where paths split at specific timesteps, allowing multiple outcomes to share the computational cost of early denoising steps (shared prefixes).
- Introduces depth-wise advantage estimation that aggregates rewards from leaf nodes back up the tree, converting a single terminal score into dense, step-specific signals for every transition.
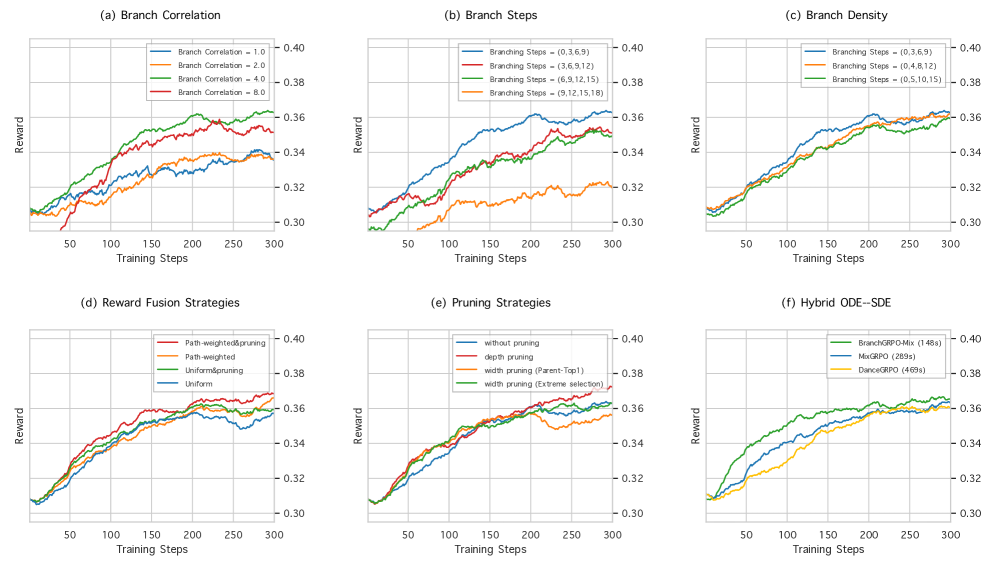
- Applies width and depth pruning to selectively discard low-value branches or skip gradient computation at certain depths, reducing training overhead without harming exploration.
Architecture
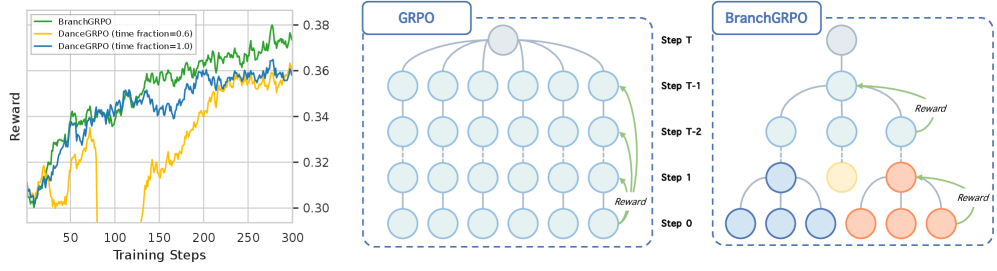
Comparison of Standard Sequential Rollout vs. Branching Rollout structure and the associated reward propagation flow.
Evaluation Highlights
- Improves HPS-v2.1 alignment scores by up to 16% over DanceGRPO while reducing per-iteration training time by nearly 55%.
- BranchGRPO-Mix variant accelerates training to 4.7x faster than DanceGRPO without degrading alignment quality.
- Achieves higher motion quality and temporal consistency on WanX video generation compared to standard baselines.
Breakthrough Assessment
8/10
Significantly addresses the two biggest bottlenecks in diffusion RLHF (efficiency and credit assignment) with a theoretically sound tree-structured approach. Large speedups (4.7x) make it highly practical.