📝 Paper Summary
Online Reinforcement Learning for LLMs
Reasoning Tasks (Math)
MC-GRPO stabilizes reinforcement learning with small rollout budgets by using a median-centered baseline instead of a mean-centered one, preventing outlier-induced advantage sign flips.
Core Problem
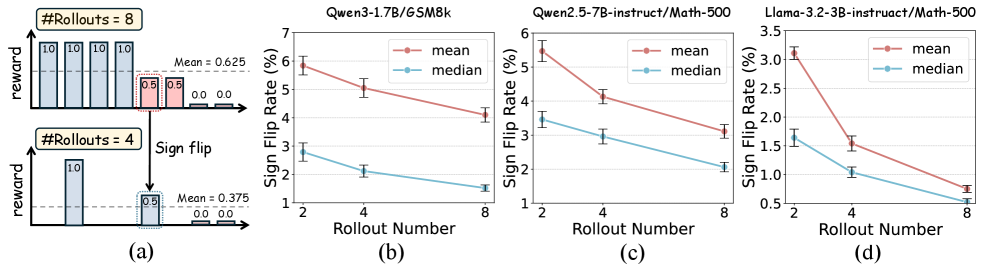
In Group Relative Policy Optimization (GRPO), using a small number of rollouts (e.g., 2-4) makes the shared mean baseline noisy and sensitive to outliers.
Why it matters:
- Resource-constrained settings (academic labs, limited GPUs) cannot afford the high rollout counts (8-32) required for stable GRPO training
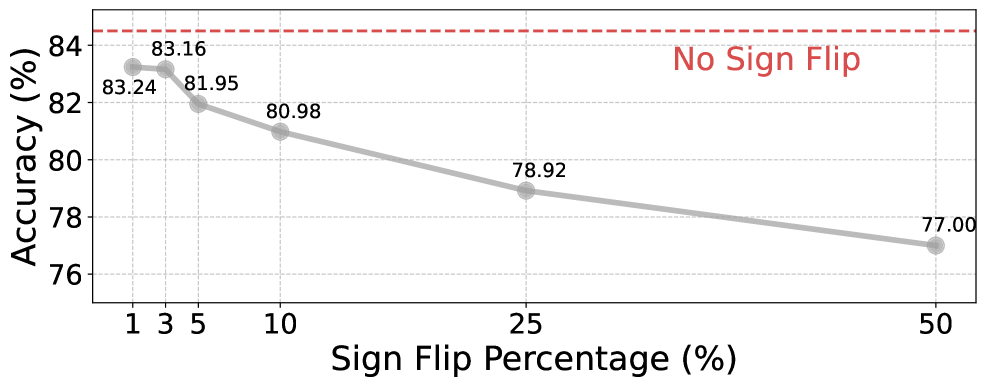
- Noisy baselines cause 'advantage sign flips', where good completions are penalized and bad ones rewarded, reversing the optimization direction and degrading final accuracy
Concrete Example:
With a budget of 4 rollouts, a single high-reward outlier shifts the group mean so much that a completion with positive reward might end up below the mean, receiving a negative advantage. In an 8-rollout setting, that same completion would have correctly received a positive advantage.
Key Novelty
Median-Centered Advantage Estimation
- Replace the mean baseline with the median, which is robust to outliers, ensuring stable advantage signs even with few samples
- Sample one extra rollout (G+1) to form an odd-sized group, use the median as the baseline, and exclude the median sample (which has zero advantage) from the gradient update to preserve the exact compute cost of standard G-rollout training
Architecture
Pseudocode for the MC-GRPO algorithm
Evaluation Highlights
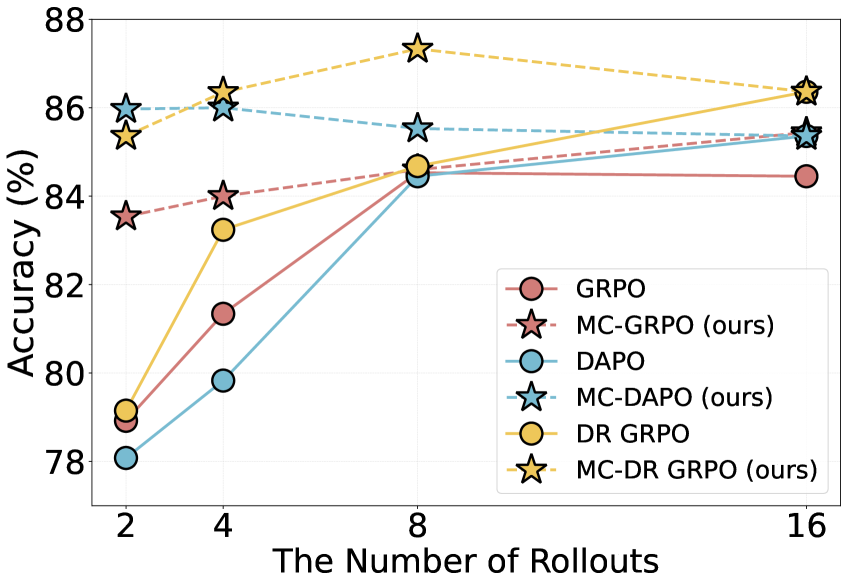
- +4.62% accuracy improvement on GSM8K using Qwen3-1.7B with only 2 rollouts compared to standard GRPO
- Reduces the performance gap between 2-rollout and 8-rollout training to within 1% across various models
- Consistent gains on out-of-distribution math competitions (AIME 2024, AMC 2023) when trained on Math-500
Breakthrough Assessment
8/10
Simple, mathematically grounded fix for a specific but prevalent failure mode in resource-constrained RL. The method is algorithm-agnostic and yields significant gains at low compute.