📝 Paper Summary
Text-to-Image Generation
Reinforcement Learning for Generative Models
Flow Matching
Flow-GRPO adapts online reinforcement learning to deterministic flow matching models by converting the sampling process to a stochastic differential equation and using denoising reduction for efficient training.
Core Problem
Applying online RL to flow matching models is difficult because their deterministic ODE sampling prevents the stochastic exploration required by RL, and their multi-step generation makes data collection computationally expensive.
Why it matters:
- Flow matching models (like Stable Diffusion 3) are state-of-the-art but struggle with complex compositional prompts (counting, spatial relations) and text rendering.
- Existing RL methods for generative models focus on diffusion or offline techniques (DPO), leaving the potential of online RL for flow matching largely unexplored.
- Standard online RL would require full inference steps for every training sample, making it prohibitively slow for large text-to-image models.
Concrete Example:
When prompted with 'a photo of three red apples and two green pears', a standard flow model might generate an incorrect number of fruits or mix up colors because it cannot easily 'explore' to find the correct configuration during training. Flow-GRPO enables this exploration.
Key Novelty
Flow-GRPO (Group Relative Policy Optimization for Flow Matching)
- Converts the deterministic Ordinary Differential Equation (ODE) sampler of flow models into a Stochastic Differential Equation (SDE) that preserves the marginal distribution, injecting the randomness needed for RL exploration.
- Introduces Denoising Reduction, a strategy that uses very few steps (e.g., 10) for training data collection while keeping full steps (e.g., 40) for inference, drastically speeding up training without hurting final quality.
Architecture
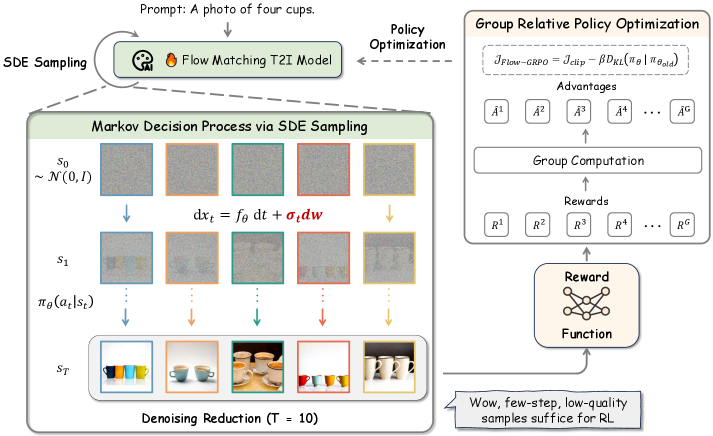
Overview of the Flow-GRPO framework showing the transition from ODE to SDE and the GRPO update loop.
Evaluation Highlights
- Improves Stable Diffusion 3.5 Medium (SD3.5-M) accuracy on GenEval (compositional generation) from 63% to 95%, outperforming GPT-4o.
- Increases accuracy on visual text rendering task from 59% to 92%.
- Achieves a +4x training speedup by reducing data collection steps from 40 to 10 without sacrificing final reward performance.
Breakthrough Assessment
9/10
First successful application of online GRPO to flow matching models. Solves the fundamental deterministic vs. stochastic conflict and the efficiency bottleneck, yielding massive gains (30%+) on hard compositional tasks.
