📝 Paper Summary
Clinical Foundation Models
Multimodal Large Language Models (MLLMs)
QoQ-Med is a generalist clinical model that integrates 1D, 2D, and 3D medical data using a novel reinforcement learning objective (DRPO) to balance performance across rare and difficult clinical domains.
Core Problem
Existing clinical multimodal models often fail to generalize across diverse specialties because abundant data domains (like Chest X-rays) dominate training, while rare domains (like ECGs) are neglected, and most models lack interpretable reasoning traces.
Why it matters:
- Clinical decision-making requires integrating heterogeneous data (ECG, CT, text), but current models struggle to synergize these conflicting modalities
- Black-box diagnostic models impede clinical adoption because healthcare professionals cannot verify the reasoning behind a diagnosis
- Standard training methods like GRPO overfit to easy, abundant samples, leading to poor performance on hard, minority clinical tasks
Concrete Example:
A patient record might include a 1D ECG, a 3D CT scan, and text notes. A standard MLLM might ignore the ECG due to its rarity in training data or provide a diagnosis without pointing to the specific image region (bounding box) that justifies the conclusion.
Key Novelty
Domain-aware Relative Policy Optimization (DRPO)
- Applies a hierarchical scaling mechanism to reinforcement learning rewards: first clustering questions by difficulty within domains, then upweighting updates for rare domains and harder clusters
- Introduces a multimodal architecture that natively integrates 1D time-series (via ECG-JEPA) with 2D/3D vision encoders and text, allowing simultaneous reasoning across all three data types
Architecture
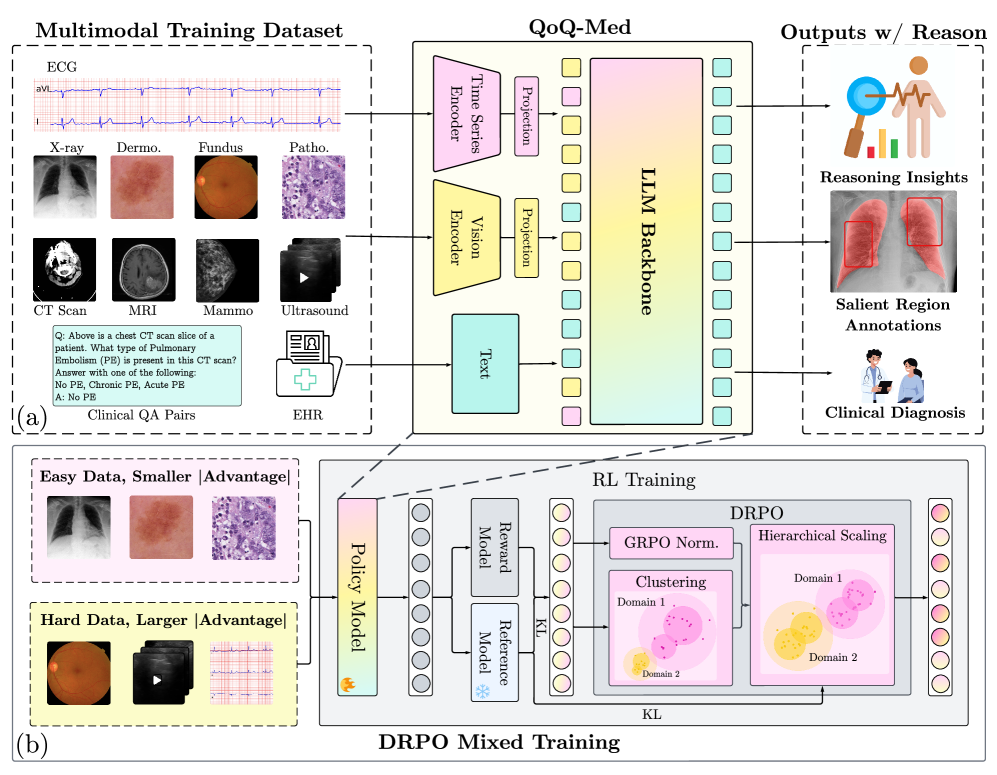
The architecture of QoQ-Med and its inference flow involving multimodal inputs.
Evaluation Highlights
- DRPO training boosts diagnostic performance by 43% in macro-F1 on average across 8 clinical vision modalities compared to standard GRPO
- Achieves an Intersection-over-Union (IoU) score 10x higher than open models for highlighting salient regions, matching the performance of OpenAI o4-mini
- Releases a dataset of 2.61 million instruction tuning pairs with reasoning traces across 9 clinical domains
Breakthrough Assessment
9/10
First open generalist model to integrate 1D time-series with 2D/3D imaging via a novel, theoretically grounded RL method (DRPO) that effectively solves the multi-domain imbalance problem.